Jemný Úvod do Auto-Kodér a Některé Z Jeho Běžných Případů Použití S Python Kód
Pozadí:
Autoencoder je bez dozoru, umělé neuronové sítě, které se učí, jak efektivně komprimovat a kódovat data, pak se učí, jak obnovit data zpět ze snížené kódované reprezentace do reprezentace, která je co nejblíže k původní vstup, jak je to možné.
Autoencoder podle návrhu snižuje rozměry dat tím, že se učí ignorovat šum v datech.
zde je příklad vstupního / výstupního obrazu z datové sady MNIST do autoencoderu.
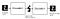
Autoencoder Komponentů:
Autoencoders se skládá ze 4 hlavních částí:
1 – Enkodér: Ve kterém modelu se dozví, jak snížit vstupní rozměry a kompresi vstupních dat do kódované reprezentace.
2-úzký profil: což je vrstva, která obsahuje komprimovanou reprezentaci vstupních dat. Jedná se o nejnižší možné rozměry vstupních dat.
3 – dekodér: ve kterém se model učí, jak rekonstruovat data z kódované reprezentace tak, aby byla co nejblíže původnímu vstupu.
4 – ztráta rekonstrukce: Jedná se o metodu, která měří, jak dobře dekodér funguje a jak blízko je výstup k původnímu vstupu.
trénink pak zahrnuje použití zpětné propagace, aby se minimalizovala ztráta rekonstrukce sítě.
musíte se divit, proč bych trénoval neuronovou síť jen pro výstup obrazu nebo dat, která jsou přesně stejná jako vstup! Tento článek se bude zabývat nejčastějšími případy použití Autoencoderu. Pojďme začít:
Autoencoder Architektura:
síťová architektura pro autoencoders se může lišit mezi jednoduché dopředné neuronové sítě, LSTM sítě nebo Konvoluční Neuronové Sítě v závislosti na případu použití. Některé z těchto architektur prozkoumáme v několika nových řádcích.
existuje mnoho způsobů a technik pro detekci anomálií a odlehlých hodnot. Mám na které se vztahuje toto téma v jiném příspěvku níže:
Nicméně, pokud máte v korelaci vstupních dat, autoencoder metoda bude fungovat velmi dobře, protože kódování operace závisí na korelaci funkce data komprimovat.
řekněme, že jsme vyškolili autoencoder na datovém souboru MNIST. Pomocí jednoduchou Dopřednou neuronovou síť, můžeme dosáhnout tím, že staví jednoduchý 6 vrstev sítě, jak je uvedeno níže:
výstup z kódu výše je:
jak vidíte na výstupu, poslední ztráta/chyba rekonstrukce pro ověřovací sadu je 0.0193, což je skvělé. Teď, když jsem se projít každý normální obrázek z datové sady MNIST, rekonstrukce ztráta bude velmi nízká (< 0.02), ALE když jsem se snažil předat nějaké jiné různé image (outlier nebo anomálie), jsme se získat vysoké rekonstrukci ztráta hodnotu, protože síť se nepodařilo rekonstruovat obraz/vstup, který je považován za anomálii.
Všimněte si, že v kódu výše, můžete použít pouze kodér část komprimovat data nebo obrázky a můžete také použít pouze dekodér část dekomprimovat data načtením dekodér vrstev.
Nyní pojďme udělat nějakou detekci anomálií. Níže uvedený kód používá dva různé obrázky k předpovědi skóre anomálie (chyba rekonstrukce) pomocí sítě autoencoder, kterou jsme vycvičili výše. první obrázek je z MNIST a výsledek je 5.43209. To znamená, že obraz není anomálie. Druhý obrázek, který jsem použil, je zcela náhodný obrázek, který nepatří do tréninkové datové sady a výsledky byly: 6789.4907. Tato vysoká chyba znamená, že obraz je anomálie. Stejný koncept platí pro jakýkoli typ datové sady.