jako datový vědec ve spotřebitelském průmyslu obvykle cítím, že algoritmy pro posílení jsou dostačující pro většinu úkolů prediktivního učení, alespoň teď. Jsou výkonné, flexibilní a lze je pěkně interpretovat pomocí některých triků. Proto si myslím, že je nutné si přečíst některé materiály a napsat něco o zesilujících algoritmech.
Většina obsahu v tomto acticle je založena na papír: Strom Posilování S XGBoost: Proč XGBoost Vyhrát „Každý“ Stroj na Učení Konkurence?. Je to opravdu poučný papír. Téměř vše, co se týká zesilovacích algoritmů, je v příspěvku vysvětleno velmi jasně. Takže papír obsahuje stránky 110: (
pro mě se v podstatě zaměřím na tři nejoblíbenější algoritmy pro posílení: AdaBoost, GBM a XGBoost. Obsah jsem rozdělil na dvě části. První článek (Tento) se zaměří na algoritmus AdaBoost a druhý se zaměří na srovnání mezi GBM a XGBoost.
AdaBoost, zkratka pro „Adaptive Boosting“, je první praktické posílení algoritmus navržené Freund a Schapire v roce 1996. Zaměřuje se na klasifikační problémy a jeho cílem je převést sadu slabých klasifikátorů na silnou. Konečná rovnice pro klasifikaci může být reprezentován jako
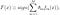
kde f_m stojí za m_th slabý klasifikátor a theta_m je odpovídající váha. Je to přesně vážená kombinace slabých klasifikátorů M. Celý postup algoritmu AdaBoost lze shrnout následovně.
AdaBoost algoritmus
Daný soubor dat obsahující n bodů, kde

Tady -1 označuje negativní třídy, zatímco 1 představuje pozitivní.
Inicializovat váhy pro každý datový bod jako:

Pro iteraci m=1,…,M:
(1) Fit slabých klasifikátorů pro danou datovou sadu a vyberte ten s nejnižším vážené klasifikace chyb:

(2) Výpočet hmotnosti pro m_th slabý klasifikátor:

Pro všechny klasifikátor s přesností vyšší než 50%, v hmotnosti je pozitivní. Čím přesnější je klasifikátor, tím větší je hmotnost. Zatímco u klasifikátoru s přesností menší než 50% je hmotnost záporná. To znamená, že kombinujeme jeho předpověď převrácením znaménka. Například můžeme změnit klasifikátor s přesností 40% na přesnost 60% převrácením znaménka predikce. Takže i klasifikátor má horší výsledky než náhodné hádání, stále přispívá ke konečné predikci. Nechceme pouze Žádný klasifikátor s přesnou 50% přesností, který nepřidává žádné informace a nepřispívá tak k konečné predikci.
(3) Aktualizujte hmotnost pro každý datový bod jako:

kde Z_m je normalizační faktor, který zaručuje, že součet všech instancí vah je rovna 1.
Pokud chybně případě je z pozitivní vážené třídění, „exp“ výraz v čitateli bude vždy větší než 1 (y*f je vždy -1, theta_m je pozitivní). Nesprávně klasifikované případy by tak byly po iteraci aktualizovány s většími váhami. Stejná logika platí pro záporně vážené klasifikátory. Jediným rozdílem je, že původní správné klasifikace by se po překlopení znaménka staly nesprávnými klasifikacemi.
po iteraci M můžeme získat konečnou predikci sečtením vážené predikce každého klasifikátoru.
AdaBoost jako Forward Stagewise Aditivní Model
Tato část je založena na papír: Doplňkové logistické regrese: statistický pohled na posilování. Podrobnější informace naleznete v původním dokumentu.
v roce 2000 Friedman et al. vyvinul statistický pohled na algoritmus AdaBoost. Interpretovali AdaBoost jako postupové odhady pro montáž aditivního logistického regresního modelu. Ty ukázaly, že AdaBoost byl vlastně minimalizaci exponenciální ztrátová funkce

To je minimalizován na

Protože pro AdaBoost, y může být pouze -1 nebo 1, ztráta funkce může být přepsána jako

Pokračovat v řešení pro F(x), dostaneme

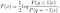
můžeme dále odvodit normální logistický model od optimální řešení F(x):

To je téměř totožný s logistickou regrese model i přes faktor 2.
Předpokládejme, že máme aktuální odhad F(x) a snaží se hledat lepší odhad F(x)+cf(x). Pro pevné c a x, můžeme rozšířit L(y, F(x)+cf(x)) do druhého řádu o f(x)=0,

Tak,

kde E_w(.|x) označuje vážený podmíněné očekávání a váhu pro každý datový bod se vypočítá jako

je-Li c > 0, čímž se minimalizuje vážený podmíněné očekávání se rovná maximalizace

Protože y může být pouze 1 nebo -1, váženého očekávání, může být přepsána jako

optimální řešení přijde jako

Po určení f(x), hmotnost c lze vypočítat přímo minimalizace L(y, F(x)+cf(x)):

Řešení pro c, dostaneme


Nechť epsilon je rovna váženému součtu chybně případech, pak

Všimněte si, že c může být negativní, pokud slabý žák má horší než náhodný odhad (50%), v v takovém případě automaticky změní polaritu.
z hlediska stupně závaží, po zlepšení toho, hmotnosti pro jednu instanci stává,

Tak například hmotnost je aktualizován

ve Srovnání s těmi, které používají v AdaBoost algoritmus,

můžeme vidět, že jsou v totožné podobě. Proto je rozumné interpretovat AdaBoost jako forward stagewise aditivní model s exponenciální ztrátová funkce, které iterativně se hodí slabý klasifikátor zlepšit současný odhad v každé iteraci m:
