Naposledy Aktualizováno 7. srpna 2019
Slovo embeddings jsou typu word reprezentace, která umožňuje slova s podobným významem mít podobné zastoupení.
jedná se o distribuovanou reprezentaci textu, která je možná jedním z klíčových průlomů pro působivý výkon metod hlubokého učení o náročných problémech se zpracováním přirozeného jazyka.
v tomto příspěvku objevíte přístup vkládání slov pro reprezentaci textových dat.
Po dokončení tohoto příspěvku, budete vědět,:
- Co slovo vkládání přístup pro zastupování text a jak se liší od ostatní funkce metody extrakce.
- že existují 3 hlavní algoritmy pro učení vkládání slov z textových dat.
- že můžete buď trénovat nové vkládání, nebo použít předem vyškolené vkládání v úloze zpracování přirozeného jazyka.
nakopněte svůj projekt svou novou knihou hluboké učení pro zpracování přirozeného jazyka, včetně podrobných tutoriálů a souborů zdrojového kódu Pythonu pro všechny příklady.
začněme.

co jsou Word Embeddings pro Text?
fotografie od Heather, některá práva vyhrazena.
- Přehled
- potřebujete pomoc s hlubokým učením textových dat?
- co jsou vkládání slov?
- Slovo Vkládání Algoritmy
- Vkládání Vrstvy
- Word2Vec
- Rukavice
- pomocí Word Embeddings
- Naučte se vkládání
- opětovné použití vkládání
- Kterou Možnost Byste Měli Použít?
- Slovo Vkládání Návody
- Další Čtení
- Články
- papíry
- Projekty
- Knihy
- Shrnutí
- rozvíjejte modely hlubokého učení pro textová Data ještě dnes!
- Vytvořit Vlastní Text modely v Minutách
- konečně přinést hluboké učení do svých projektů zpracování přirozeného jazyka
Přehled
Tento příspěvek je rozdělen do 3 částí, jsou:
- Co Jsou Slova Embeddings?
- algoritmy pro vkládání slov
- pomocí vkládání slov
potřebujete pomoc s hlubokým učením textových dat?
Vezměte si zdarma 7denní e-mailový rychlokurz (s kódem).
kliknutím se zaregistrujete a také získáte zdarma PDF Ebook verzi kurzu.
Začněte svůj bezplatný rychlokurz nyní
co jsou vkládání slov?
vkládání slov je naučená reprezentace textu, kde slova, která mají stejný význam, mají podobnou reprezentaci.
právě tento přístup k reprezentaci slov a dokumentů lze považovat za jeden z klíčových průlomů hlubokého učení o náročných problémech zpracování přirozeného jazyka.
jednou z výhod použití hustých a nízkorozměrných vektorů je výpočetní: většina nástrojů neuronových sítí nehraje dobře s velmi vysokorozměrnými řídkými vektory. … Hlavní prospěch z hustá reprezentace je zobecnění napájení: pokud věříme, že některé funkce mohou poskytovat podobné stopy, je vhodné poskytnout reprezentace, která je schopna zachytit tyto podobnosti.
— Strana 92, metody neuronových sítí ve zpracování přirozeného jazyka, 2017.
word embeddings jsou ve skutečnosti třídou technik, kde jsou jednotlivá slova reprezentována jako vektory s reálnou hodnotou v předdefinovaném vektorovém prostoru. Každé slovo je mapována na jeden vektor, a vektor hodnot, jsou získané způsobem, který se podobá neuronové sítě, a proto tato technika je často soustředěné do oblasti hlubokého učení.
klíčem k přístupu je myšlenka použití husté distribuované reprezentace pro každé slovo.
každé slovo je reprezentováno vektorem s reálnou hodnotou, často desítkami nebo stovkami rozměrů. To je v kontrastu s tisíci nebo miliony dimenzí potřebných pro řídké reprezentace slov, jako je jedno-horké kódování.
přidružit každé slovo ve slovníku distribuované slovo vektor funkce … funkce vektor představuje různé aspekty slova: každé slovo je spojeno s bod ve vektorovém prostoru. Počet funkcí … je mnohem menší než velikost slovní zásoby
— neurální pravděpodobnostní jazykový Model, 2003.
distribuovaná reprezentace se učí na základě použití slov. To umožňuje, aby slova, která se používají podobným způsobem, měla za následek podobné reprezentace, přirozeně zachycující jejich význam. To lze kontrastovat s ostrým, ale křehkým zastoupením v modelu bag of words, kde, pokud není explicitně spravováno, různá slova mají různé reprezentace, bez ohledu na to, jak jsou používána.
za tímto přístupem je hlubší lingvistická teorie, konkrétně „distribuční hypotéza“ Zelliga Harrise, kterou lze shrnout jako: slova, která mají podobný kontext, budou mít podobné významy. Pro více hloubky viz Harris ‚1956 papír “ distribuční struktura“.
Tento pojem nechal použití slova definovat jeho význam lze shrnout tím, že často opakovaný bonmot John Firth:
poznáte slovo, které společnost udržuje!
— Strana 11, „a synopse of linguistic theory 1930-1955“, in Studies in Linguistic Analysis 1930-1955, 1962.
Slovo Vkládání Algoritmy
Slovo vkládání metody naučte se skutečný-oceněný vektorová reprezentace pro předdefinované fixní velikosti slovní zásoby z korpusu textu.
proces učení je společné s modelu neuronové sítě na nějaký úkol, např. klasifikace dokumentů, nebo je bez dozoru proces, pomocí dokumentu statistiky.
tato část popisuje tři techniky, které lze použít k naučení vkládání slov z textových dat.
Vkládání Vrstvy
vkládání vrstvy, pro nedostatek lepší jméno, je slovo, vkládání, co se naučil společně s neuronové sítě model na konkrétní zpracování přirozeného jazyka úkol, jako jazyk modelování a klasifikace dokumentů.
vyžaduje, aby byl text dokumentu vyčištěn a připraven tak, aby každé slovo bylo jedno-horké kódované. Velikost vektorového prostoru je specifikována jako součást modelu, například 50, 100 nebo 300 rozměrů. Vektory jsou inicializovány malými náhodnými čísly. Vkládání vrstva je použit na přední konec neuronové sítě a je vhodný pod dohledem, jak pomocí Backpropagation algoritmu.
… pokud vstup do neuronové sítě obsahuje symbolické kategorické znaky (např. funkce, které přijmout jeden z k různých symbolů, jako jsou slova z uzavřeného slovní zásoba), je běžné, že spojit všechny možné funkce, hodnota (tj. každé slovo ve slovníku) s d-dimenzionální vektor pro nějaké d. Tyto vektory jsou pak považovány za parametry modelu, a jsou vyškoleni, společně s ostatními parametry.
— Strana 49, metody neuronových sítí ve zpracování přirozeného jazyka, 2017.
jedno-horká kódovaná slova jsou mapována na vektory slov. Pokud vícevrstvý Perceptron model je použit, pak slovo vektory jsou spojeny předtím, než je přiváděn jako vstup do modelu. Pokud se používá opakující se neuronová síť, může být každé slovo považováno za jeden vstup v pořadí.
Tento přístup učení vkládání vrstva vyžaduje hodně přípravy dat a může být pomalé, ale dozvíte vkládání i cílené na konkrétní text, data a NLP úkol.
Word2Vec
Word2Vec je statistická metoda pro efektivní učení samostatné slovo vkládání z textového korpusu.
byl vyvinut Tomášem Mikolovem a kol. na Google v roce 2013 jako reakce, aby se neuronová síť-založené školení o vkládání efektivnější a od té doby se stal de facto standardem pro vývoj pre-vyškoleni, slovo vkládání.
dále práce zahrnovala analýzu naučených vektorů a zkoumání vektorové matematiky na reprezentacích slov. Například, že odečtení „muže“ od „krále“ a přidání „ženy“ má za následek slovo „královna“, zachycení analogie „král je královně jako muž je ženě“.
zjistili Jsme, že tyto reprezentace jsou překvapivě dobré na zachycování syntaktické a sémantické zákonitosti v jazyce, a že každý vztah je charakterizován vztah-specifické vektor posun. To umožňuje vektorově orientované uvažování založené na posunech mezi slovy. Například, muž/žena vztah se automaticky naučili, a s indukovanou vektorové reprezentace, „Král – Muž + Žena“ výsledky ve vektorovém velmi blízko k „Královna.“
— lingvistické zákonitosti v souvislých reprezentacích prostorových slov, 2013.
Dva různé modely učení byly zavedeny, které mohou být použity jako součást word2vec přístupu naučit slovo embedding; jsou:
- Kontinuální Bag-of-Slova, nebo CBOW model.
- Souvislý Skip-Gramový Model.
model CBOW se učí vkládání předpovědí aktuálního slova na základě jeho kontextu. Kontinuální skip-gramový model se učí předpovídáním okolních slov daných aktuálním slovem.
kontinuální skip-gramový model se učí předpovídáním okolních slov daných aktuálním slovem.
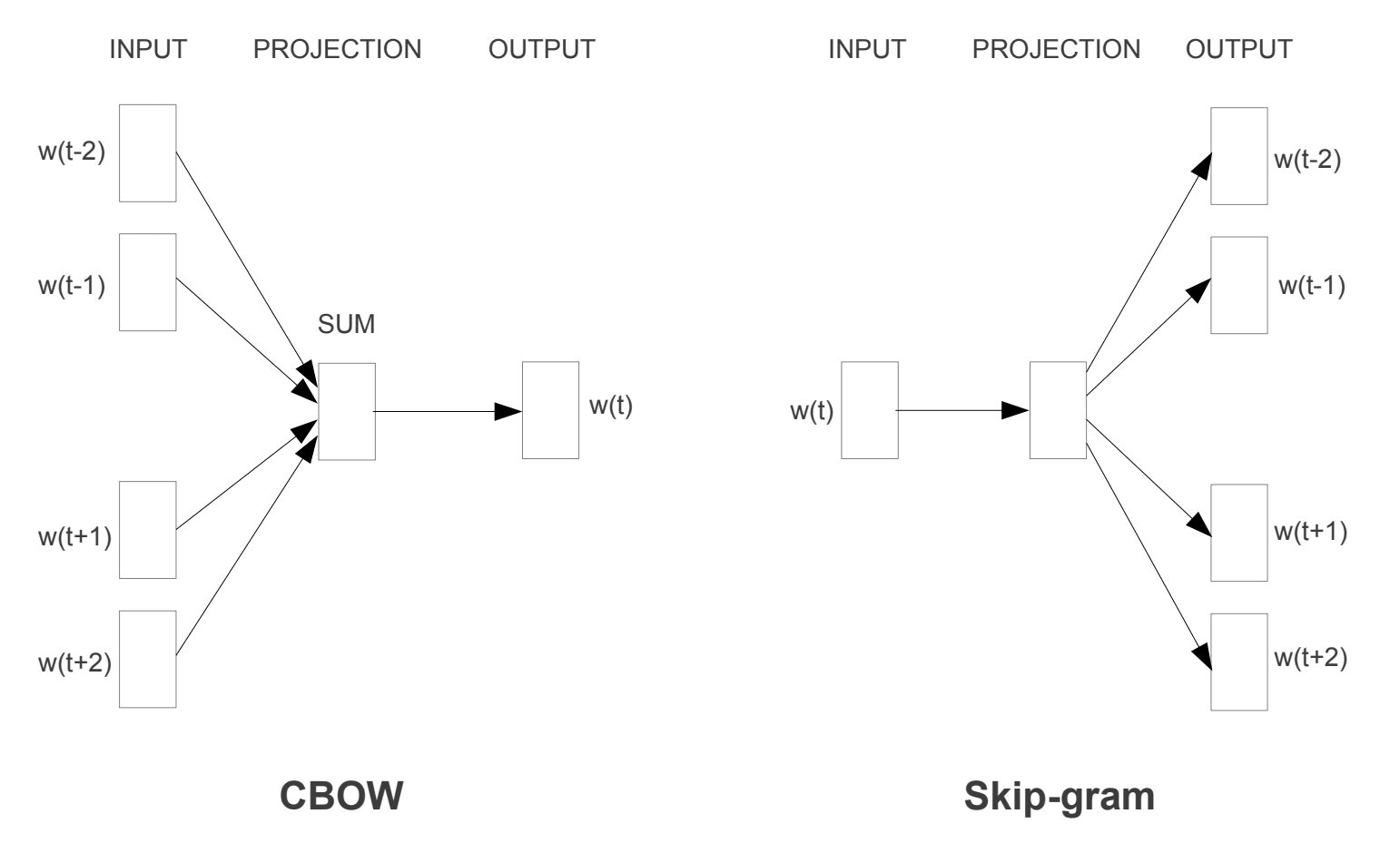
Word2Vec Školení Modely
převzato z „Efektivní Odhad Slovo Reprezentace v Vektorový Prostor“, 2013
Oba modely jsou zaměřeny na poznávání slov s ohledem na jejich místní využití kontextu, kde kontext je definován okno sousední slova. Toto okno je konfigurovatelný parametr modelu.
velikost posuvného okna má silný vliv na výsledné vektorové podobnosti. Velká okna mají tendenci vytvářet aktuálnější podobnosti, zatímco menší okna mají tendenci vytvářet funkčnější a syntaktičtější podobnosti.
— Strana 128, metody neuronových sítí ve zpracování přirozeného jazyka, 2017.
hlavní výhodou tohoto přístupu je, že vysoce kvalitní slovo vnoření se lze naučit efektivně (nízký prostor a čas složitosti), což umožňuje větší vnoření se dozvěděl (více rozměrů) z mnohem větší korpusy textu (miliardy slov).
Rukavice
Globální Vektory pro Slovo Reprezentace, nebo Rukavice, algoritmus je rozšíření pro word2vec metody pro efektivní učení slovní vektorů, vyvinutý Pennington et al. na Stanfordu.
Klasické vector space model reprezentace slov, které byly vyvinuty pomocí maticové faktorizace techniky, jako Latentní Sémantická Analýza (LSA), že dělat dobrou práci pomocí globální textové statistiky ale nejsou tak dobré, jako naučené metody, jako word2vec na zachycení smyslu a demonstrovat to na úkoly, jako je výpočet analogie (např. příklad krále a královny výše).
Rukavice je přístup, aby si oba globální statistiky matrix faktorizace techniky, jako LSA s místní kontext-založené učení v word2vec.
spíše než pomocí okna Definovat místní kontext, GloVe konstruuje explicitní slovo-kontext nebo slovo co-výskyt matice pomocí statistik v celém textovém korpusu. Výsledkem je model učení, který může mít za následek obecně lepší vkládání slov.
GloVe je nový globální log-bilineární regresní model pro bez dozoru učení slovních reprezentací, který překonává jiné modely na úlohách rozpoznávání slov, podobnosti slov a pojmenovaných entit.
— rukavice: Globální vektory pro reprezentaci slov, 2014.
pomocí Word Embeddings
máte některé možnosti, když přijde čas na použití word embeddings na zpracování projektu přirozeného jazyka.
tato část popisuje tyto možnosti.
Naučte se vkládání
můžete se rozhodnout naučit slovo vkládání pro Váš problém.
To bude vyžadovat velké množství textových dat, aby zajistily, že užitečné vnoření se naučil, jako miliony nebo miliardy slova.
máte dvě hlavní možnosti, když školení word vkládání:
- Naučit je Samostatné, kde model je trénoval se učit vkládání, který je uložen a použit jako součást jiného modelu pro váš úkol později. To je dobrý přístup, pokud byste chtěli použít stejné vkládání do více modelů.
- Naučte se společně, kde se vkládání učí jako součást velkého modelu specifického pro daný úkol. To je dobrý přístup, pokud máte v úmyslu použít pouze vkládání na jeden úkol.
opětovné použití vkládání
je běžné, že vědci zpřístupňují předem vyškolené vkládání slov zdarma, často pod tolerantní licencí, abyste je mohli používat na svých vlastních akademických nebo komerčních projektech.
například word2vec a GloVe word embeddings jsou k dispozici ke stažení zdarma.
ty mohou být použity na vašem projektu namísto školení vlastní embeddings od nuly.
máte dvě hlavní možnosti, pokud jde o použití pre-vyškoleni embeddings:
- Statické, kde zapuštění je stále statický a je používán jako součást vašeho modelu. To je vhodný přístup, pokud je vkládání vhodné pro Váš problém a poskytuje dobré výsledky.
- aktualizováno, kde se pro osivo modelu používá předem vyškolené vkládání, ale vkládání se aktualizuje společně během tréninku modelu. To může být dobrá volba, pokud chcete získat co nejvíce z modelu a vložit do svého úkolu.
Kterou Možnost Byste Měli Použít?
Prozkoumejte různé možnosti a pokud je to možné, vyzkoušejte, které poskytují nejlepší výsledky ve vašem problému.
možná začněte rychlými metodami, jako je použití předem vyškoleného vkládání, a nové vkládání použijte pouze tehdy, pokud to má za následek lepší výkon vašeho problému.
Tento oddíl uvádí některé krok-za-krokem tutoriály, které můžete sledovat pomocí aplikace word embeddings a přinést slovo vkládání do projektu.
- Jak Vytvořit Slovo Embeddings v Pythonu s Gensim
- Jak Používat Slovo Vkládání Vrstev pro Hluboké Učení s Keras
- Jak Vytvořit Hluboké CNN pro Sentiment Analýzu (Text Klasifikace)
Další Čtení
Tato část poskytuje více zdrojů na téma pokud hledáte jít hlouběji.
Články
- Slovo vložením na Wikipedii
- Word2vec na Wikipedii
- Rukavice na Wikipedii
- přehled o slovo embeddings a jejich připojení k distribuční sémantické modely 2016.
- hluboké učení, NLP a reprezentace, 2014.
papíry
- distribuční struktura, 1956.
- Neurální Pravděpodobnostní Jazykový Model, 2003.
- a Unified Architecture for Natural Language Processing: Deep Neuron Networks with Multitask Learning, 2008.
- souvislé vesmírné jazykové modely, 2007.
- Efektivní Odhad Slovo Reprezentace v Vektorový Prostor, 2013
- Distribuované Reprezentace Slov a Frází a jejich princip kompozicionality, 2013.
- rukavice: Globální vektory pro reprezentaci slov, 2014.
Projekty
- word2vec na Google Code
- Rukavice: Globální Vektory pro Slovo Reprezentace
Knihy
- Neuronové Sítě Metody ve Zpracování Přirozeného Jazyka, 2017.
Shrnutí
V tomto příspěvku si objevena před Slovo Embeddings jako metoda zastoupení pro text v hluboké učení aplikací.
Konkrétně, jste se naučili:
- Co slovo vkládání přístup pro reprezentaci textu je a jak se liší od ostatní funkce metody extrakce.
- že existují 3 hlavní algoritmy pro učení vkládání slov z textových dat.
- že můžete buď trénovat nové vkládání, nebo použít předem vyškolené vkládání do úlohy zpracování přirozeného jazyka.
máte nějaké dotazy?
zeptejte se na své otázky v komentářích níže a já se budu snažit odpovědět.
rozvíjejte modely hlubokého učení pro textová Data ještě dnes!

Vytvořit Vlastní Text modely v Minutách
…s jen pár řádek python kódu
Zjistit, jak můj nový Ebook:
Hluboké Učení pro Zpracování Přirozeného Jazyka
poskytuje self-studovat návody na témata, jako jsou:
Bag-of-Slova, Slovní Vkládání, Jazykové Modely, Titulek Generace, Překlad Textu a mnohem více…
konečně přinést hluboké učení do svých projektů zpracování přirozeného jazyka
přeskočit akademiky. Jen Výsledky.
podívejte se, co je uvnitř