existuje také řada nesprávných způsobů, jak můžete zahrnout proměnné. Gravitační model nebude fungovat, pokud každá proměnná splňuje následující kritéria:
- Číselné
- Kompletní
- Spolehlivé
Číselné Údaje Pouze
Jako gravitační model je matematická rovnice, všechny vstupní proměnné musí být číselný. To by mohl být počet (populace), územní opatření (plocha, vzdálenost, atd), čas (hodiny od Londýna pěšky), procento (mzdy, zvýšení/snížení), měna hodnota (mzdy šilinků), nebo nějaké jiné opatření na místech zapojených v modelu.
čísla musí být smysluplná a nemohou být nominálními kategorickými proměnnými, které fungují jako záskok pro kvalitativní atribut. Například nemůžete libovolně přiřadit číslo a použít ho v modelu, pokud číslo Nemá význam (např. road quality = dobrý nebo road quality = 4). Ta je sice číselná, ale není měřítkem kvality silnic. Namísto, můžete použít průměrnou rychlost jízdy v mílích za hodinu jako proxy pro kvalitu silnice. Zda je průměrná rychlost smysluplným měřítkem kvality silnic, je na vás, abyste jako autor studie určili a obhájili.
obecně řečeno, pokud ji můžete měřit nebo počítat, můžete ji modelovat.
úplné údaje pouze
pro každý bod zájmu musí existovat všechny kategorie údajů. To znamená, že všechny 32 analyzované kraje musí mít spolehlivá data pro každý faktor push a pull. Nemůžete mít žádné mezery nebo mezery, například v jednom kraji, kde nemáte průměrnou mzdu.
pouze spolehlivá Data
pořekadlo informatiky „garbage in, garbage out“ platí také pro gravitační modely, které jsou stejně spolehlivé jako data použitá k jejich sestavení. Mimo výběru robustní a spolehlivé historické údaje ze zdroje, kterému můžete důvěřovat, existuje mnoho způsobů, aby se chyby, které činí výstupy modelu smysl. Například stojí za to zajistit, aby data, která máte, přesně odpovídala územím(např.
v závislosti na čase a místě studia může být pro vás obtížné získat spolehlivý soubor údajů, na kterém bude váš model založen. Čím dále se v minulosti studuje, tím obtížnější to může být. Stejně tak může být snazší provádět tyto typy analýz ve společnostech, které byly silně byrokratické a zanechaly dobrou přežívající papírovou stopu, například v Evropě nebo Severní Americe.
pro zajištění kvality údajů v této případové studii byla každá proměnná buď spolehlivě vypočtena, nebo odvozena z publikovaných recenzovaných historických údajů (viz tabulka 1). Přesně tak, jak byly tyto údaje sestaveny, si můžete přečíst v původním článku, kde bylo podrobně vysvětleno.11
Našich Pěti Proměnných
S výše uvedenými principy v mysli, mohli bychom si vybrali libovolný počet proměnných, vzhledem k tomu, co jsme věděli o migrace push a pull faktory. Usadili jsme se na pěti (5), vybraných na základě toho, co jsme považovali za nejdůležitější, a o kterém jsme věděli, že lze zálohovat spolehlivými údaji.
| Proměnná | Zdroj |
|---|---|
| populace v zemi původu | 1771 hodnoty, Wrigley, „anglickém hrabství populace“, s. 54-5.12 |
| vzdálenost z Londýna | počítá s software |
| cena pšenice | Dělo a Nápor, „Týdenní Britské Ceny Obilí“13 |
| průměrné mzdy v zemi původu | Lovit, „Industrializace a Regionální Nerovnosti“, str. 965-6.14 |
| trajektorie mzdy | Lovit, „Industrializace a Regionální Nerovnosti“, str. 965-6.15 |
Tabulka 1: Pět proměnných použitých v modelu, a zdroj každého v recenzovaných literatury
Poté, co se rozhodl na tyto proměnné, spoluautor původní studie, Adam Dennett, rozhodla přepsat vzorec, aby to self-dokumentování, takže to bylo snadné zjistit, které bity se týkaly každého z těchto pěti proměnných. To je důvod, proč výše uvedený vzorec vypadá jinak než ten v původním výzkumném dokumentu. Nové symboly lze vidět v tabulce 2:
dvě další proměnné $i$ a $j$, znamenají „v místě původu“ a“ v Londýně“. $Wa_{i}$ znamená „úrovně mezd v místě původu“, zatímco $Wa_{j}$ by znamenalo „úrovně mezd v Londýně“. Těchto sedm nových symbolů může nahradit obecnější symboly ve vzorci:
\
Toto je nyní podrobnější a mírně zdokumentovaná verze předchozí rovnice. Oba řeší matematicky přesně stejným způsobem, protože změny jsou čistě povrchní a ve prospěch lidského uživatele.
úspěšně Absolvováno Proměnné Dataset
udělat tutorial rychlejší, snadnější k dokončení, údaje pro každý z 5 proměnných a každá z 32 okresů již byla sestavena a vyčistit, a lze je vidět v Tabulce 3, nebo stáhnout jako csv soubor. Tato tabulka také obsahuje známý počet tuláků z toho kraje, jak bylo pozorováno v primárním zdrojem záznamu:
| Kraj | Tuláci | $d$ km do Londýna | $P$ počet Obyvatel (osob) | $Wa$ Průměrné Mzdy (šilinků) | $WaT$ Mzda Trajektorie 1767-95 (změna v%) | $C$ Cena Pšenice (šilinků) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornwall | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
konečný rozdíl mezi tímto vzorcem a jeden použít v původním článku, je, že dvě proměnné stalo, že máte silnější vztah s tuláctví, když vyneseny přirozeně logaritmicky. Jsou to populace v původu ($P$) a vzdálenost od původu do Londýna ($d$). To znamená, že pro data v této studii je regresní čára (někdy nazývaná linie nejlepšího přizpůsobení) lepší, když byla data zaznamenána, než když nebyla. Můžete to vidět na obrázku 7, s nezaznamenanými údaji o populaci vlevo a přihlášenou verzí vpravo. Více bodů je blíže k linii nejlepšího uložení na zaznamenaném grafu než na nezaznamenaném grafu.
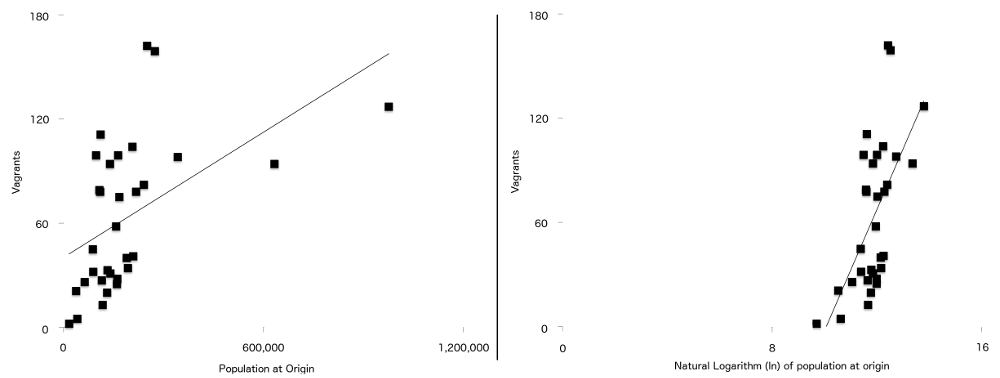
Obrázek 7: Počet Tuláků vyneseny proti počtu obyvatel v místě původu (vlevo) a přirozený logaritmus populace původu (vpravo) s jednoduchou regresní přímku překryly na obou. Všimněte si silnějšího vztahu mezi dvěma proměnnými viditelnými na druhém grafu.
Protože to je případ s touto konkrétní údaje (vaše vlastní data v podobném typu studia, nemusí následovat tento vzor), vzorec byl upraven na používání přirozeně zaznamenána verze těchto dvou proměnných, což v konečném vzorec použitý v gravitační model (Obrázek 8). My jsme nemohli tušit, o nutnosti této úpravy až poté, co jsme sesbírali naše variabilních dat:
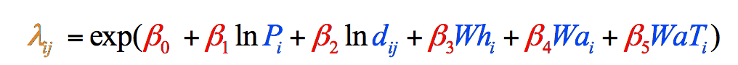
Obrázek 8: konečná gravitační model formule v členění podle stupňů a barevně. Prvky v černé barvě jsou matematické operace. Prvky v modré barvě představují naše proměnné ,které jsme právě shromáždili (Krok 1). Prvky v Červené představují koeficienty jednotlivých proměnných, které musíme vypočítat (Krok 2), a Prvek v Oranžové barvě je poslední odhad tuláci z okresu, které můžeme vypočítat, jakmile budeme mít další informace (Krok 3).
hodnoty v tabulce 3 nám dávají vše, co potřebujeme k vyplnění modrých částí každé rovnice na obrázku 8. Nyní můžeme obrátit naši pozornost na červené části, které nám říkají, jak důležitá je každá proměnná v modelu celkově, a dává nám čísla, která potřebujeme k dokončení rovnice.
Krok 2: Určení Vah
váhy pro každou proměnnou řekněte nám, jak důležité, že push/pull faktor je ve vztahu k jiné proměnné, když se snaží odhadnout počet tuláků, které by měly pocházet z daného kraje. Parametry $ β$ musí být stanoveny v celé datové sadě ze známých dat. S nimi po ruce budeme moci porovnat jednotlivá pozorování specifická pro původ s obecným modelem. Pak je můžeme prozkoumat a identifikovat nad a pod předpokládanými toky mezi různým původem a cílem.
v této fázi nevíme, jak důležitý je každý. Možná je cena pšenice lepším prediktorem migrace než vzdálenost? Nebudeme to vědět, dokud nevypočítáme hodnoty $ β1 $ až $ β5$ (váhy) vyřešením výše uvedené rovnice. Y-intercept ($β0$) lze vypočítat pouze poté, co znáte všechny ostatní ($β1-β5$). Toto jsou červené hodnoty na obrázku 8 výše. Váhy jsou uvedeny v tabulce 4 a v tabulce A1 původního papíru.16 nyní ukážeme, jak jsme k těmto hodnotám dospěli.
pro výpočet těchto hodnot long-hand vyžaduje neuvěřitelné množství práce. Budeme používat rychlé řešení v R programovací jazyk, který využívá William Venables a Brian Ripley je HMOTNOST balíčku, který může vyřešit negativní binomické regrese rovnice jako naše gravitační model s jediný řádek kódu. Nicméně, to je důležité pochopit principy za to, co člověk dělá, aby ocenit to, co ten kód dělá (poznámka: v následujících částech se nemusíte DĚLAT výpočet, ale vysvětlit jeho kroky pro vás, budeme dělat výpočet s kódem níže na stránce).
Výpočet Jednotlivých Koeficientů (v Zásadě)
$β_{1}$, $β_{2}$, atd, jsou stejné jako $β$ v Jednoduché Lineární Regresní model výše, což je sklon regresní přímky (vzestupu nad útěku, nebo kolik $y$ se zvyšuje, když $x$ se zvyšuje o 1). Jediný rozdíl mezi jednoduchou lineární regresí a gravitačním modelem je, že musíme vypočítat 5 svahů místo 1.
Jednoduchá Lineární Regrese\(y = α + ßx\)
Budeme muset řešit pro každý z těchto pěti sjezdovek, než můžeme vypočítat y v dalším kroku. Je to proto, že svahy různých hodnot $ β$ jsou součástí rovnice pro výpočet y-intercept.
vzorec pro výpočet $ β$ v regresní analýze je:
\
Pearsonův korelační koeficient
Pearsonův korelační koeficient lze vypočítat dlouhodobě, ale v tomto případě je to poměrně dlouhý výpočet, vyžadující 64 čísel. Tam jsou některé skvělé video tutoriály v angličtině k dispozici on-line, pokud byste chtěli vidět průchozí, jak to udělat výpočty dlouhé ruce.17 Existuje také řada online kalkulaček, které pro vás vypočítají $r$, pokud poskytnete data. Vzhledem k velkému počtu číslic pro výpočet, doporučil bych web s vestavěným nástrojem navrženým k provedení tohoto výpočtu. Ujistěte se, že jste si vybrali seriózní web, jako je ten, který nabízí univerzita.
Výpočet $s_{y}$ & $s_{x}$ (Směrodatná Odchylka)
Směrodatná odchylka je způsob, jak vyjádřit, jak moc se odchylky od střední hodnoty (průměru) je v datech. Jinými slovy, jsou data poměrně seskupena kolem průměru, nebo je šíření mnohem širší?
opět existují online kalkulačky a statistické softwarové balíčky, které vám mohou tento výpočet provést, pokud poskytnete data.
výpočet $ β_{0}$ (y-Intercept)
dále musíme vypočítat y-intercept. Vzorec pro výpočet y-intercept v Jednoduché Lineární Regresi je:
\
Však, že výpočet se stává mnohem složitější, ve vícenásobné regresní analýzy, jako každá proměnná má vliv na výpočet. To dělá to ručně velmi obtížné, a je jedním z důvodů, proč jsme se rozhodli pro programové řešení.
Kód pro Výpočet Koeficientů
HMOTNOST statistický balík, napsané pro R programovací jazyk, má funkci, která může vyřešit negativní binomické regrese rovnice, takže je velmi snadné si spočítat, co by jinak bylo velmi obtížné, dlouhé straně vzorce.
tato část předpokládá, že jste nainstalovali R a nainstalovali hromadný balíček. Pokud jste tak neučinili, budete muset před pokračováním. Výukový program Taryn Dewar o základech R s tabulkovými daty obsahuje pokyny k instalaci R.
Chcete-li použít tento kód, budete muset stáhnout kopii datové sady pěti proměnných plus počet pozorovaných tuláků z každého z 32 krajů. To je k dispozici výše jako tabulka 3, nebo lze stáhnout jako .soubor csv. Bez ohledu na zvolený režim uložte soubor jako VagrantsExampleData.csv. Pokud používáte Mac, nezapomeňte jej uložit jako formát Windows .soubor csv. Otevřete VagrantsExampleData.csv a seznámit se s jeho obsahem. Měli byste si všimnout každého z 32 krajů, spolu s každou z proměnných, o kterých jsme diskutovali v tomto tutoriálu. Budeme používat záhlaví sloupců pro přístup k těmto datům pomocí našeho počítačového programu. Mohl jsem jim volal tak něco, ale v tomto souboru jsou:
vagrantspopulationdistancewheatwageswageTrajectory
Ve stejném adresáři jako jste uložili soubor ve formátu csv, vytvořit a uložit nový R soubor skriptu (můžete to udělat s jakoukoli textový editor nebo s RStudio, ale nepoužívejte slovo procesoru, jako je MS Word). Uložte jej jako váženívýpočty.r.
nyní napíšeme krátký program, který:
- Nainstaluje HMOTNOST balení
- Volání HMOTNOST balení, takže ji můžeme použít v našem kódu
- Ukládá obsah .soubor csv na proměnnou, kterou můžeme použít programově
- řeší rovnici gravitačního modelu pomocí datové sady
- výstupy výsledků výpočtu.
každá z těchto úkolů bude postupně dosažena jediným řádkem kódu
zkopírujte výše uvedený kód do svých výpočtů váhy.r soubor a uložit. Nyní můžete spustit kód pomocí vašeho oblíbeného R. prostředí (používám RStudio) a výsledky výpočtu by se měl objevit v okně konzoly (jak to vypadá, bude záviset na prostředí). Možná budete muset nastavit pracovní adresář vašeho R prostředí do adresáře obsahujícího vaše .csv a .r soubory. Pokud používáte RStudio, můžete to provést pomocí nabídek (Session – > Set Working Directory – > select Directory). Můžete také dosáhnout stejné s příkazem:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundVšimněte si, že řádek 4 je čára, která pro nás řeší rovnici pomocí glm.nb funkce, což je zkratka pro „zobecněný lineární model-negativní binomický“. Tento řádek vyžaduje řadu vstupů:
- naše proměnné pomocí záhlaví sloupců, jak je napsáno v .soubor csv, spolu s jakýmkoli protokolováním, které je třeba provést (
vagrants, log (population), log(distance),wheat,wages,wageTrajectory). Pokud používáte model s vlastními daty, upravili byste je tak, aby odrážely záhlaví sloupců v datovém souboru. - kde kód může najít data – v tomto případě proměnnou, kterou jsme definovali v řádku 3 s názvem
gravityModelData.
výstupy z výpočtu lze vidět na Obrázku 9:
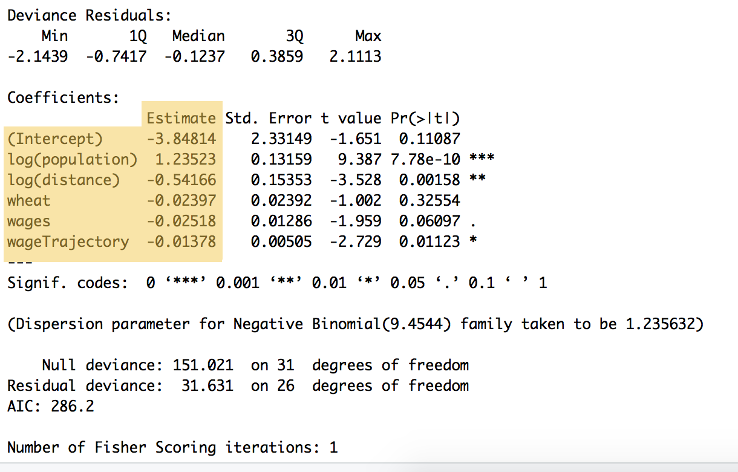
Obrázek 9: přehled výše uvedený kód ukazuje koeficienty pro každou proměnnou a y, které jsou uvedeny v „Odhad“ čísla ($\beta_{0}$ pro $\beta_{5}$. Tento souhrn také ukazuje řadu dalších výpočtů, včetně statistické významnosti.
Krok 3: Výpočet odhadů pro každý Kraj
musíme to udělat jednou pro každý z 32 okresů.
můžete to udělat pomocí vědecké kalkulačky, vytvořením tabulkového vzorce nebo napsáním počítačového programu. Chcete-li to provést automaticky v R, můžete do kódu přidat následující a program znovu spustit. for smyčka se počítá počet tuláků z každé z 32 kraje v příkladu a vytiskne výsledky pro vás, viz:
vybudovat porozumění, doporučuji dělat jednu county long-hand. Tento výukový program bude používat Hertfordshire jako příklad dlouhé ruky (ale proces je přesně stejný pro ostatní 31 kraje).
Použití dat pro Hertfordshire v Tabulce 3, a koeficienty pro každou proměnnou v Tabulce 4, nyní můžeme dokončit náš vzorec, který bude obsahovat výsledek 95:
za Prvé, pojďme vyměnit symboly pro čísla, převzaté z tabulek uvedených výše.
poté začněte vypočítat hodnoty, abyste se dostali k odhadu. Zapamatování matematické pořadí operací, násobit hodnoty před přidáním. Takže začít tím, že výpočet každé proměnné (můžete použít vědeckou kalkulačku za to):
dalším krokem je přidat čísla dohromady:
estimated vagrants = exp(4.56232408897)A konečně, pro výpočet exponenciální funkce (použijte vědeckou kalkulačku):
estimated vagrants = 95.8059926832Snížili jsme zbytek a prohlásil, že odhadovaný počet bezdomovců z Hertfordshire v tomto modelu je 95. Musíte provést stejné výpočty pro každý z ostatních krajů, které byste mohli urychlit pomocí tabulkového programu. Jen ujistěte se, že můžete udělat to znovu, já jsem také čísla pro Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
já doporučuji, výběrem jedné jiné kraje a výpočet je dlouho-ruce předtím, než pohybující se na, ujistěte se, že můžete dělat výpočty na vlastní pěst. Správná odpověď je k dispozici v Tabulce 5, která porovnává pozorované hodnoty (jak je vidět na primární zdroj záznamu) do předpokládané hodnoty (vypočtené podle našich gravity model). „Zbytkový“ je rozdíl mezi těmito dvěma, s velkým rozdílem naznačujícím neočekávaný počet tuláků,kteří by mohli stát za bližší pohled s kloboukem historika.
| Kraj | Pozorovaná Hodnota | Odhadovaná Hodnota | Zbytkové |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornwall | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Warwickshire | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Krok 4 – Historický Výklad
V této fázi, proces modelování je úplné a konečné fázi je historický výklad.
původní článek, na který tato případová studie byla založena, se věnuje především interpretaci, co výsledky modelování znamená pro naše chápání nižší třídy migrace v osmnáctém století. Jak je vidět na mapě na obrázku 5, tam byly části země, které Model silně navrhl, byly buď nad – nebo pod-posílání migrantů nižší třídy do Londýna.
spoluautoři nabídli své interpretace, proč se tyto vzory mohly objevit. Tyto interpretace se lišily podle místa. V oblasti Severní Anglie, které byly rychle se industrializujících, jako je Yorkshire nebo Manchester, příležitosti, lokálně se objevil, aby lidé méně důvodů opustit, což vede k nižší, než se očekávalo migrace do Londýna. V klesajících oblastech na západ, jako je Bristol, lákadlo Londýna bylo silnější, protože více lidí odešlo hledat práci v hlavním městě.
ne všechny vzory byly očekávány. Northumberland na Dálném severovýchodě se ukázal být regionální anomálií a poslal do Londýna mnohem více (ženských) migrantů,než bychom očekávali. Bez výstupů modelu, je nepravděpodobné, že bychom si myslel, že uvažovat Northumberland vůbec, zejména proto, že byla tak daleko od Metropole a domnívali jsme se, že by slabé vazby do Londýna. Model tak poskytl nové důkazy, které jsme mohli považovat za historiky, a změnil naše chápání vztahu Londýn-Northumberland. Úplnou diskusi o našich zjištěních si můžete přečíst v původním článku.18
Přičemž Své Znalosti Vpřed
Poté, co se snažil tento příklad problému, měli byste mít jasnou představu o tom, jak použít tento příklad vzorce, stejně jako zda nebo ne gravitační model může být vhodným řešením pro váš výzkumný problém. Máte zkušenosti a slovní zásobu, aby přístup a diskutovat o gravitační modely s vhodně matematicky gramotný spolupracovník byste třeba, kdo vám může pomoci přizpůsobit své vlastní případové studie.
Pokud jste štěstí, že mají také údaje o migranty pohybující se na konci osmnáctého století v Londýně a chcete model pomocí stejných pět proměnných uvedených výše, tento vzorec by pracovat jako-je – je snadné studovat tady pro někoho s správná data. Tento model však nefunguje pouze pro studie o migrantech, kteří se stěhují do Londýna. Proměnné se mohou měnit a cíl nemusí být Londýn. Bylo by možné použít gravitační model ke studiu migrace do starověkého Říma, nebo Bangkok jednadvacátého století, pokud máte data a výzkumnou otázku. Nemusí to být ani model migrace. Chcete-li použít případovou studii kolumbijské kávy z úvodu, která se zaměřuje spíše na obchod než na migraci, Tabulka 6 ukazuje životaschopné použití stejného vzorce, nezměněné.
| Kritéria | Káva Vyvážející Příklad |
|---|---|
| JEDEN bod původu | káva vyváží z přístavu Barranquilla, Kolumbie |
| VÍCE konečných destinací | 21 zemí Západní Polokoule v 1950 |
| PĚT vysvětlujících proměnných | (1) počet Atlantského Oceánu porty v přijímající zemi (2) miles z Kolumbie, (3) Hrubý Domácí Produkt přijímající země, (4) Domácí Káva pěstuje v tun, (5) kavárny na 10 000 lidí |
v akademickém stipendiu je dlouhá historie gravitačních modelů. Použít efektivně pro výzkum, musíte pochopit základní teorie a matematika za nimi a důvody, které se vyvinuly jako oni. Je také důležité pochopit jejich limity a podmínky pro jejich použití správně, z nichž některé byly diskutovány výše. Mohlo by to také pomoci vědět:
-
gravitační model, jako je ten použitý v tomto příkladu, může fungovat pouze v uzavřeném systému. Výše uvedený model měl pouze 32 možných bodů původu, což umožnilo spustit model 32krát. Neznámý nebo nekonečně velký počet míst původu (nebo destinací v závislosti na vašem modelu) by vyžadoval jinou rovnici.
-
gravitační model konceptu je také postavena na předpokladu, že pohyb (migrace, obchod, atd.) jsou založeny na sběru dobrovolné individuální rozhodnutí, které by mohly být ovlivněny vnějšími faktory, ale nejsou zcela ovládány. Například, dobrovolné stěhování nebo nákupy svobodné vůle mohla být modelována pomocí této techniky, ale nucené migrace, vyvlastnění, nebo přírodní procesy, jako migrace ptáků nebo říční tok nemusí dodržovat stejné zásady, a tedy jiný typ modelu, může být zapotřebí.
-
Gravitační modely mohou být použity k předpovídat chování populace, ale ne jednotlivce, a proto se pokusí datový model by měl obsahovat velké množství pohybů k zajištění statistické významnosti.
úskalí je mnohem více, ale také ohromné možnosti. Doufám, že tento průchod gravitačního modelu, a jeho doprovodný publikovaný výzkum, učiní tento mocný nástroj dostupnějším pro historiky. Pokud máte v úmyslu použít gravitační model ve své vědecké výzkumu autor doporučuje následující články:
Poděkování
S díky Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas, a Leanne Calvert za čtení a komentování na dřívější verze tohoto článku. Také díky Britské Akademii za financování psacího workshopu v Bogotě v Kolumbii, na kterém byl tento článek vypracován. A nakonec Adamu Dennettovi za to, že mě seznámil s těmito úžasnými vzorci a uvolnil jejich potenciál pro historiky.