a gently Introduction to Auto-Encoder and Some of its Common Use Cases With Python Code
Background:
Autoencoder on valvomaton keinotekoinen neuroverkko, joka oppii tehokkaasti pakkaamaan ja koodaamaan dataa ja oppii sitten rekonstruoimaan datan takaisin pelkistetystä koodatusta esityksestä esitykseen, joka on mahdollisimman lähellä alkuperäistä syötettä.
Autoencoder pienentää tietomittoja siten, että se oppii sivuuttamaan datan kohinan.
tässä on esimerkki mnist-aineiston syöte/tuotoskuvasta automaattiseen kooderiin.
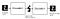
Autencoder Components:
Autoencoders koostuu 4 pääosasta:
1-Encoder: jossa malli oppii vähentämään tulomittoja ja pakkaamaan syöttötiedot koodatuksi esitykseksi.
2-pullonkaula: joka on taso, joka sisältää pakatun esityksen syöttötiedoista. Tämä on syöttötietojen alin mahdollinen mitta.
3 – dekooderi: jossa malli oppii rekonstruoimaan datan koodatusta esityksestä mahdollisimman lähelle alkuperäistä syötettä.
4-Rekonstruktiohäviö: tämä on menetelmä, jolla mitataan, kuinka hyvin dekooderi toimii ja kuinka lähellä lähtö on alkuperäistä syöttöä.
tämän jälkeen harjoitukseen kuuluu selän eteneminen verkoston rekonstruointihäviön minimoimiseksi.
ihmettelet varmaan, miksi kouluttaisin neuroverkkoa vain tuottamaan kuvan tai datan, joka on täsmälleen sama kuin tulo! Tämä artikkeli kattaa yleisimmät käyttötapaukset Autoencoder. Aloitetaan:
Autoencoder-Arkkitehtuuri:
automaattiohjaajien verkkoarkkitehtuuri voi vaihdella yksinkertaisen FeedForward-verkon, LSTM-verkon tai Convolutionaalisen neuroverkon välillä käyttötapauksesta riippuen. Tutkimme joitakin näistä arkkitehtuureista uusissa lähiriveissä.
poikkeamien ja poikkeamien havaitsemiseen on monia tapoja ja tekniikoita. Olen käsitellyt tätä aihetta eri postitse alla:
kuitenkin, jos sinulla on korreloivat syöttötiedot, automaattinen kooderi menetelmä toimii erittäin hyvin, koska koodaus operaatio perustuu korreloivat ominaisuudet pakata tiedot.
sanotaan, että olemme kouluttaneet mnist-aineistoon automaattisen koodaajan. Käyttämällä yksinkertaista FeedForward-neuroverkkoa voimme saavuttaa tämän rakentamalla yksinkertaisen 6-kerroksisen verkon kuten alla:
yllä olevan koodin ulostulo on:
kuten näet tulosteesta, validointijoukon viimeinen rekonstruktiohäviö / virhe on 0.0193, mikä on suuri. Nyt, jos ohitan minkä tahansa normaalin kuvan MNIST-aineistosta, rekonstruointihäviö on hyvin pieni (< 0.02), mutta jos yritin ohittaa minkä tahansa muun eri kuvan (poikkeavan tai anomalian), saamme suuren rekonstruointihäviön arvon, koska verkko ei onnistunut rekonstruoimaan kuvaa/syöttöä, jota pidetään anomaliana.
huomaa yllä olevassa koodissa, että voit käyttää vain kooderiosaa joidenkin tietojen tai kuvien pakkaamiseen ja voit myös käyttää vain dekooderiosaa tietojen purkamiseen lataamalla dekooderikerroksia.
nyt tehdään anomalian havainnointia. Alla oleva koodi käyttää kahta eri kuvaa anomalian pisteiden ennustamiseen (rekonstruktiovirhe) yllä koulutetun autencoder-verkon avulla. ensimmäinen kuva on mnistiltä ja tulos on 5.43209. Tämä tarkoittaa, että Kuva ei ole poikkeama. Toinen käyttämäni Kuva on täysin satunnainen kuva, joka ei kuulu harjoitusaineistoon ja tulokset olivat: 6789.4907. Tämä suuri virhe tarkoittaa, että kuva on poikkeama. Sama käsite koskee mitä tahansa tietojoukkoa.