kuluttajateollisuuden datatutkijana olen yleensä sitä mieltä, että algoritmien tehostaminen riittää ainakin tähän mennessä useimpiin ennakoiviin oppimistehtäviin. Ne ovat voimakkaita, joustavia ja niitä voi tulkita hienosti joillakin nikseillä. Näin ollen mielestäni on tarpeen lukea läpi joitakin materiaaleja ja kirjoittaa jotain lisäämällä algoritmeja.
suurin osa tämän artikkelin sisällöstä perustuu paperiin: Tree Boosting With XGBoost: Why Does XGBoost Win ”Every” Machine Learning Competition?. Se on todella informatiivinen paperi. Lähes kaikki algoritmien tehostamiseen liittyvät asiat selitetään lehdessä hyvin selvästi. Paperi sisältää siis 110 sivua: (
itse keskityn periaatteessa kolmeen suosituimpaan tehostusalgoritmiin: AdaBoost, GBM ja XGBoost. Olen jakanut sisällön kahteen osaan. Ensimmäinen artikkeli (tämä) keskittyy AdaBoost-algoritmiin, ja toinen kääntyy vertailuun GBM: n ja Xgboostin välillä.
AdaBoost, lyhenne sanoista ”Adaptive Boosting”, on Freundin ja Schapiren vuonna 1996 ehdottama ensimmäinen käytännöllinen boosting-algoritmi. Se keskittyy luokitteluongelmiin ja pyrkii muuttamaan joukon heikkoja luokittajia vahvoiksi. Luokittelun lopullinen yhtälö voidaan esittää seuraavasti
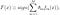
missä f_m tarkoittaa m_th heikkoa luokittelijaa ja theta_m on vastaava paino. Se on juuri m heikkojen luokittelijoiden painotettu yhdistelmä. AdaBoost-algoritmin koko menettely voidaan tiivistää seuraavasti.
AdaBoost-algoritmi
annettu n-pisteitä sisältävä tietojoukko, jossa

tässä -1 tarkoittaa negatiivista luokkaa, kun taas 1 edustaa positiivista.
alustaa kunkin datapisteen paino seuraavasti::

iteroinnille m=1,…, M:
(1) Asenna heikot luokittelijat tietoaineistoon ja valitse se, jolla on pienin painotettu luokitteluvirhe:

(2) laske paino m_th heikko luokittelija:

mille tahansa luokittajalle, jonka tarkkuus on yli 50%, paino on positiivinen. Mitä tarkempi luokittelija, sitä suurempi paino. Kun taas classifer Alle 50% tarkkuudella, paino on negatiivinen. Se tarkoittaa, että yhdistämme sen ennustuksen kääntämällä kylttiä. Voimme esimerkiksi muuttaa luokittelijan 40%: n tarkkuudella 60%: n tarkkuudella kääntämällä ennusteen merkkiä. Näin luokittelijakin suoriutuu satunnaista arvailua huonommin, se vaikuttaa silti lopulliseen ennustamiseen. Emme vain halua mitään luokittelija tarkka 50% tarkkuus, joka ei lisää mitään tietoa ja siten edistää mitään lopullista ennustusta.
(3) Päivitä kunkin datapisteen paino seuraavasti::

missä Z_m on normalisointikerroin, joka varmistaa kaikkien esiintymien painojen summan olevan yhtä suuri kuin 1.
jos väärin luokiteltu tapaus on positiiviselta painotetulta luokittelijalta, osoittajan” exp ” – termi olisi aina suurempi kuin 1 (y*f on aina -1, theta_m on positiivinen). Näin väärin luokitellut tapaukset päivitettäisiin suuremmilla painoilla iteroinnin jälkeen. Sama logiikka pätee negatiivisiin painotettuihin luokittelijoihin. Ainoa ero on, että alkuperäiset oikeat luokitukset muuttuisivat virheellisiksi merkin kääntämisen jälkeen.
M-iteroinnin jälkeen saadaan lopullinen ennustus summaamalla kunkin luokittelijan painotettu ennustus.
AdaBoost Forward Stagewise Additive Model
This part is based on paper: Additive logistic regression: a statistical view of boosting. Tarkemmat tiedot löytyvät alkuperäisestä paperista.
vuonna 2000, Friedman et al. kehitti tilastollisen näkemyksen AdaBoost-algoritmista. He tulkitsivat AdaBoost – menetelmän vaiheittaiseksi estimointimenetelmäksi additiivisen logistisen regressiomallin sovittamiseksi. He osoittivat, että AdaBoost oli todella minimoimalla eksponentiaalinen tappio toiminto

se on minimoitu

koska AdaBoost, y voi olla vain -1 tai 1, tappio funktio voidaan kirjoittaa uudelleen

Jatka ratkaista F (x), saamme

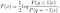
voimme edelleen johtaa normaalin logistisen mallin optimaalisesta ratkaisusta F (x):

se on lähes identtinen logistisen regressiomallin kanssa tekijästä 2 huolimatta.
Oletetaan, että meillä on nykyinen arvio F(x) ja yritetään hakea parannettua arviota F(x)+cf(x). Kiinteän c ja x, voimme laajentaa L (y, F (x)+cf(x)) toiseen järjestykseen noin f (x)=0,

näin,

missä E_w(.|x) ilmaisee painotetun ehdollisen odotuksen ja kunkin datapisteen paino lasketaan seuraavasti:

jos c > 0, painotetun ehdollisen odotuksen minimointi on yhtä kuin maksimointi

koska y voi olla vain 1 tai -1, painotettu odotus voidaan kirjoittaa uudelleen

optimaalinen ratkaisu tulee

F(x) määrittämisen jälkeen paino C voidaan laskea minimoimalla suoraan L (y, F (x)+cf(x)):

Solving C, saamme


olkoon epsilon yhtä suuri kuin väärin luokiteltujen tapausten painotettu summa, niin

huomaa, että c voi olla negatiivinen, jos heikko oppija tekee huonommin kuin satunnainen arvaus (50%), siinä tapauksessa se kääntää automaattisesti napaisuuden.
instanssipainojen osalta parannetun yhteenlaskun jälkeen yksittäisen instanssin paino tulee,

näin ilmentymän paino päivitetään

verrattuna AdaBoost-algoritmissa käytettyihin,

näemme, että ne ovat identtisiä. Tämän vuoksi on järkevää tulkita AdaBoost forward stagewise additive model with exponential loss function, joka iteratiivisesti sopii heikkoon luokittelijaan parantamaan nykyistä estimaattia jokaisessa iteraatiossa m:
