päivitetty viimeksi 7.elokuuta 2019
Sanaedistykset ovat sanaedistystyyppi, jonka avulla merkitykseltään samankaltaisilla sanoilla voi olla samanlainen edustus.
ne ovat hajautettu esitys tekstille, joka on ehkä yksi tärkeimmistä läpimurroista syväoppimismenetelmien vaikuttavassa suorituskyvyssä haastavissa luonnollisen kielen käsittelyongelmissa.
tässä viestissä tutustutaan tekstidatan esittämiseen word-upotustapaan.
kun olet suorittanut tämän tehtävän, tiedät:
- mikä sanan upotustapa tekstin esittämiseen on ja miten se eroaa muista piirteiden poimintamenetelmistä.
- että tekstidatasta on olemassa 3 pääalgoritmia, joiden avulla voi opetella sanan upottamisen.
- että voit joko kouluttaa uuden upotuksen tai käyttää valmiiksi koulutettua upotusta luonnollisen kielen käsittelytehtävässä.
Aloita projektisi uudella kirjallani Deep Learning For Natural Language Processing, sisältäen vaiheittaiset oppaat ja Python-lähdekooditiedostot kaikille esimerkeille.
aloitetaan.

mitkä ovat sanavalinnat tekstille?
Kuva: Kanerva, some rights reserved.
- yleiskatsaus
- Tarvitsetko apua tekstidatan Syväoppimisessa?
- Mitä ovat Word-upotukset?
- Word-Upotusalgoritmit
- Embedding Layer
- Word2Vec
- käsine
- Word-upotusten käyttäminen
- Opettele Upotus
- käytä uudelleen upotusta
- Mitä Vaihtoehtoa Sinun Tulee Käyttää?
- Word Embedding Tutorials
- lisätietoja
- Artikkelit
- Papers
- projektit
- Books
- Summary
- kehitä Syväoppimismalleja Tekstidatalle jo tänään!
- kehitä omat tekstimallit minuuteissa
- tuo vihdoin Syväoppiminen luonnollisen kielen Prosessointiprojekteihisi
yleiskatsaus
tämä virka on jaettu 3 osaan; ne ovat:
- Mitä ovat Word-upotukset?
- Word-Upotusalgoritmit
- käyttäen Word-upotuksia
Tarvitsetko apua tekstidatan Syväoppimisessa?
ota ilmainen 7 päivän sähköpostin pikakurssi nyt (koodilla).
klikkaa ilmoittautuaksesi ja saat myös ilmaisen PDF Ebook-version kurssista.
Aloita ilmainen pikakurssi nyt
Mitä ovat Word-upotukset?
sana-embedding on opittu esitys tekstille, jossa sanat, joilla on sama merkitys, ovat samankaltaisia.
juuri tätä sanojen ja dokumenttien esittämistä koskevaa lähestymistapaa voidaan pitää yhtenä keskeisenä läpimurtona syväoppimisessa haastavien luonnollisten kielten käsittelyongelmien osalta.
yksi tiheiden ja pieniulotteisten vektorien käytön eduista on laskennallinen: suurin osa neuroverkkotyökaluista ei pelaa hyvin hyvin erittäin suuriulotteisilla, harvoilla vektoreilla. … Suurin hyöty tiheä edustustot on yleistys valtaa: jos uskomme joitakin ominaisuuksia voi tarjota samanlaisia vihjeitä, se kannattaa tarjota edustus, joka pystyy kaapata nämä yhtäläisyydet.
— sivu 92, Neural Network Methods in Natural Language Processing, 2017.
sana-embeddingit ovat itse asiassa tekniikaluokka, jossa yksittäiset sanat esitetään reaaliarvoisina vektoreina ennalta määritellyssä vektoriavaruudessa. Jokainen sana kartoitetaan yhteen vektoriin ja vektoriarvot opitaan neuroverkkoa muistuttavalla tavalla, minkä vuoksi tekniikka niputetaan usein syväoppimisen alaan.
keskeistä lähestymistavassa on ajatus tiheän hajautetun esityksen käyttämisestä jokaiselle sanalle.
jokaista sanaa edustaa reaaliarvoinen vektori, usein kymmeniä tai satoja ulottuvuuksia. Tämä on vastakohtana niille tuhansille tai miljoonille ulottuvuuksille, joita tarvitaan harvoihin sanaesityksiin, kuten yhden kuuman koodaukseen.
liitä jokaiseen sanaston sanaan hajautettu sana-ominaisuusvektori … ominaisuusvektori edustaa sanan eri puolia: jokainen sana liittyy vektoriavaruuden pisteeseen. Ominaisuuksien määrä … on paljon pienempi kuin sanaston koko
— a Neural Probabilistic Language Model, 2003.
hajautettu esitys opitaan sanojen käytön perusteella. Näin samankaltaisilla tavoilla käytetyt sanat voivat johtaa samanlaisiin representaatioihin, jotka luonnollisesti vangitsevat niiden merkityksen. Tämä voidaan asettaa vastakkain raikkaan mutta hauraan sanapussimallin kanssa, jossa eri sanoilla on erilaiset representaatiot riippumatta siitä, miten niitä käytetään.
lähestymistavan takana on syvempi kielellinen teoria, nimittäin Zellig Harrisin ”distributiivihypoteesi”, jonka voisi tiivistää seuraavasti: sanoilla, joilla on samanlainen konteksti, on samanlaiset merkitykset. Lisää syvyyttä löytyy Harrisin vuoden 1956 teoksesta ”Distributional structure”.
tämä käsitys siitä, että sanan käytön annetaan määritellä sen merkitys, voidaan tiivistää John Firthin usein toistamalla letkautuksella.:
saat tietää sanan seuralta, jota se pitää!
— sivu 11, ”a synopsis of linguistic theory 1930-1955”, teoksessa Studies in Linguistic Analysis 1930-1955, 1962.
Word-Upotusalgoritmit
Word-upotusmenetelmät oppivat reaaliarvoisen vektoriesityksen ennalta määritetylle kiinteäkokoiselle sanastolle korpuksesta tekstiä.
oppimisprosessi on joko yhdessä neuroverkkomallin kanssa jossakin tehtävässä, kuten dokumenttiluokituksessa, tai on valvomaton prosessi, jossa käytetään asiakirjatilastoja.
tässä osiossa käydään läpi kolme tekniikkaa, joiden avulla tekstidatasta voi oppia sanasisustuksen.
Embedding Layer
embedding layer on paremman nimen puutteessa sana-embedding, joka opitaan yhdessä neuroverkkomallin kanssa tietyssä luonnollisessa kielen käsittelytehtävässä, kuten kielen mallinnuksessa tai asiakirjaluokituksessa.
se edellyttää, että asiakirjateksti puhdistetaan ja valmistellaan siten, että jokainen sana on one-hot-koodattu. Vektoriavaruuden koko on määritelty osana mallia, kuten 50, 100 tai 300 ulottuvuutta. Vektorit alustetaan pienillä satunnaisluvuilla. Embedding-kerrosta käytetään neuroverkon etupäässä ja se sopii valvotusti Backpropagation-algoritmin avulla.
… kun hermoverkon tulo sisältää symbolisia kategorisia piirteitä (esim. ominaisuudet, jotka ottavat yhden K: n erillisistä symboleista, kuten sanat suljetusta sanastosta), on tavallista liittää jokainen mahdollinen ominaisarvo (eli jokainen sanaston sana) d-ulotteiseen vektoriin joillekin d: lle. näitä vektoreita pidetään sitten mallin parametreina, ja ne koulutetaan yhdessä muiden parametrien kanssa.
— sivu 49, Neural Network Methods in Natural Language Processing, 2017.
One-hot-koodatut sanat on yhdistetty sanavektoreihin. Jos käytetään monikerroksista Perceptron-mallia, sana vektorit konsatenoidaan ennen kuin ne syötetään syötteenä malliin. Jos käytetään toistuvaa neuroverkkoa, voidaan jokainen sana ottaa yhtenä syötteenä jonossa.
tämä upotuskerroksen oppiminen vaatii paljon koulutustietoa ja voi olla hidasta, mutta oppii sekä tiettyyn tekstitietoon että NLP-tehtävään kohdennetun upotuksen.
Word2Vec
Word2Vec on tilastollinen menetelmä itsenäisen sanasisustuksen oppimiseen tehokkaasti tekstikopiosta.
sen kehitti Tomas Mikolov ym. Googlella vuonna 2013 vastauksena tehdä neuroverkkoon perustuva koulutus upottaminen tehokkaampaa ja siitä lähtien on tullut de facto standardi kehittää ennalta koulutettu sana upottaminen.
lisäksi työhön kuului opittujen vektorien analysointi ja vektorimatematiikan tutkiminen sanojen representaatioista. Esimerkiksi se, että vähennetään ”mies-ness” sanasta ”kuningas ”ja lisätään” naiset-ness”, johtaa sanaan” kuningatar”, jolloin saadaan analogia”kuningas on kuningattarelle niin kuin mies on naiselle”.
huomaamme, että nämä representaatiot ovat yllättävän hyviä kuvaamaan syntaktisia ja semanttisia säännönmukaisuuksia kielessä, ja että jokaiselle relaatiolle on ominaista relaatiosidonnainen vektorisiirtymä. Tämä mahdollistaa vektorisuuntautuneen päättelyn, joka perustuu sanojen välisiin siirtymiin. Esimerkiksi miehen ja naisen suhde opitaan automaattisesti, ja indusoiduilla vektoriesityksillä ”kuningas – Mies + Nainen” saadaan aikaan vektori, joka on hyvin lähellä ”kuningatarta.”
— Linguistic Regularities in Continuous Space Word Representations, 2013.
otettiin käyttöön kaksi erilaista oppimismallia, joita voidaan käyttää osana word2vec-lähestymistapaa sanan upottamisen oppimiseen; ne ovat:
- jatkuva Sanapussi eli CBOW-malli.
- Jatkuva Skip-Grammamalli.
CBOW-malli oppii embeddingin ennustamalla nykyisen sanan sen asiayhteyden perusteella. Jatkuva skip-gram-malli oppii ennustamalla nykyisen sanan antamia ympäröiviä sanoja.
jatkuvan skip-gramman malli oppii ennustamalla ympäröiviä sanoja, jotka annetaan nykyiselle sanalle.
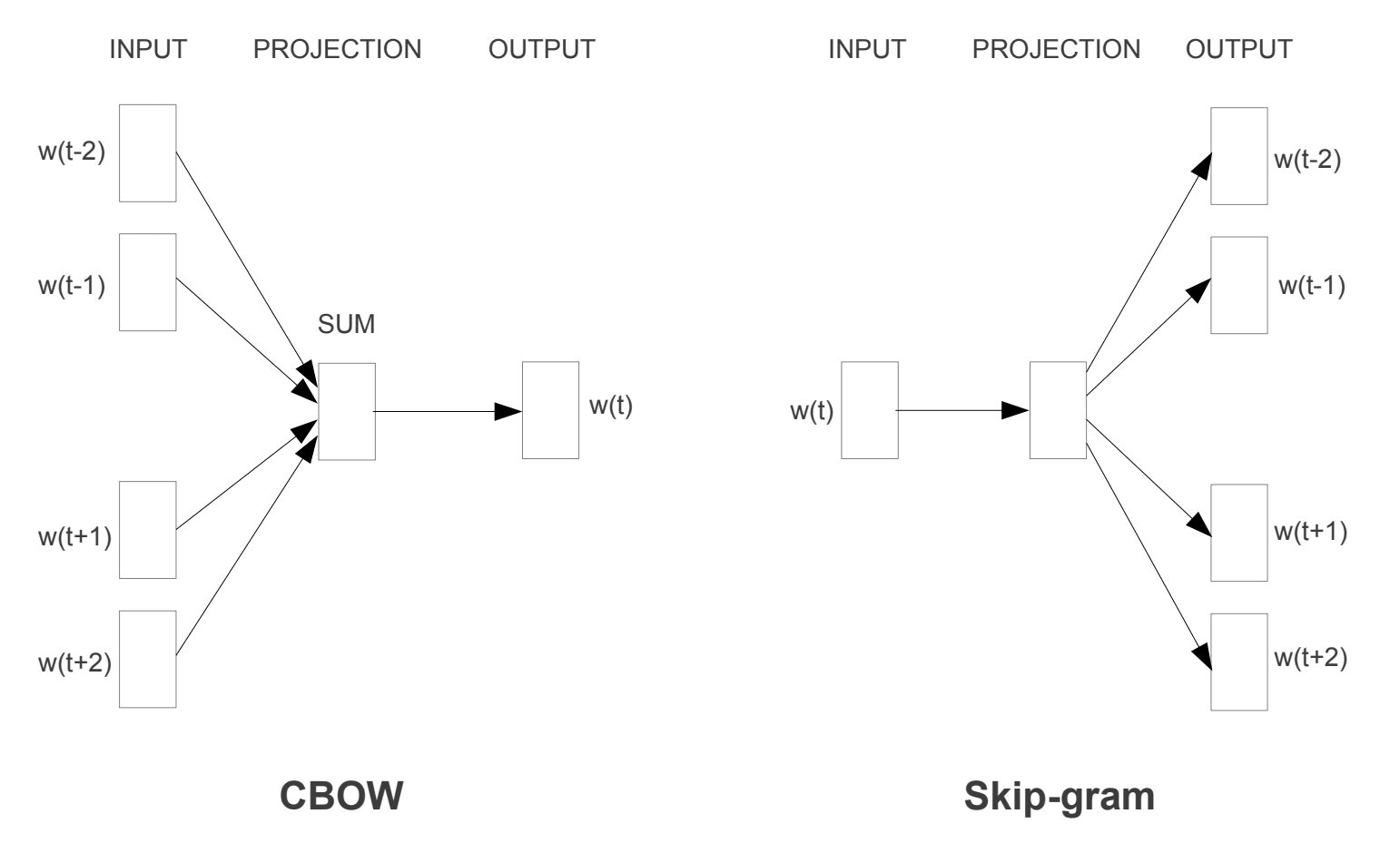
Word2Vec Training Models
otettu ”Efficient Estimation of Word Representations in Vector Space”, 2013
molemmat mallit ovat keskittyneet oppimaan sanoja ottaen huomioon niiden paikallisen käyttökontekstin, jossa asiayhteys määritellään naapurisanojen ikkunan avulla. Tämä ikkuna on mallin konfiguroitavissa oleva parametri.
Liukuikkunan koolla on suuri vaikutus syntyviin vektorien samankaltaisuuksiin. Suuret ikkunat pyrkivät tuottamaan ajankohtaisempia yhtäläisyyksiä, kun taas pienemmät ikkunat pyrkivät tuottamaan enemmän toiminnallisia ja syntaktisia yhtäläisyyksiä.
— sivu 128, Neural Network Methods in Natural Language Processing, 2017.
lähestymistavan keskeinen etu on se, että laadukkaat sanavalinnat voidaan oppia tehokkaasti (Matala Tila-ja ajallinen monimutkaisuus), jolloin voidaan oppia suurempia upotuksia (enemmän ulottuvuuksia) paljon suuremmasta tekstikorposta (miljardeja sanoja).
käsine
Global vectors for Word Representation, tai käsine, algoritmi on laajennus word2vec menetelmä tehokkaasti oppimisen sana vektoreita, kehittämä Pennington, et al. Stanfordissa.
sanojen klassiset vektoriavaruusmalliesitykset kehitettiin käyttäen matriisifaktorointitekniikoita, kuten latenttia semanttista analyysiä (LSA), jotka tekevät hyvää työtä globaalin tekstitilaston käytössä, mutta eivät ole yhtä hyviä kuin opitut menetelmät kuten word2vec merkityksen vangitsemisessa ja sen osoittamisessa tehtävissä, kuten analogioiden laskemisessa (esim. kuningas ja kuningatar esimerkki yllä).
käsine on lähestymistapa, joka yhdistää sekä LSA: n kaltaisten matriisifaktorointitekniikoiden globaalit tilastot word2vec: n paikalliseen kontekstipohjaiseen oppimiseen.
sen sijaan, että GloVe käyttäisi ikkunaa paikallisen asiayhteyden määrittelyyn, se muodostaa eksplisiittisen sana-asiayhteys-tai sanan rinnakkaisesiintymismatriisin käyttäen tilastoja koko tekstin corpuksessa. Tuloksena on oppimismalli, joka saattaa johtaa yleisesti parempiin sanavalintoihin.
käsine, on uusi maailmanlaajuinen log-bilineaarinen regressiomalli sanarepresentaatioiden valvomattomaan oppimiseen, joka päihittää muut mallit sanavertailussa, sanojen samankaltaisuudessa ja nimetyissä entiteettien tunnistustehtävissä.
— GloVe: Global vectors for Word Representation, 2014.
Word-upotusten käyttäminen
sinulla on joitakin vaihtoehtoja, kun on aika käyttää word-upotuksia luonnollisen kielen prosessointiprojektissasi.
tässä jaksossa esitetään nämä vaihtoehdot.
Opettele Upotus
voit halutessasi opetella sanavalinnan ongelmaasi.
tämä vaatii paljon tekstitietoa, jotta voidaan varmistaa hyödyllisten upotusten, kuten miljoonien tai miljardien sanojen, oppiminen.
sinulla on kaksi päävaihtoehtoa, kun harjoittelet sanasi upottamista:
- Opi Se itsenäisenä, jossa malli koulutetaan oppimaan upotusta, joka tallennetaan ja käytetään osana toista mallia tehtävääsi myöhemmin. Tämä on hyvä lähestymistapa, Jos haluat käyttää samaa upotusta useissa malleissa.
- Opettele yhteisesti, jossa upottaminen opetellaan osana suurta tehtäväkohtaista mallia. Tämä on hyvä lähestymistapa, Jos aiot vain käyttää upottamalla yhteen tehtävään.
käytä uudelleen upotusta
on tavallista, että tutkijat asettavat valmiiksi koulutetut sanavalinnat saataville ilmaiseksi, usein sallivalla lisenssillä, jotta voit käyttää niitä omissa akateemisissa tai kaupallisissa projekteissasi.
esimerkiksi sekä word2vec-että hansikas-word-upotukset ovat ladattavissa ilmaiseksi.
näitä voi käyttää projektissa sen sijaan, että harjoittelisi omia upotuksia tyhjästä.
sinulla on kaksi päävaihtoehtoa, kun on kyse esikoulutettujen upotusten käytöstä:
- Staattinen, jossa Upotus pidetään staattisena ja sitä käytetään mallisi osana. Tämä on sopiva lähestymistapa, jos Upotus sopii hyvin ongelmaasi ja antaa hyviä tuloksia.
- päivitetty, jossa esikoulutettua upotusta käytetään mallin kylvämiseen, mutta upotusta päivitetään yhdessä mallin koulutuksen aikana. Tämä voi olla hyvä vaihtoehto, jos haluat saada kaiken irti mallista ja upottaa tehtävääsi.
Mitä Vaihtoehtoa Sinun Tulee Käyttää?
Tutustu eri vaihtoehtoihin, ja jos mahdollista, testaa, mikä antaa parhaan tuloksen ongelmaasi.
aloita ehkä nopeilla menetelmillä, kuten käyttämällä valmiiksi koulutettua upotusta, ja käytä uutta upotusta vain, jos se johtaa parempaan suorituskykyyn ongelmassasi.
Word Embedding Tutorials
tämä osio listaa joitakin askel askeleelta oppaita, joita voit seurata word-upotusten käyttämiseksi ja word-upotusten tuomiseksi projektiin.
- kuinka kehittää Sanasisustuksia Pythonissa gensimin kanssa
- Kuinka käyttää Sanasisustustasoja Syväoppimiseen Kerasin kanssa
- kuinka kehittää syvä CNN Tunteanalyysille (Tekstiluokitus)
lisätietoja
tämä osio tarjoaa lisää resursseja aiheeseen, jos etsit mennä syvemmälle.
Artikkelit
- Word-upotukset Wikipediassa
- Word2vec Wikipediassa
- käsine Wikipediassa
- yleiskuva word-upotuksista ja niiden yhteydestä jakelumittauksiin, 2016.
- Deep Learning, NLP, and Representations, 2014.
Papers
- Distributional structure, 1956.
- A Neural Probabilistic Language Model, 2003.
- a Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning, 2008.
- jatkuvan avaruuden kielimallit, 2007.
- sanan representaatioiden tehokas estimointi Vektoriavaruudessa, 2013
- sanojen ja lauseiden hajautetut representaatiot ja niiden koostumus, 2013.
- hansikas: Global vectors for Word Representation, 2014.
projektit
- word2vec on Google Code
- hansikas: Global vectors for Word Representation
Books
- Neural Network Methods in Natural Language Processing, 2017.
Summary
tässä viestissä löysit Word-upotukset tekstin esitysmenetelmänä syväoppimissovelluksissa.
nimenomaan opit:
- mikä on edustustekstin sana-upotustapa ja miten se eroaa muista ominaisuuksien louhintamenetelmistä.
- että tekstidatasta on olemassa 3 pääalgoritmia, joiden avulla voi opetella sanan upottamisen.
- että voit joko kouluttaa uuden upotuksen tai käyttää valmiiksi koulutettua upotusta luonnollisen kielen käsittelytehtävässä.
onko sinulla kysyttävää?
kysy kysymyksesi alla olevissa kommenteissa ja teen parhaani vastatakseni.
kehitä Syväoppimismalleja Tekstidatalle jo tänään!

kehitä omat tekstimallit minuuteissa
…vain muutamalla rivillä python-koodia
Discover how in my new Ebook:
Deep Learning For Natural Language Processing
se tarjoaa itseopiskelua aiheista kuten:
Bag-of-Words, Word Embedding, Language Models, Caption Generation, Text Translation ja paljon muuta…
tuo vihdoin Syväoppiminen luonnollisen kielen Prosessointiprojekteihisi
jätä akateemikot väliin. Pelkkiä Tuloksia.
See What ’ s Inside