on myös useita vääriä tapoja sisällyttää muuttujia. Painovoimamalli ei toimi, ellei jokainen muuttuja täytä seuraavia kriteerejä:
- numeerinen
- täydellinen
- luotettava
vain numeerinen tieto
koska painovoimamalli on matemaattinen yhtälö, kaikkien syöttömuuttujien on oltava numeerisia. Se voisi olla laskelma (väestö), alueellinen mitta (alue, etäisyys jne.), Aika (tunteja Lontoosta jalan), prosenttiosuus (palkankorotus/lasku), valuutan arvo (palkat shillingeinä) tai jokin muu mitta mallissa mukana olevista paikoista.
lukujen on oltava merkityksellisiä, eivätkä ne voi olla nimellisiä kategorisia muuttujia, jotka toimivat kvalitatiivisena ominaisuutena. Esimerkiksi numeroa ei voi mielivaltaisesti antaa ja käyttää mallissa, jos luvulla ei ole merkitystä (esim. road quality = hyvä tai road quality = 4). Vaikka jälkimmäinen on numeerinen, se ei ole teiden laadun mittari. Sen sijaan voit käyttää keskimääräistä matkanopeutta kilometreinä tunnissa tien laadun mittarina. Se, onko keskinopeus mielekäs tien laadun mittari, on tutkimuksen tekijänä itsestä kiinni ja puolustettava.
yleisesti ottaen, jos sen voi mitata tai laskea, sen voi mallintaa.
Täydelliset tiedot vain
kaikkien tietoryhmien on oltava olemassa kunkin kiinnostavan kohdan osalta. Tämä tarkoittaa sitä, että kaikilla tarkastelun kohteena olevilla 32 piirikunnalla on oltava luotettavaa tietoa jokaisesta työntö-ja vetovoimatekijästä. Ei voi olla mitään aukkoja tai paukkupakkasia, kuten yksi maakunta, jossa ei ole keskipalkkaa.
vain luotettavaa tietoa
tietojenkäsittelytieteen sanonta ”roskat sisään, roskat ulos” pätee myös painovoimamalleihin, jotka ovat vain yhtä luotettavia kuin niiden rakentamiseen käytetty data. Sen lisäksi, että valitset vankan ja luotettavan historiallisen tiedon lähteistä, joihin voit luottaa, on olemassa paljon tapoja tehdä virheitä, jotka tekevät mallisi tuotoksista merkityksettömiä. Esimerkiksi, se on syytä varmistaa, että tiedot sinulla on täsmälleen vastaavat alueita (esim läänin tiedot edustavat piirikuntia, ei kaupungin tiedot edustavat lääniä).
opiskeluajankohdasta ja-paikasta riippuen sinun voi olla vaikea saada luotettavaa aineistoa, johon mallisi voisi perustua. Mitä kauempana menneisyydessä opiskellaan, sitä vaikeampaa se voi olla. Myös tämäntyyppisten analyysien tekeminen voi olla helpompaa yhteiskunnissa, jotka olivat raskaasti byrokraattisia ja jättivät hyvän jälkensä, kuten Euroopassa tai Pohjois-Amerikassa.
tietojen laadun varmistamiseksi tässä tapaustutkimuksessa jokainen muuttuja laskettiin luotettavasti tai johdettiin julkaistuista vertaisarvioiduista historiatiedoista (KS.Taulukko 1). Miten nämä tiedot on koottu, voidaan lukea alkuperäisestä artikkelista, jossa se selitettiin perusteellisesti.11
viisi Mallimuuttujaamme
edellä mainitut periaatteet huomioon ottaen olisimme voineet valita minkä määrän muuttujia tahansa, ottaen huomioon mitä tiesimme muuttoliikkeen työntö-ja vetovoimatekijöistä. Päädyimme viiteen (5), jotka valittiin sen perusteella, mitä ajattelimme olevan tärkeintä, ja jonka tiesimme voivan tukea luotettavilla tiedoilla.
| muuttuja | lähde |
|---|---|
| population at origin | 1771 values, Wrigley,” English county populations”, s.54-5.12 |
| etäisyys Lontoosta | laskettu ohjelmistolla |
| vehnän hinta | tykki ja Bruntti”, Weekly British Grain Prices”13 |
| average wages at origin | Hunt, ”Industrialization and Regional Inequality”, s. 965-6.14 |
| workshop of wages | Hunt, ”Industrialization and Regional Inequality”, s. 965-6.15 |
Taulukko 1: Mallissa käytetyt viisi muuttujaa ja kunkin lähde vertaisarvioidussa kirjallisuudessa
päätettyään näistä muuttujista alkuperäisen tutkimuksen toinen kirjoittaja Adam Dennett päätti kirjoittaa kaavan uudelleen tehdäkseen siitä itsedokumentoivan niin, että oli helppo sanoa, mitkä bitit liittyivät kuhunkin näistä viidestä muuttujasta. Siksi edellä esitetty kaava näyttää erilaiselta kuin alkuperäisessä tutkimuspaperissa. Uudet symbolit näkyvät taulukossa 2:
kaksi lisämuuttujaa $i$ ja $j$, jotka tarkoittavat ”at point of origin” ja ”at London”. $Wa_{i}$ tarkoittaa ”palkkatasoa lähtöpisteessä”, kun taas $Wa_{j}$ tarkoittaisi”palkkatasoa Lontoossa”. Nämä seitsemän uutta symbolia voivat korvata yleisemmät kaavassa:
\
tämä on nyt monisanaisempi ja hieman itse dokumentoitu versio edellisestä yhtälöstä. Molemmat ratkaisevat matemaattisesti täsmälleen samalla tavalla, koska muutokset ovat puhtaasti pinnallisia ja ihmiskäyttäjän hyödyksi.
täytetty Muuttujatietokanta
jotta opetusohjelma olisi helpompi suorittaa, kunkin 5 muuttujan ja 32 maakunnan tiedot on jo koottu ja puhdistettu, ja ne voidaan nähdä taulukossa 3 tai ladata csv-tiedostona. Tämä taulukko sisältää myös kyseisestä piirikunnasta peräisin olevien irtolaisten tunnetun määrän, joka on havaittu primaarilähteen tietueessa:
| kreivikunta | Kulkurit | $d$ km Lontooseen | $P$ väestö (henkilöt) | $Wa$ keskipalkka (shillingit) | $WaT$ palkkakehitys 1767-95 (muutos%) | $Wh$ vehnän hinta (shillingit)) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornwall | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
lopullinen ero tämän kaavan ja alkuperäisessä artikkelissa käytetyn kaavan välillä on se, että kahdella muuttujalla sattuu olemaan vahvempi suhde irtolaisuuteen, kun ne piirretään luonnollisesti logaritmisesti. Ne ovat väestö alkuperällä ($P$) ja etäisyys alkuperästä Lontooseen ($d$). Tämä tarkoittaa sitä, että tässä tutkimuksessa regressiolinja (jota joskus kutsutaan parhaan istuvuuden linjaksi) sopii paremmin silloin, kun tiedot on kirjattu, kuin silloin, kun niitä ei ole ollut. Voit nähdä tämän kuviossa 7, jossa ei-kirjatut väestöluvut ovat vasemmalla ja kirjattu versio oikealla. Useampi pisteistä on lähempänä kirjatun kuvaajan kuin kirjaamattoman viivaa.
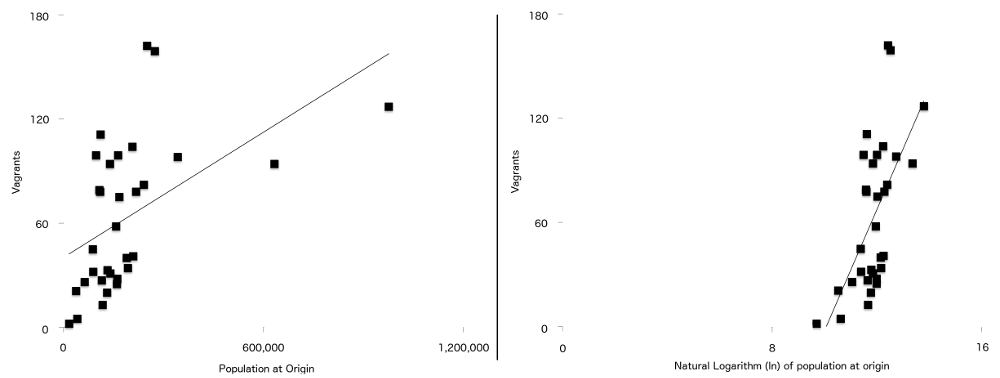
Kuva 7: Niiden irtolaisten lukumäärä, jotka on piirretty populaatiota vastaan alkuperäpisteessä (vasemmalla), ja luonnollinen alkuperäpopulaation loki (oikealla) yksinkertaisella regressiolinjalla, joka on päällekkäin molempien kanssa. Huomaa toisessa kaaviossa näkyvien kahden muuttujan välinen vahvempi suhde.
koska tämä pätee juuri tähän dataan (omat tietosi samantyyppisessä tutkimuksessa eivät välttämättä noudata tätä kaavaa), kaavaa muutettiin käyttämään näiden kahden muuttujan luonnollisesti kirjattuja versioita, jolloin päädyttiin gravitaatiomallissa käytettyyn lopulliseen kaavaan (Kuva 8). Emme olisi mitenkään voineet tietää tämän muutoksen tarpeesta ennen kuin olimme keränneet muuttuvan datamme.:
Kuva 8: lopullinen painovoimamallin kaava jaoteltuna portain ja värikoodein. Elementit mustalla ovat matemaattisia operaatioita. Elementit Sininen edustavat muuttujia, jotka olemme juuri keränneet (Vaihe 1). Punaisella merkityt elementit kuvaavat kunkin muuttujan painotuksia, jotka meidän on laskettava (Vaihe 2), ja oranssilla merkitty elementti on kyseisen maakunnan irtolaisten lopullinen arvio, jonka voimme laskea, kun meillä on muut tiedot (Vaihe 3).
taulukon 3 arvot antavat meille kaiken, mitä tarvitsemme täyttääksemme jokaisen yhtälön siniset osat kuvassa 8. Voimme nyt kääntää huomiomme punaisiin osiin, jotka kertovat meille, kuinka tärkeä kukin muuttuja on mallissa kokonaisuutena, ja antavat meille numerot, joita tarvitsemme yhtälön täydentämiseksi.
Vaihe 2: painotusten määrittäminen
kunkin muuttujan painotukset kertovat, kuinka tärkeä tämä push/pull-kerroin on suhteessa muihin muuttujiin, kun yritetään arvioida niiden irtolaisten määrää, joiden olisi pitänyt tulla tietystä kreivikunnasta. $Β$ – parametrit on määritettävä koko tietokokonaisuudesta tunnetuista tiedoista. Näiden avulla voimme vertailla yksittäisiä alkuperäkohtaisia havaintoja yleiseen malliin. Voimme sitten tutkia näitä ja tunnistaa yli ja alle ennustetut virtaukset eri alkuperien ja määränpään välillä.
tässä vaiheessa emme tiedä, kuinka tärkeä kukin on. Ehkä vehnän hinta ennustaa muuttoa paremmin kuin etäisyys? Emme tiedä ennen kuin laskemme arvot $β1$ kautta $β5$ (painotukset) ratkaisemalla yhtälö edellä. Y-sieppaus ($β0$) on mahdollista laskea vain, kun tunnet kaikki muut ($β1-β5$). Nämä ovat yllä olevan kuvan 8 punaiset arvot. Painotukset esitetään alkuperäisen paperin taulukossa 4 ja taulukossa A1.16 osoitamme nyt, miten päädyimme näihin arvoihin.
näiden arvojen laskeminen pitkällä kädellä vaatii uskomattoman määrän työtä. Käytämme R-ohjelmointikielellä nopeaa ratkaisua, joka hyödyntää William Venablesin ja Brian Ripleyn MASSAPAKETTIA, joka voi ratkaista negatiiviset binomiregressioyhtälöt kuten painovoimamallimme yhdellä koodirivillä. On kuitenkin tärkeää ymmärtää periaatteet, mitä on tekemässä, jotta voidaan ymmärtää, mitä koodi tekee (huomaa seuraavat kohdat eivät tee laskentaa, mutta selittää sen vaiheet sinulle; teemme laskennan koodin alempana sivulla).
yksittäisten painotusten laskeminen (periaatteessa)
$β_{1}$, $β_{2}$ jne.ovat samat kuin $β$ yksinkertaisessa lineaarisessa Regressiomallissa, joka on regressiolinjan kaltevuus (nousu juoksun aikana tai kuinka paljon $y$ kasvaa, kun $x$ kasvaa 1: llä). Ainoa ero yksinkertaisen lineaarisen Regression ja painovoimamallimme välillä on se, että meidän on laskettava 5 rinnettä 1: n sijasta.
yksinkertainen lineaarinen regressio\(y = α + ßx\)
jokaisen näistä viidestä rinteestä on ratkaistava ennen kuin seuraavassa vaiheessa voidaan laskea y-leikkaus. Tämä johtuu siitä, että eri $β$-arvojen rinteet ovat osa y-leikkauspisteen laskemisen yhtälöä.
laskukaava $β$ regressioanalyysissä on:
\
Pearsonin korrelaatiokerroin
Pearsonin korrelaatiokerroin voidaan laskea pitkällä kädellä, mutta se on tässä tapauksessa melko pitkä laskelma, joka vaatii 64 lukua. On olemassa hienoja video tutorials Englanti saatavilla verkossa, Jos haluat nähdä walk-through miten tehdä laskelmat pitkän käden.17 on myös useita online laskimia, jotka laskevat $r$ sinulle, jos annat tiedot. Koska suuri määrä numeroita laskea, suosittelen verkkosivuilla sisäänrakennettu työkalu suunniteltu tekemään tämän laskennan. Varmista, että valitset hyvämaineisen sivuston, kuten yliopiston tarjoaman sivuston.
laskemalla $s_{y}$ & $s_{x}$ (keskihajonta)
keskihajonta on tapa ilmaista, kuinka paljon vaihtelua keskiarvosta on aineistossa. Toisin sanoen, onko tiedot melko ryhmittynyt noin keskiarvo, vai onko leviäminen paljon laajempi?
on jälleen olemassa online-laskimia ja tilastollisia ohjelmistopaketteja, jotka voivat tehdä tämän laskennan puolestasi, jos annat tiedot.
laskettaessa $β_{0}$ (y-leikkaus)
seuraavaksi on laskettava y-leikkaus. Y-leikkauspisteen laskukaava yksinkertaisessa lineaarisessa regressiossa on:
\
laskenta kuitenkin monimutkaistuu moninkertaisessa regressioanalyysissä, koska jokainen muuttuja vaikuttaa laskentaan. Tämä tekee sen tekemisestä käsin erittäin vaikeaa, ja se on yksi syy siihen, että valitsemme ohjelmallisen ratkaisun.
painotusten Laskentakoodi
R-ohjelmointikielelle kirjoitetussa MASSATILASTOLLISESSA paketissa on funktio, jolla voidaan ratkaista negatiivisia binomiregressioyhtälöitä, jolloin on erittäin helppo laskea, mikä muuten olisi hyvin vaikea pitkän käden kaava.
tässä osiossa oletetaan, että olet asentanut R: n ja asentanut MASSAPAKETIN. Jos et ole tehnyt niin sinun täytyy ennen kuin jatkat. Taryn Dewarin opetusohjelma R: n perusasioista taulukkotietojen kanssa sisältää r: n asennusohjeet.
tätä koodia käyttääksesi sinun on ladattava kopio viiden muuttujan aineistosta sekä havaittujen irtolaisten lukumäärä jokaisesta 32 piirikunnasta. Tämä on saatavilla edellä taulukossa 3, tai voidaan ladata a .csv-tiedosto. Mitä tilaa valitset, tallenna tiedosto VagrantsExampleData.csv. Jos käytät Mac varmista, että tallennat sen Windows-muodossa .csv-tiedosto. Avaa VagrantsExampleData.csv ja tutustu sen sisältöön. Sinun pitäisi huomata jokainen 32 maakunnat, yhdessä kunkin muuttujat olemme keskustelleet koko tämän opetusohjelma. Käytämme sarakkeen otsakkeita päästäksemme käsiksi näihin tietoihin tietokoneohjelmallamme. Olisin voinut kutsua heitä miksi tahansa, mutta tässä kansiossa he ovat:
vagrantspopulationdistancewheatwageswageTrajectory
samaan hakemistoon kuin tallennit csv-tiedoston, luo ja tallenna Uusi R-komentosarjatiedosto (voit tehdä tämän millä tahansa tekstieditorilla tai rstudiolla, mutta älä käytä tekstinkäsittelyohjelmaa kuten MS Word). Säästä se painolaskelmina.r.
kirjoitamme nyt lyhytohjelman, joka:
- asentaa MASSAPAKKAUKSEN
- kutsuu MASSAPAKKAUKSEN, joten voimme käyttää sitä koodissamme
- tallentaa sisällön .csv-tiedosto muuttujaan, jota voimme käyttää ohjelmallisesti
- ratkaisee gravitaatiomallin yhtälön datajoukon
- avulla laskennan tulokset.
jokainen näistä tehtävistä suoritetaan vuorollaan yhdellä koodirivillä
Kopioi yllä oleva koodi painolaskelmiisi.R tiedosto ja tallenna. Voit nyt ajaa koodin käyttämällä suosikkiympäristöäsi R (käytän rstudiota) ja laskennan tulosten pitäisi näkyä konsoli-ikkunassa (miltä tämä näyttää riippuu ympäristöstäsi). Voit joutua asettamaan R-ympäristösi työhakemiston hakemistoon, joka sisältää sinun .csv ja .R-tiedostot. Jos käytät Rstudiota, voit tehdä tämän valikoiden kautta (Session -> Set Working Directory -> Choose Directory). Voit myös saavuttaa saman komennolla:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundhuomaa, että rivi 4 on linja, joka ratkaisee yhtälön meille, käyttämällä glm.nb-funktio, joka on lyhenne sanoista ”generated linear model-negative Binomial”. Tämä linja vaatii useita panoksia:
- meidän muuttujia käyttäen sarakkeen otsikot kuten on kirjoitettu .csv-tiedosto sekä niille tehtävät kirjaukset (
vagrants, log(population), log(distance),wheat,wages,wageTrajectory). Jos ajaisit mallia omilla tiedoillasi, säätäisit nämä vastaamaan sarakkeesi otsakkeita tietokokonaisuudessasi. - missä koodi voi löytää tiedot – tässä tapauksessa rivillä 3 määrittelemämme muuttuja nimeltään
gravityModelData.
laskennan tuotokset näkyvät kuvassa 9:
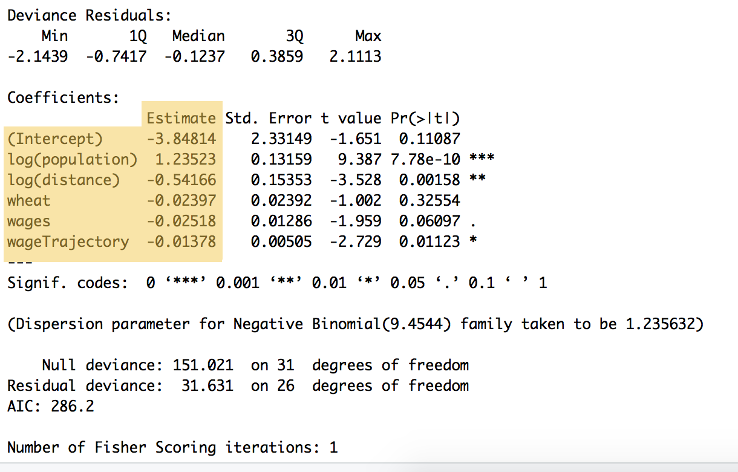
Kuva 9: edellä olevan koodin yhteenveto, jossa esitetään kunkin muuttujan ja y-leikkauspisteen painotukset, jotka on lueteltu ”Estimate” – otsikon alla ($\beta_{0}$ – $\beta_{5}$. Tässä yhteenvedossa esitetään myös useita muita laskelmia, muun muassa tilastollinen merkitsevyys.
Vaihe 3: Laskemalla kunkin piirikunnan arviot
meidän on tehtävä tämä kerran jokaiselle 32 piirikunnalle.
tämän saattoi tehdä tieteellisellä laskimella, luomalla taulukkolaskentakaavan tai kirjoittamalla tietokoneohjelman. Voit tehdä tämän automaattisesti R: ssä, voit lisätä seuraavan koodiisi ja ajaa ohjelman uudelleen. Tämä for silmukka laskee odotetun irtolaisten määrän jokaisesta esimerkissä olevasta 32 piirikunnasta ja tulostaa tulokset nähtäväksi:
ymmärtämisen lisäämiseksi ehdotan, että tehdään yksi kreivikunta pitkällä kädellä. Tämä opetusohjelma käyttää Hertfordshire pitkän käden esimerkki (mutta prosessi on täsmälleen sama muille 31 maakunnat).
käyttämällä taulukon 3 Hertfordshiren tietoja ja taulukon 4 kunkin muuttujan painotuksia voimme nyt täydentää kaavaa, joka antaa tuloksen 95:
ensin vaihdetaan lukujen symbolit, jotka on otettu edellä mainituista taulukoista.
ala sitten laskea arvoja, jotta pääset estimaattiin. Muistaa matemaattinen järjestys toiminta, Kerro arvot ennen lisäämistä. Aloita siis laskemalla jokainen muuttuja (voit käyttää tähän tieteellistä laskinta):
seuraava vaihe on laskea luvut yhteen:
estimated vagrants = exp(4.56232408897)ja lopuksi, laskea eksponenttifunktio (käytä tieteellistä laskin):
estimated vagrants = 95.8059926832olemme pudottaneet loput ja julistaneet, että arvioitu määrä irtolaisia Hertfordshirestä tässä mallissa on 95. Muista maakunnista pitää tehdä samat laskelmat, joita voisi nopeuttaa taulukkolaskentaohjelmalla. Varmistaakseni, että voit tehdä sen uudelleen, Olen sisällyttänyt myös Buckinghamshiren numerot:
Hertfordshire
\
Buckinghamshire
\
suosittelen valitsemaan yhden toisen kreivikunnan ja laskemaan sen pitkällä kädellä ennen kuin siirryt eteenpäin, varmistaakseni, että voit tehdä laskelmat itse. Oikea vastaus on saatavilla taulukosta 5, jossa verrataan havaittuja arvoja (kuten näkyy primaarilähteen tietueessa) estimoituihin arvoihin (laskettuna painovoimamallillamme). ”Jäännös” on näiden kahden välinen ero, ja suuri ero viittaa odottamattomaan määrään irtolaisia, joita kannattaisi tarkastella lähemmin historiantutkijan hattu päässään.
| Kreivikunta | Havaittu Arvo | Arvioitu Arvo | Jäännösarvo |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornwall | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Warwickshire | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Vaihe 4-Historiallinen tulkinta
tässä vaiheessa mallintamisprosessi on valmis ja viimeinen vaihe on historiallinen tulkinta.
alkuperäinen julkaistu artikkeli, johon tämä tapaustutkimus perustui, on omistettu ensisijaisesti sen tulkitsemiseen, mitä mallintamisen tulokset merkitsevät käsityksellemme alemman luokan muuttoliikkeestä 1700-luvulla. Kuten kuvassa 5 olevasta kartasta näkyy, maassa oli osia, joita malli vahvasti ehdotti joko yli – tai alilähettämään alemman luokan siirtolaisia Lontooseen.
kirjoittajakollegat tarjosivat tulkintojaan siitä, miksi nämä kuviot ovat voineet ilmestyä. Nämä tulkinnat vaihtelivat paikkakunnittain. Nopeasti teollistuvilla Pohjois-Englannin alueilla, kuten Yorkshiressa ja Manchesterissa, paikalliset mahdollisuudet näyttivät antavan ihmisille vähemmän syitä lähteä, mikä johti odotettua vähäisempään muuttoon Lontooseen. Länsimaiden taantuvilla alueilla, kuten Bristolissa, Lontoon houkutus oli voimakkaampi, kun yhä useammat ihmiset lähtivät etsimään töitä pääkaupungista.
kaikki kuviot eivät olleet odotettuja. Koillisessa sijaitseva Northumberland osoittautui alueelliseksi poikkeamaksi, sillä se lähetti Lontooseen paljon enemmän (naispuolisia) siirtolaisia kuin odotimme näkevämme. Ilman mallin ulostuloja on epätodennäköistä, että olisimme ajatelleet harkita Northumberlandia lainkaan, varsinkin kun se oli niin kaukana metropolista ja oletimme, että sillä olisi heikot siteet Lontooseen. Näin malli tarjosi meille uutta todistusaineistoa tarkasteltavaksi historiantutkijoina ja muutti käsitystämme Lontoon ja Northumberlandin suhteesta. Täydellinen keskustelu havainnoistamme on luettavissa alkuperäisestä artikkelista.18
tiedon vieminen eteenpäin
kokeiltuasi tätä esimerkkiongelmaa sinulla pitäisi olla selkeä käsitys siitä, miten tätä esimerkkikaavaa käytetään, sekä siitä, onko gravitaatiomalli sopiva ratkaisu tutkimusongelmaasi. Sinulla on kokemusta ja sanastoa lähestyä ja keskustella gravitaatiomalleja sopivasti matemaattisesti lukutaitoinen yhteistyökumppani tarvittaessa, joka voi auttaa sinua mukauttamaan sen Oman tapaustutkimuksen.
jos olet onnekas, että sinulla on myös tietoja muuttajista, jotka muuttavat kahdeksastoista vuosisadan loppupuolelle Lontooseen ja haluat mallintaa sen käyttäen samoja viittä edellä lueteltua muuttujaa, tämä kaava toimisi, koska-on – täällä on helppo tutkimus jollekulle, jolla on oikeat tiedot. Malli ei kuitenkaan toimi vain Lontooseen muuttavia siirtolaisia koskevissa tutkimuksissa. Muuttujat voivat muuttua, eikä määränpään tarvitse olla Lontoo. Gravitaatiomallin avulla olisi mahdollista tutkia muuttoliikettä muinaiseen Roomaan eli 2000-luvun Bangkokiin, jos on aineistoa ja tutkimuskysymystä. Sen ei tarvitse olla edes maahanmuuton malli. Johdanto-osan kolumbialaista kahvia koskevassa tapaustutkimuksessa, jossa keskitytään kauppaan eikä muuttoliikkeeseen, taulukossa 6 esitetään, että samaa kaavaa voidaan käyttää muuttumattomana.
| kriteerit | Kahvin vienti esimerkki |
|---|---|
| yksi alkuperäpaikka | kahvin vienti Barranquillan satamasta Kolumbiasta |
| useita äärellisiä kohteita | läntisen pallonpuoliskon 21 maata 1950 |
| viisi selittävää muuttujaa | (1) Atlantin valtameren satamien lukumäärä vastaanottavassa maassa (2) mailia Kolumbiasta, (3) vastaanottavan maan bruttokansantuote, (4) kotimainen kahvinviljely tonneina, (5) kahvilat 10 000 ihmistä kohti |
gravitaatiomalleilla on pitkä historia akateemisessa stipendissä. Jotta voit käyttää yhtä tehokkaasti tutkimukseen, sinun täytyy ymmärtää niiden taustalla oleva perusteoria ja matematiikka ja syyt, että ne ovat kehittyneet sellaisina kuin ne ovat. On myös tärkeää ymmärtää niiden rajat ja edellytykset käyttää niitä oikein, joista joitakin käsiteltiin edellä. Voi myös auttaa tietää:
-
tässä esimerkissä käytetty painovoimamalli voi toimia vain suljetussa järjestelmässä. Edellä mainitussa mallissa oli vain 32 mahdollista lähtöpistettä, mikä mahdollisti mallin ajamisen 32 kertaa. Tuntematon tai äärettömän suuri määrä lähtöpisteitä (tai kohteita mallista riippuen) vaatisi erilaisen yhtälön.
-
gravitaatiomallikäsitys rakentuu myös siitä lähtökohdasta, että liikkeet (muuttoliike, kauppa jne.) perustuvat kokoelmaan vapaaehtoisia yksittäisiä päätöksiä, joihin ulkopuoliset tekijät saattavat vaikuttaa, mutta joita ne eivät täysin hallitse. Esimerkiksi vapaaehtoista muuttoa tai vapaasta tahdosta tehtyjä ostoja voitaisiin mallintaa tällä tekniikalla, mutta pakkomuutto, pakkomuutto tai luonnolliset prosessit, kuten lintujen muutto tai jokien virtaaminen, eivät välttämättä noudata samoja periaatteita ja siksi saatetaan tarvita toisenlaista mallia.
-
Gravitaatiomalleja voidaan käyttää populaatioiden mutta ei yksilöiden käyttäytymisen ennustamiseen, ja siksi datan mallintamisyrityksiin tulisi sisältyä suuri määrä liikkeitä tilastollisen merkitsevyyden varmistamiseksi.
on monia muitakin sudenkuoppia, mutta myös valtavia mahdollisuuksia. Toivon, että tämä painovoimamallin läpikäynti ja siihen liittyvä julkaistu tutkimus tekevät tästä tehokkaasta välineestä helpommin historioitsijoiden saatavilla. Jos suunnittelet käyttäväsi painovoimamallia tieteellisessä tutkimuksessasi, kirjoittaja suosittelee painokkaasti seuraavia artikkeleita:
kiitokset
kiitokset Angela Kedgleylle, Sarah Lloydille, Tim Hitchcockille, Joe Cozensille, Katrina Navickasille ja Leanne Calvertille tämän artikkelin aiempien luonnosten lukemisesta ja kommentoimisesta. Kiitos myös British Academy rahoittamisesta kirjallisesti workshop Bogotá, Kolumbia, jossa tämä artikkeli laadittiin. Ja lopuksi Adam Dennettille, joka esitteli minulle nämä ihmeelliset kaavat ja vapautti niiden potentiaalin historioitsijoille.