a változók beillesztésének számos rossz módja is van. A gravitációs modell csak akkor működik, ha minden változó megfelel a következő kritériumoknak:
- numerikus
- teljes
- megbízható
csak numerikus adatok
mivel a gravitációs modell matematikai egyenlet, minden bemeneti változónak számszerűnek kell lennie. Ez lehet szám (népesség), térbeli mérték (terület, távolság stb.), idő (órák Londontól gyalog), százalék (bérnövekedés/csökkenés), valutaérték (bérek shillingben) vagy a modellben részt vevő helyek valamilyen más mértéke.
a számoknak értelmesnek kell lenniük, és nem lehetnek névleges kategorikus változók, amelyek egy kvalitatív attribútum helyettesítőjeként működnek. Például nem lehet önkényesen hozzárendelni egy számot, és használni a modellben, ha a számnak nincs jelentése (pl. road quality = jó, vagy road quality = 4). Bár ez utóbbi számszerű, ez nem az útminőség mércéje. Ehelyett az átlagos utazási sebességet mérföld / órában használhatja az útminőség proxyjaként. Az, hogy az átlagsebesség az útminőség értelmes mércéje-e, rajtad múlik, hogy a tanulmány szerzőjeként meghatározzuk és megvédjük-e.
Általánosságban elmondható, hogy ha meg tudja mérni vagy megszámolni, akkor modellezheti.
csak teljes adatok
minden adatkategóriának léteznie kell minden érdekes ponthoz. Ez azt jelenti, hogy mind a 32 vizsgált megyének megbízható adatokkal kell rendelkeznie minden push and pull tényezőről. Nem lehetnek hiányosságok vagy üresek, például egy megye, ahol nincs átlagbér.
csak megbízható adatok
a “szemét be, szemét ki” számítástechnikai mondás a gravitációs modellekre is vonatkozik, amelyek csak annyira megbízhatóak, mint az elkészítésükhöz használt adatok. A megbízható forrásokból származó megbízható és megbízható történelmi adatok kiválasztásán túl számos olyan módszer létezik a hibák elkövetésére, amelyek értelmetlenné teszik a modell kimeneteit. Például érdemes megbizonyosodni arról, hogy a rendelkezésére álló adatok pontosan megegyeznek-e a területekkel (pl. megyei adatok a megyék képviseletére, nem városi adatok a megye képviseletére).
a vizsgálat időpontjától és helyétől függően nehéz lehet megbízható adatkészletet szerezni, amelyre a modellt alapozhatja. Minél hátrébb van a múltban egy tanulmány, annál nehezebb lehet. Hasonlóképpen, könnyebb lehet ilyen típusú elemzéseket végezni olyan társadalmakban, amelyek erősen bürokratikusak voltak, és jó fennmaradt papírnyomokat hagytak maguk után, például Európában vagy Észak-Amerikában.
az adatminőség biztosítása érdekében ebben az esettanulmányban minden változót megbízhatóan számítottak ki, vagy publikáltak lektorált múltbeli adatok (Lásd 1.táblázat). Pontosan hogyan állították össze ezeket az adatokat, olvasható az eredeti cikkben, ahol részletesen elmagyarázták.11
öt Modellváltozónk
a fenti elveket szem előtt tartva tetszőleges számú változót választhattunk volna, figyelembe véve, hogy mit tudtunk a migrációs lökés-húzási tényezőkről. Öt (5) pontot választottunk ki, amelyeket az alapján választottunk ki, hogy mit gondoltunk a legfontosabbnak, és amelyekről tudtuk, hogy megbízható adatokkal alátámaszthatók.
| változó | forrás |
|---|---|
| származási népesség | 1771 értékek, Wrigley,” angol megyei populációk”, 54-5.12 |
| távolság Londontól | szoftverrel számítva |
| a búza ára | Cannon and Brunt, “Heti Brit gabonaárak”13 |
| átlagos bérek a származási helyen | Hunt, “Industrialization and Regional Inequality”, PP. 965-6.14 |
| a bérek pályája | Hunt, “Industrialization and Regional Inequality”, PP. 965-6.15 |
1. táblázat: A modellben használt öt változó és mindegyik forrása a lektorált irodalomban
miután eldöntötte ezeket a változókat, Az eredeti tanulmány társszerzője, Adam Dennett úgy döntött, hogy átírja a képletet, hogy öndokumentálja, így könnyű volt megmondani, hogy mely bitek vonatkoznak mind az öt változóra. Ez az oka annak, hogy a fenti képlet másképp néz ki, mint az eredeti kutatási cikkben. Az új szimbólumok a 2. táblázatban láthatók:
két további változó $i$ és $j$, jelentése “a kiindulási ponton” és “Londonban”. A $WA_{i}$ azt jelenti, hogy” bérszintek a kiindulási ponton”, míg a $WA_{j}$ azt jelentené, hogy”bérszintek Londonban”. Ez a hét új szimbólum helyettesítheti a képletben szereplő általánosabb szimbólumokat:
\
ez most bőbeszédűbb és az előző egyenlet kissé öndokumentált változata. Mindkettő matematikailag pontosan ugyanúgy oldódik meg, mivel a változások pusztán felszínesek, és az emberi felhasználó javát szolgálják.
a kitöltött változó adatkészlet
annak érdekében, hogy a bemutató gyorsabb legyen, az 5 változó és a 32 megye mindegyikének adatait már összeállították és megtisztították, és a 3.táblázatban láthatók, vagy CSV fájlként letölthetők. Ez a táblázat tartalmazza az adott megye ismert csavargóinak számát is, amint az az elsődleges forrásrekordban megfigyelhető:
| megye | csavargók | $ d$ km-ig London | $P $ népesség (személyek) | $ Wa $ átlagbér (shilling) | $ WaT $ bér pálya 1767-95 (%változás) | $ Wh $ búza Ár (shilling) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornwall | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
a végső különbség e képlet és az eredeti cikkben használt képlet között az, hogy két változó erősebb kapcsolatban áll a csavargással, ha természetesen logaritmikusan ábrázolják. A populáció az eredetnél ($P$) és a származástól Londonig ($d$) való távolság. Ez azt jelenti, hogy a tanulmányban szereplő adatok esetében a regressziós vonal (néha a legjobban illeszkedő vonalnak nevezik) jobban illeszkedik, ha az adatokat naplózták, mint amikor még nem voltak. Ezt láthatja a 7. ábrán, a bal oldalon a nem naplózott népességszámokkal, a jobb oldalon a naplózott verzióval. A pontok közül több közelebb van a naplózott grafikon legjobban illeszkedő vonalához, mint a nem naplózott grafikonhoz.
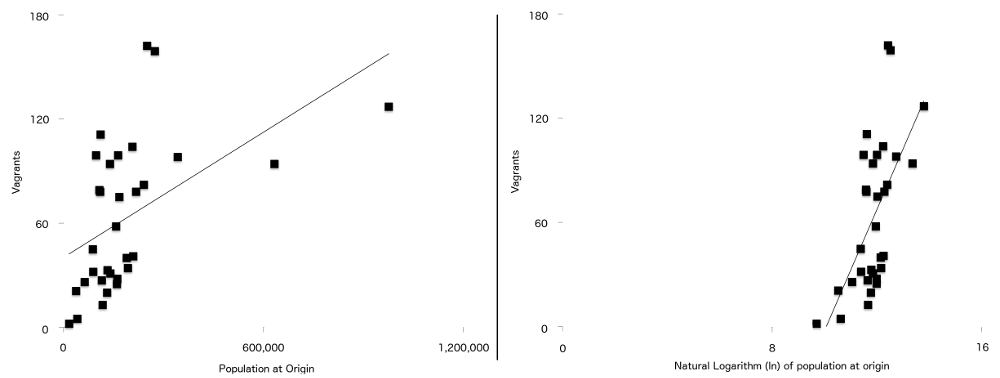
7. ábra: A csavargók száma ábrázolva a származási populációval szemben (balra), valamint a származási populáció természetes naplója (jobbra), mindkettőn egy egyszerű regressziós vonallal. Vegye figyelembe a második grafikonon látható két változó közötti erősebb kapcsolatot.
mivel ez a helyzet ezzel a konkrét adattal (a hasonló típusú vizsgálatban szereplő saját adatai nem feltétlenül követik ezt a mintát), a képletet úgy igazítottuk, hogy e két változó természetesen naplózott verzióit használja, ami a gravitációs modellben használt végső képletet eredményezte (8.ábra). Nem lehetett volna tudni, hogy szükség van erre a kiigazításra, amíg miután összegyűjtöttük a változó adatok:
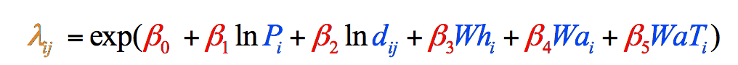
8. ábra: a gravitációs modell végső képlete lépésenként és színkóddal lebontva. A fekete elemek matematikai műveletek. A kék színű elemek a változóinkat képviselik, amelyeket éppen összegyűjtöttünk (1.lépés). A piros elemek az egyes változók súlyozását jelentik, amelyeket ki kell számolnunk (2.lépés), a narancssárga elem pedig az adott megye csavargóinak végső becslése, amelyet kiszámolhatunk, ha megvan a többi információ (3. lépés).
a 3. táblázat értékei megadnak mindent, amire szükségünk van a 8.ábra egyes egyenleteinek Kék részeinek kitöltéséhez. Most a piros részekre fordíthatjuk figyelmünket, amelyek megmutatják, hogy az egyes változók mennyire fontosak a modellben, és megadják azokat a számokat, amelyekre szükségünk van az egyenlet teljesítéséhez.
2. lépés: a súlyozások meghatározása
az egyes változók súlyozása megmondja, mennyire fontos ez a push/pull tényező a többi változóhoz képest, amikor megpróbáljuk megbecsülni az adott megyéből származó csavargók számát. Az ismert adatokból a teljes adathalmazon belül meg kell határozni a $adapterek$ paramétereit. Ezekkel a kezekkel képesek leszünk összehasonlítani az egyes eredet – specifikus megfigyeléseket az Általános modellel. Ezután megvizsgálhatjuk ezeket, és azonosíthatjuk a különböző eredet és cél közötti előre jelzett áramlásokat.
ebben a szakaszban nem tudjuk, mennyire fontosak. Talán a búza ára jobban előrejelzi a migrációt, mint a távolság? Nem fogjuk tudni, amíg nem számítjuk ki a $6$ – tól $5$ – ig terjedő értékeket (a súlyokat) a fenti egyenlet megoldásával. Az y-intercept ($++0$) csak akkor lehet kiszámítani, ha tudod, hogy az összes többi ($6-1-5$). Ezek a fenti 8. ábra piros értékei. A súlyozás az eredeti papír 4. és A1. táblázatában látható.16 most bemutatjuk, hogyan jutottunk el ezekhez az értékekhez.
ezen értékek kiszámításához a hosszú kéz hihetetlen mennyiségű munkát igényel. Gyors megoldást fogunk használni az R programozási nyelvben, amely kihasználja William Venables és Brian Ripley TÖMEGCSOMAGJÁT, amely egyetlen kódsorral képes megoldani a negatív binomiális regressziós egyenleteket, mint például a gravitációs modellünk. Fontos azonban megérteni a mögöttes alapelveket, hogy értékeljük, mit csinál a kód (vegye figyelembe, hogy a következő szakaszok nem a számítást végzik, hanem elmagyarázzák annak lépéseit az Ön számára; a számítást az oldalon lejjebb lévő kóddal fogjuk elvégezni).
az egyes súlyozások kiszámítása (elvileg)
$ons_{1}$, $ca__{2}$, stb.ugyanazok, mint $$ $$ a fenti egyszerű lineáris regressziós modellben, ami a regressziós egyenes meredeksége (a futás közbeni emelkedés, vagy mennyi $y$ nő, ha $ x $ 1-gyel nő). Az egyetlen különbség az egyszerű lineáris regresszió és a gravitációs modell között az, hogy 5 lejtőt kell kiszámolnunk 1 helyett.
egy egyszerű lineáris regresszió\(y = 6 + + x\)
mind az öt lejtőn meg kell oldanunk, mielőtt kiszámolhatnánk az y-metszést a következő lépésben. Ez azért van, mert a lejtők a különböző $6$ értékek részét képezik az egyenlet kiszámításához y-metszéspont.
a regresszióanalízisben a $6$ számításának képlete a következő:
\
Pearson korrelációs együtthatója
Pearson korrelációs együtthatója hosszú kézzel kiszámítható, de ebben az esetben meglehetősen hosszú számítás, 64 számot igényel. Van néhány nagyszerű angol nyelvű oktatóvideó, amely online elérhető, ha szeretné áttekinteni, hogyan kell hosszú kézzel elvégezni a számításokat.17 számos online számológép is létezik, amelyek kiszámítják az $r$ – t az Ön számára, ha megadja az adatokat. Tekintettel a kiszámítandó számjegyek nagy számára, javasolnék egy weboldalt, amelynek beépített eszköze van a számítás elvégzéséhez. Ügyeljen arra, hogy jó hírű webhelyet válasszon, például egy egyetem által kínált webhelyet.
$s_{y}$ & $s_{x}$ (szórás)
a szórás annak kifejezésére szolgál, hogy mennyi eltérés van az adatokban az átlagtól (átlagtól). Más szavakkal, az adatok meglehetősen csoportosulnak-e az átlag körül, vagy a terjedés sokkal szélesebb?
ismét vannak online számológépek és statisztikai szoftvercsomagok, amelyek elvégezhetik ezt a számítást az Ön számára, ha megadja az adatokat.
kiszámítás $enterprise_{0}$ (az y-elfogás)
ezután ki kell számolnunk az y-elfogást. Az y-elfogás egyszerű lineáris regresszióban történő kiszámításának képlete:
\
a többszörös regresszióanalízis során azonban a számítás sokkal bonyolultabbá válik, mivel minden változó befolyásolja a számítást. Ez nagyon megnehezíti a kézi munkát, és ez az egyik oka annak, hogy a programozott megoldást választjuk.
a súlyozás kiszámításának kódja
az R programozási nyelvhez írt tömeges statisztikai csomag olyan funkcióval rendelkezik, amely képes megoldani a negatív binomiális regressziós egyenleteket, így nagyon könnyű kiszámítani azt, ami egyébként nagyon nehéz hosszú kéz képlet lenne.
ez a szakasz feltételezi, hogy telepítette az R-t és telepítette a MASS csomagot. Ha még nem tette meg, akkor a folytatás előtt meg kell tennie. Taryn Dewar bemutatója az R alapokról táblázatos adatokkal tartalmazza az R telepítési utasításokat.
a kód használatához le kell töltenie az öt változó adatkészletének másolatát, valamint a 32 megye mindegyikéből megfigyelt csavargók számát. Ez elérhető a fenti táblázat 3, vagy lehet letölteni, mint egy .csv fájl. Bármelyik módot is választja, mentse el a fájlt VagrantsExampleData néven.csv. Ha Mac-et használ, győződjön meg róla, hogy Windows formátumban mentette.csv fájl. Nyissa Meg A VagrantsExampleData-T.csv és ismerkedjen meg annak tartalmát. Észre kell vennie a 32 megye mindegyikét, az egyes változókkal együtt, amelyeket ebben az oktatóanyagban tárgyaltunk. Az oszlopfejléceket fogjuk használni ezen adatok eléréséhez számítógépes programunkkal. Bárminek hívhattam volna őket, de ebben a fájlban vannak:
vagrantspopulationdistancewheatwageswageTrajectory
a csv fájl mentésével megegyező könyvtárban hozzon létre és mentsen el egy új R szkriptfájlt (ezt bármilyen szövegszerkesztővel vagy RStudio-val megteheti, de ne használjon olyan szövegszerkesztőt, mint az MS Word). Mentse el súlyszámításként.r.
most írunk egy rövid programot, amely:
- telepíti a tömeges csomag
- felhívja a tömeges csomag, így tudjuk használni a kódot
- tárolja a tartalmát a .csv fájl egy változóhoz, amelyet programozottan használhatunk
- megoldja a gravitációs modell egyenletét a
- adatkészlet segítségével adja ki a számítás eredményeit.
ezeket a feladatokat egymás után egyetlen kódsorral lehet elérni
másolja a fenti kódot a súlyszámításokba.r fájl és mentés. Most már futtathatja a kódot a kedvenc R környezetével (az RStudio-t használom), és a számítás eredményeinek meg kell jelenniük a konzolablakban (hogy ez hogyan néz ki, az a környezettől függ). Lehet, hogy be kell állítania az R környezet Munkakönyvtárát az Ön könyvtárát tartalmazó könyvtárba .csv és .r fájlok. Ha RStudio-t használ, ezt a menük segítségével teheti meg (munkamenet- > munkakönyvtár beállítása – > Könyvtár kiválasztása). Ugyanezt a paranccsal is elérheti:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundfigyeljük meg, hogy a 4. sor az a vonal, amely megoldja számunkra az egyenletet a glm használatával.nb függvény, amely az “általánosított lineáris modell – negatív binomiális” rövidítése. Ez a sor számos bemenetet igényel:
- változóink az oszlopfejléceket használva, a .csv fájl, valamint minden naplózást, amelyet nekik kell elvégezni (
vagrants, log(population), log(distance),wheat,wages,wageTrajectory). Ha saját adatokkal rendelkező modellt futtatna, ezeket úgy módosítaná, hogy tükrözze az oszlopfejléceket az adatkészletben. - ahol a kód megtalálja az adatokat – ebben az esetben egy változót, amelyet a 3.sorban definiáltunk, az úgynevezett
gravityModelData.
a számítás kimenetei az ábrán láthatók 9:
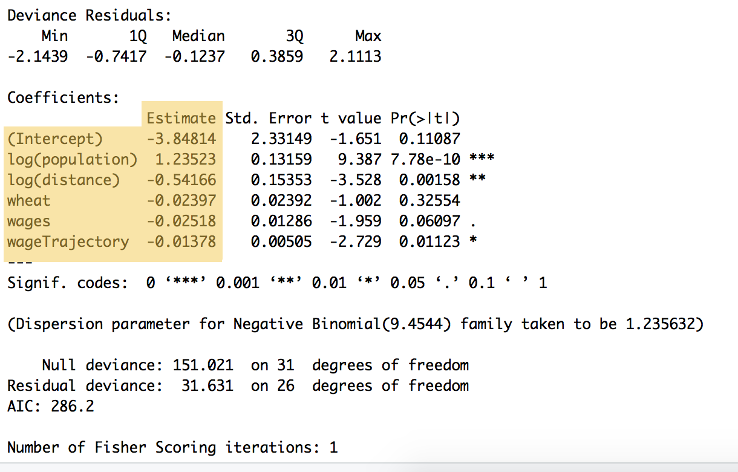
9. ábra: a fenti kód összefoglalása, amely bemutatja az egyes változók és az y-intercept súlyozását ,a ‘becslés’ címsor alatt ($\beta_{0}$ to $ \ beta_{5}$. Ez az összefoglaló számos más számítást is mutat, beleértve a statisztikai szignifikanciát is.
3. lépés: Az egyes megyékre vonatkozó becslések kiszámítása
ezt a 32 megye mindegyikére egyszer meg kell tennünk.
ezt tudományos számológéppel, táblázatkezelő képlet létrehozásával vagy számítógépes program írásával teheti meg. Ha ezt automatikusan meg szeretné tenni az R-ben, hozzáadhatja a következő kódot a kódhoz, majd újra futtathatja a programot. Ez a for hurok kiszámítja a példában szereplő 32 megye mindegyikének várható számát, és kinyomtatja az eredményeket, hogy láthassa:
a megértés kiépítéséhez azt javaslom, hogy végezzen egy megyei hosszú kezet. Ez a bemutató fogja használni Hertfordshire, mint a hosszú kéz például (de a folyamat pontosan ugyanaz a többi 31 megyében).
a 3.táblázatban szereplő Hertfordshire-re vonatkozó adatok és a 4. táblázatban szereplő minden változó súlyozása alapján most kiegészíthetjük képletünket, amely 95 eredményt ad:
először cseréljük ki a számok szimbólumait, amelyeket a fent említett táblázatokból vettünk.
ezután kezdje el kiszámítani az értékeket, hogy elérje a becslést. Emlékezve a műveletek matematikai sorrendjére, szorozza meg az értékeket a hozzáadás előtt. Tehát kezdje az egyes változók kiszámításával (ehhez tudományos számológépet használhat):
a következő lépés a számok összeadása:
estimated vagrants = exp(4.56232408897)végül az exponenciális függvény kiszámításához (használjon tudományos számológépet):
estimated vagrants = 95.8059926832a fennmaradó részt elvetettük, és kijelentettük, hogy a hertfordshire-i csavargók becsült száma ebben a modellben 95. Ugyanazokat a számításokat kell elvégeznie a többi megyében, amelyeket egy táblázatkezelő program segítségével felgyorsíthat. Csak azért, hogy biztosan meg tudja csinálni újra, már is szerepel a számok Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
azt javaslom, válasszon egy másik megyében, és kiszámítja hosszú kézzel, mielőtt továbblépne, hogy győződjön meg róla, yourcan csinálni a számításokat a saját. A helyes válasz az 5. táblázatban található, amely összehasonlítja a megfigyelt értékeket (amint az az elsődleges forrásrekordban látható) a becsült értékekkel (a gravitációs modellünk alapján számítva). A “maradék” a kettő közötti különbség, nagy különbség arra utal, hogy váratlan számú csavargó van, amelyet érdemes közelebbről megvizsgálni, ha a történész kalapja van.
| Megye | Megfigyelt Érték | Becsült Érték | Maradék |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornwall | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Warwickshire | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
4. lépés-Történeti értelmezés
ebben a szakaszban a modellezési folyamat befejeződött, az utolsó szakasz pedig a történeti értelmezés.
az esettanulmány alapjául szolgáló eredeti cikk elsősorban annak értelmezésére szolgál, hogy a modellezés eredményei mit jelentenek a XVIII.századi alsóbb osztályú migráció megértéséhez. Amint az ábrán látható térképen látható 5, voltak olyan országrészek, amelyeket a modell erősen javasolt, vagy túl – vagy alul-alacsonyabb osztályú migránsokat küldtek Londonba.
a társszerzők felajánlották értelmezéseiket arról, hogy miért jelentek meg ezek a minták. Ezek az értelmezések helyenként változtak. Észak-Anglia olyan területein, amelyek gyorsan iparosodtak, mint például Yorkshire vagy Manchester, úgy tűnt, hogy a helyi lehetőségek kevesebb okot adnak az embereknek a távozásra, ami a vártnál alacsonyabb migrációt eredményez Londonba. A nyugat felé hanyatló területeken, mint pl Bristol, London csábítása erősebb volt, mivel többen távoztak munkát keresni a fővárosban.
nem minden minta várható. A Távol-északkeleti Northumberland regionális anomáliának bizonyult, sokkal több (női) migránst küldött Londonba, mint azt várnánk. A modell eredményei nélkül nem valószínű, hogy egyáltalán gondoltunk volna Northumberlandre, különösen azért, mert olyan messze volt a metropolisztól, és feltételeztük, hogy gyenge kapcsolatai lennének Londonnal. A modell tehát új bizonyítékokat szolgáltatott számunkra, hogy történészként figyelembe vegyük, és megváltoztatta a London-Northumberland kapcsolat megértését. Eredményeink teljes megvitatása az eredeti cikkben olvasható.18
a tudás továbbvitele
miután kipróbálta ezt a példaproblémát, világosan meg kell értenie, hogyan kell használni ezt a példaképletet, valamint azt, hogy a gravitációs modell megfelelő megoldás lehet-e a kutatási problémára. Megvan a tapasztalata és szókincse, hogy megközelítse és megvitassa a gravitációs modelleket egy megfelelő matematikailag írástudó munkatárssal, aki segíthet abban, hogy alkalmazkodjon a saját esettanulmányához.
ha elég szerencsés ahhoz, hogy a tizennyolcadik század végén Londonba költöző migránsokról is rendelkezzen adatokkal, és ugyanazt az öt fent felsorolt változót szeretné modellezni, ez a képlet úgy működik, ahogy van-itt van egy könnyű tanulmány valakinek, aki megfelelő adatokkal rendelkezik. Ez a modell azonban nem csak a Londonba költöző migránsokról szóló tanulmányoknál működik. A változók változhatnak, és a cél nem feltétlenül London. Lehetséges lenne gravitációs modellt használni az ókori Rómába vagy a huszonegyedik századi Bangkokba való migráció tanulmányozására, ha megvan az adat és a kutatási kérdés. Nem is kell, hogy a migráció modellje legyen. A bevezetésből származó Kolumbiai Kávé esettanulmány felhasználásához, amely a kereskedelemre, nem pedig a migrációra összpontosít, a 6.táblázat ugyanazon képlet életképes, változatlan felhasználását mutatja.
| kritériumok | kávé exportálási példa |
|---|---|
| egy származási hely | kávéexport a kolumbiai Barranquilla kikötőjéből |
| több véges célállomás | a nyugati félteke 21 országa 1950 |
| öt magyarázó változó | (1) Az Atlanti-óceán kikötőinek száma a fogadó országban (2) mérföldre Kolumbiától, (3) a fogadó ország bruttó hazai terméke, (4) tonnában termesztett hazai Kávé, (5) kávézók 10 000 főre |
van egy hosszú története gravitációs modellek tudományos ösztöndíj. Ahhoz, hogy hatékonyan használhassa a kutatást, meg kell értenie a mögöttük álló alapvető elméletet és matematikát, valamint az általuk kifejlesztett okokat. Fontos megérteni a megfelelő használatuk korlátait és feltételeit is, amelyek közül néhányat a fentiekben tárgyaltunk. Az is segíthet, ha tudjuk:
-
az ebben a példában használt gravitációs modell csak zárt rendszerben működhet. A fenti modellnek csak 32 lehetséges kiindulási pontja volt, ami lehetővé tette a modell 32-szer történő futtatását. Ismeretlen vagy végtelenül nagy számú kiindulási pont (vagy úticél a modelltől függően) más egyenletet igényelne.
-
a gravitációs modell koncepciója arra a feltevésre is épül, hogy a mozgások (migráció, kereskedelem stb.) önkéntes egyéni döntések gyűjteményén alapulnak, amelyeket külső tényezők befolyásolhatnak, de nem teljesen irányítanak. Például az önkéntes vándorlások vagy a szabad akaratból végrehajtott vásárlások modellezhetők ezzel a technikával, de a kényszerű migráció, a kötelező vásárlás vagy a természetes folyamatok, például a madarak vándorlása vagy a folyók áramlása nem feltétlenül követik ugyanazokat az elveket, ezért más típusú modellre lehet szükség.
-
a gravitációs modellek felhasználhatók a populációk viselkedésének előrejelzésére, de az egyének nem, ezért az adatok modellezésére tett kísérleteknek nagyszámú mozgást kell tartalmazniuk A statisztikai szignifikancia biztosítása érdekében.
sokkal több buktató van, de óriási lehetőségek is vannak. Remélem, hogy a gravitációs modell ezen áttekintése és az azt kísérő közzétett kutatások ezt a hatékony eszközt hozzáférhetőbbé teszik a történészek számára. Ha azt tervezi, hogy használja a gravitációs modell a tudományos kutatás, a szerző erősen ajánlja a következő cikkeket:
Köszönetnyilvánítás
köszönet Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas, és Leanne Calvert olvasni és kommentálta a korábbi tervezetek ezt a cikket. Köszönet a brit Akadémiának is, hogy finanszírozta az íróműhelyt Bogotban, Kolumbiában, ahol ezt a cikket megfogalmazták. És végül Adam Dennett-nek, hogy bemutatta nekem ezeket a csodálatos képleteket, és felszabadította a lehetőségeket a történészek számára.