gyengéd Bevezetés Az automatikus Kódolóba és néhány gyakori felhasználási esetébe a Python kóddal
háttér:
az Autoencoder egy felügyelet nélküli mesterséges neurális hálózat, amely megtanulja, hogyan kell hatékonyan tömöríteni és kódolni az adatokat, majd megtanulja, hogyan kell rekonstruálni az adatokat a csökkentett kódolt ábrázolásból egy olyan reprezentációvá, amely a lehető legközelebb áll az eredeti bemenethez.
az Autoencoder a tervezés során csökkenti az adatok dimenzióit azáltal, hogy megtanulja, hogyan hagyja figyelmen kívül az adatok zaját.
itt egy példa a bemeneti / kimeneti kép az MNIST adatkészletből egy autoencoderbe.
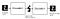
Autoencoder komponensek:
az Autoencoders 4 fő részből áll:
1 – Encoder: amelyben a modell megtanulja, hogyan csökkentse a bemeneti dimenziókat és tömörítse a bemeneti adatokat egy kódolt ábrázolásba.
2-szűk keresztmetszet: ez az a réteg, amely a bemeneti adatok tömörített ábrázolását tartalmazza. Ez a bemeneti adatok lehető legalacsonyabb mérete.
3 – dekóder: amelyben a modell megtanulja, hogyan kell rekonstruálni az adatokat a kódolt ábrázolásból, hogy a lehető legközelebb legyenek az eredeti bemenethez.
4 – rekonstrukciós veszteség: ez az a módszer, amely méri, hogy a dekóder milyen jól teljesít, és milyen közel van a kimenet az eredeti bemenethez.
ezután a képzés magában foglalja a hátsó terjedés használatát a hálózat rekonstrukciós veszteségének minimalizálása érdekében.
meg kell tudni, hogy miért lenne a vonat egy neurális hálózat csak a kimenet egy kép vagy adat, amely pontosan ugyanaz, mint a bemenet! Ez a cikk az Autoencoder leggyakoribb használati eseteit ismerteti. Kezdjük el:
Autoencoder architektúra:
az autoencoderek hálózati architektúrája a használati esettől függően változhat egy egyszerű előremutató hálózat, LSTM hálózat vagy konvolúciós neurális hálózat között. Néhány ilyen architektúrát az új következő néhány sorban fogunk felfedezni.
számos módszer és technika létezik az anomáliák és kiugró értékek kimutatására. Az alábbiakban egy másik bejegyzésben foglalkoztam ezzel a témával:
Ha azonban Korrelált bemeneti adatok vannak, akkor az autoencoder módszer nagyon jól fog működni, mert a kódolási művelet a korrelált funkciókra támaszkodik az adatok tömörítéséhez.
tegyük fel, hogy betanítottunk egy autoencodert az MNIST adatkészletre. Egy egyszerű FeedForward neurális hálózat, tudjuk elérni ezt az épület egy egyszerű 6 rétegű hálózat az alábbiak szerint:
a fenti kód kimenete:
mint látható a kimeneten, az utolsó rekonstrukciós veszteség/hiba az érvényesítési készlet 0.0193 ami nagyszerű. Most, ha bármilyen normál képet átadok az MNIST adatkészletből, a rekonstrukciós veszteség nagyon alacsony lesz (< 0,02), de ha bármilyen más képet (kiugró vagy anomáliát) próbáltam átadni, akkor magas rekonstrukciós veszteségértéket kapunk, mert a hálózat nem tudta rekonstruálni az anomáliának tekintett képet/bemenetet.
megjegyzés a fenti kódban csak a kódoló részt használhatja egyes adatok vagy képek tömörítésére, a dekóder részt pedig csak az adatok kibontására használhatja a dekóder rétegek betöltésével.
most csináljunk egy kis anomáliát. Az alábbi kód két különböző képet használ az anomália pontszám (rekonstrukciós hiba) előrejelzésére a fent képzett autoencoder hálózat segítségével. az első kép az MNIST-től származik, az eredmény 5.43209. Ez azt jelenti, hogy a kép nem anomália. A második kép, amelyet használtam, egy teljesen véletlenszerű kép, amely nem tartozik a képzési adatkészlethez, és az eredmények: 6789.4907. Ez a nagy hiba azt jelenti, hogy a kép anomália. Ugyanez a koncepció vonatkozik bármilyen típusú adatkészletre.