mint adat tudós a fogyasztói iparban, amit általában úgy érzem, fellendítése algoritmusok elég a legtöbb prediktív tanulási feladatok, legalábbis most. Ezek erőteljes, rugalmas és lehet értelmezni szépen néhány trükköt. Ezért úgy gondolom, hogy át kell olvasni néhány anyagot, és írni valamit a növelő algoritmusokról.
a legtöbb tartalom ebben acticle alapul papír: fa növelése az XGBoost: miért XGBoost nyerni “minden” gépi tanulási verseny?. Ez egy nagyon informatív papír. Szinte mindent, ami az algoritmusok növelését illeti, nagyon világosan elmagyarázza a cikk. Tehát a dolgozat 110 oldalt tartalmaz : (
számomra alapvetően a három legnépszerűbb növelő algoritmusra összpontosítok: AdaBoost, GBM és XGBoost. A tartalmat két részre osztottam. Az első cikk (ez) az AdaBoost algoritmusra összpontosít,a második pedig a GBM és az XGBoost összehasonlítására.
az Adaboost, az “Adaptive Boosting” rövidítése, az első gyakorlati boosting algoritmus, amelyet Freund és Schapire javasolt 1996-ban. Az osztályozási problémákra összpontosít, és arra törekszik, hogy a gyenge osztályozókat erőssé alakítsa. A besorolás végső egyenlete a következőképpen ábrázolható
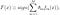
ahol f_m az m_th gyenge osztályozót jelenti, theta_m pedig a megfelelő súly. Pontosan az M gyenge osztályozók súlyozott kombinációja. Az AdaBoost algoritmus teljes eljárása a következőképpen foglalható össze.
AdaBoost algoritmus
n pontot tartalmazó adathalmazt adott, ahol

itt -1 a negatív osztályt jelöli, míg 1 a pozitív.
az egyes adatpontok súlyának inicializálása:

iterációhoz m=1,…, M:
(1) illessze a gyenge osztályozókat az adatkészletbe, és válassza ki a legalacsonyabb súlyozott osztályozási hibával rendelkező osztályozót:

(2) Számítsa ki az m_th gyenge osztályozó súlyát:

minden 50% – nál nagyobb pontosságú osztályozó esetében a súly pozitív. Minél pontosabb az osztályozó, annál nagyobb a súly. Míg az 50% – nál kisebb pontosságú osztályozó esetében a súly negatív. Ez azt jelenti, hogy kombináljuk előrejelzését a jel megfordításával. Például egy 40% – os pontosságú osztályozót 60% – os pontossággá alakíthatunk az előrejelzés jelének megfordításával. Így még az osztályozó rosszabbul teljesít, mint a véletlenszerű találgatás, mégis hozzájárul a végső előrejelzéshez. Csak nem akarunk olyan osztályozót, amely pontos 50% – os pontossággal rendelkezik, ami nem ad hozzá semmilyen információt, így nem járul hozzá a végső előrejelzéshez.
(3) Az egyes adatpontok súlyának frissítése:

ahol Z_m egy normalizálási tényező, amely biztosítja, hogy az összes példánysúly összege egyenlő legyen 1-vel.
ha egy rosszul Osztályozott eset pozitív súlyozott osztályozóból származik, akkor a számlálóban az “exp” kifejezés mindig nagyobb, mint 1 (y*f mindig -1, theta_m pozitív). Így a tévesen besorolt eseteket iteráció után nagyobb súlyokkal frissítik. Ugyanez a logika vonatkozik a negatív súlyozott osztályozókra is. Az egyetlen különbség az, hogy az eredeti helyes besorolások téves besorolásokká válnak a jel megfordítása után.
M iteráció után megkaphatjuk a végső előrejelzést az egyes osztályozók súlyozott előrejelzésének összegzésével.
AdaBoost as a Forward Stagewise Additive Model
ez a rész papíron alapul: Additive logistic regression: a boosting statisztikai nézete. Részletesebb információkért kérjük, olvassa el az eredeti papírt.
2000-ben Friedman et al. az AdaBoost algoritmus statisztikai nézetét fejlesztette ki. Az AdaBoost-ot szakaszonkénti becslési eljárásként értelmezték egy additív logisztikai regressziós modell illesztésére. Megmutatták, hogy az AdaBoost valójában minimalizálja az exponenciális veszteség funkciót

ez minimálisra csökken

mivel az AdaBoost esetében y csak -1 vagy 1 lehet, A veszteségfüggvény átírható

folytassa az F(x) megoldását, megkapjuk

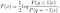
a normál logisztikai modellt tovább tudjuk levezetni az optimális megoldásból F (x):

ez majdnem megegyezik a logisztikai regressziós modell annak ellenére, hogy a tényező 2.
tegyük fel, hogy van egy aktuális becslésünk F(x) – re, és megpróbálunk egy javított becslést keresni F(x)+cf(x) – re. A fix c és x, tudjuk bővíteni L (y, F (x)+cf (x)) A másodrendű körülbelül f (x)=0,

így,

ahol E_w(./ x) súlyozott feltételes várakozást jelöl, és az egyes adatpontok súlyát a következőképpen számítják ki

ha c > 0, a súlyozott feltételes elvárás minimalizálása egyenlő a maximalizálással

mivel y csak 1 vagy -1 lehet, A súlyozott elvárás átírható

az optimális megoldás a következő

az f(x) meghatározása után a C tömeg kiszámítható az L(y, F(x)+cf(x))közvetlen minimalizálásával:

a c megoldása, megkapjuk


hagyja, hogy az epszilon egyenlő legyen a rosszul Osztályozott esetek súlyozott összegével, akkor

vegye figyelembe, hogy c negatív lehet, ha a gyenge tanuló rosszabbul jár, mint a véletlenszerű találgatás (50%), ban ben amely esetben automatikusan megfordítja a polaritást.
a példánysúlyok tekintetében a javított összeadás után az egyetlen példány súlya,

így a példány súlya frissül

összehasonlítva az AdaBoost algoritmusban használtakkal,

láthatjuk, hogy azonos formában vannak. Ezért ésszerű az AdaBoost-ot előre szakaszosan additív modellként értelmezni exponenciális veszteségfüggvény, amely iteratívan illeszkedik egy gyenge osztályozóhoz, hogy javítsa az aktuális becslést minden egyes iterációnál m:
