Utolsó frissítés: Augusztus 7, 2019
a szó beágyazása olyan szóábrázolás, amely lehetővé teszi a hasonló jelentésű szavak hasonló ábrázolását.
ezek a szöveg elosztott ábrázolása, amely talán az egyik legfontosabb áttörés a mély tanulási módszerek lenyűgöző teljesítményéhez a természetes nyelvi feldolgozási problémák kihívásában.
ebben a bejegyzésben felfedezheti a szöveges adatok ábrázolására szolgáló szó beágyazási megközelítést.
miután befejezte ezt a bejegyzést, tudni fogja:
- mi a szó beágyazási megközelítése a szöveg ábrázolásához, és miben különbözik a többi funkciókivonási módszertől.
- hogy 3 fő algoritmus létezik a szavak beágyazásának megtanulására a szöveges adatokból.
- hogy vagy a vonat egy új beágyazási vagy egy előre betanított beágyazási a természetes nyelv feldolgozási feladat.
indítsa el a projektet az új könyvemmel Deep Learning For Natural Language Processing, beleértve a lépésről-lépésre oktatóanyagokat és a Python forráskód fájlokat az összes példához.
kezdjük.

mik azok a szövegbe ágyazott szavak?
fotó: Heather, néhány jog fenntartva.
- áttekintés
- segítségre van szüksége a szöveges adatok mély tanulásához?
- mik azok a szó beágyazások?
- szó beágyazási algoritmusok
- beágyazási réteg
- Word2Vec
- GloVe
- a Word beágyazások használata
- Tanuljon beágyazást
- a beágyazások újrafelhasználása
- Melyik Opciót Használja?
- Word Embedding oktatóanyagok
- további olvasmányok
- cikkek
- papírok
- projektek
- Könyvek
- összefoglaló
- fejleszteni mély tanulási modellek szöveges adatok ma!
- percek alatt készítse el saját szöveges modelljeit
- végül hozza mély tanulás a természetes nyelv feldolgozó projektek
áttekintés
ez a bejegyzés 3 részre oszlik; ezek:
- mik azok a szó beágyazások?
- szó beágyazási algoritmusok
- szó beágyazások használata
segítségre van szüksége a szöveges adatok mély tanulásához?
vegye ki az ingyenes 7 napos e-mail gyorstalpaló most (kóddal).
kattintson a regisztrációhoz, és kap egy ingyenes PDF Ebook változata a tanfolyam.
indítsa el az ingyenes összeomlási tanfolyamot most
mik azok a szó beágyazások?
a szó beágyazása a szöveg tanult ábrázolása, ahol az azonos jelentésű szavak hasonló ábrázolással rendelkeznek.
a szavak és dokumentumok ábrázolásának ez a megközelítése tekinthető a mély tanulás egyik legfontosabb áttörésének a természetes nyelv feldolgozási problémáinak kihívásában.
a sűrű és alacsony dimenziós Vektorok használatának egyik előnye a számítási: a neurális hálózati eszközkészletek többsége nem játszik jól a nagyon nagy dimenziójú, ritka vektorokkal. … A sűrű ábrázolások fő előnye az általánosító erő: ha úgy gondoljuk, hogy egyes funkciók hasonló nyomokat adhatnak, érdemes olyan ábrázolást biztosítani, amely képes megragadni ezeket a hasonlóságokat.
— 92. oldal, neurális hálózati módszerek a természetes nyelv feldolgozásában, 2017.
a szavak beágyazása valójában olyan technikák osztálya, ahol az egyes szavakat valós értékű vektorként ábrázolják egy előre meghatározott vektortérben. Minden szó egy vektorhoz van hozzárendelve, és a vektorértékeket olyan módon tanulják meg, amely hasonlít egy neurális hálózatra, ezért a technika gyakran a mély tanulás területére kerül.
a megközelítés kulcsa az, hogy minden szóhoz sűrű elosztott ábrázolást használjunk.
minden szót valós értékű vektor képvisel, gyakran tíz vagy száz dimenzió. Ez ellentétben áll a ritka szóábrázolásokhoz szükséges ezer vagy millió dimenzióval, például egy forró kódolással.
a szókincs minden egyes szavához társítson egy elosztott szójellemző vektort … a jellemzővektor a szó különböző aspektusait képviseli: minden szó egy vektortér egy pontjához van társítva. A funkciók száma … sokkal kisebb , mint a szókincs mérete
— neurális valószínűségi nyelvi modell, 2003.
az elosztott ábrázolást a szavak használata alapján tanulják meg. Ez lehetővé teszi, hogy a hasonló módon használt szavak hasonló ábrázolásokat eredményezzenek, természetesen megragadva jelentésüket. Ez szembeállítható az éles, de törékeny ábrázolással egy zsák szavak modelljében, ahol-hacsak kifejezetten nem kezelik-a különböző szavak eltérő ábrázolással rendelkeznek, függetlenül attól, hogy hogyan használják őket.
a megközelítés mögött mélyebb nyelvi elmélet áll, nevezetesen Zellig Harris “disztribúciós hipotézise”, amelyet a következőképpen lehet összefoglalni: a hasonló kontextusú szavaknak hasonló jelentésük lesz. További mélységet lásd Harris 1956-os “Distributional structure”című cikkében.
ez a fogalom, amely lehetővé teszi a szó használatának meghatározását, összefoglalható John Firth gyakran ismételt quipjével:
ismerned kell egy szót a cégtől, amit tart!
— 11. oldal:” a nyelvelmélet összefoglalása 1930-1955″, a nyelvi elemzés tanulmányaiban 1930-1955, 1962.
szó beágyazási algoritmusok
szó beágyazási módszerek Ismerje meg a valós értékű vektor ábrázolása egy előre meghatározott fix méretű szókincs egy korpusz szöveget.
a tanulási folyamat vagy összekapcsolódik a neurális hálózati modellel valamilyen feladaton, például a dokumentum osztályozásán, vagy felügyelet nélküli folyamat, dokumentumstatisztikák felhasználásával.
ez a szakasz három olyan technikát ismertet meg, amelyek segítségével megtanulható egy szó beágyazása szöveges adatokból.
beágyazási réteg
a beágyazási réteg jobb név hiányában olyan szó beágyazása, amelyet egy neurális hálózati modellel közösen tanulnak meg egy adott természetes nyelv feldolgozási feladatán, például nyelvi modellezésen vagy dokumentum osztályozáson.
megköveteli, hogy a dokumentum szövegét úgy kell megtisztítani és előkészíteni, hogy minden szó egy forró kódolású legyen. A vektortér mérete a modell részeként van megadva, például 50, 100 vagy 300 dimenzió. A vektorokat kis véletlen számokkal inicializáljuk. A beágyazási réteget egy neurális hálózat elülső végén használják, és felügyelt módon illeszkedik a Backpropagation algoritmus segítségével.
… amikor a neurális hálózat bemenete szimbolikus kategorikus jellemzőket tartalmaz (pl. jellemzők, amelyek az egyiket veszik k különálló szimbólumok, például szavak egy zárt szókincsből), gyakori, hogy minden lehetséges tulajdonságértéket (azaz a szókincs minden szavát) társítanak a D-dimenziós vektor egyeseknél d. ezeket a vektorokat ezután a modell paramétereinek tekintjük, és a többi paraméterrel együtt képezzük őket.
— 49. oldal, neurális hálózati módszerek a természetes nyelv feldolgozásában, 2017.
az egyforró kódolású szavak a vektorokhoz vannak hozzárendelve. Ha többrétegű Perceptron modellt használunk, akkor a vektorok összefűződnek, mielőtt bemenetként betáplálnák a modellbe. Ha ismétlődő neurális hálózatot használunk, akkor minden szót egy bemenetnek tekinthetünk egy sorozatban.
a beágyazási réteg tanulásának ez a megközelítése sok képzési adatot igényel, és lassú lehet, de megtanulja a beágyazást mind az adott szöveges adatokra, mind az NLP feladatra.
Word2Vec
a Word2Vec egy statisztikai módszer egy önálló szó beágyazásának hatékony megtanulására egy szöveges korpuszból.
Tomas Mikolov, et al. a Google-nál 2013-ban válaszul arra, hogy hatékonyabbá tegye a beágyazások neurális hálózat alapú képzését, és azóta az előre betanított szó beágyazásának de facto szabványává vált.
ezenkívül a munka magában foglalta a tanult Vektorok elemzését és a vektor matematika feltárását a szavak ábrázolásán. Például, ha kivonjuk a” férfiasságot “a” Királyból”, és hozzáadjuk a” nősséget”, akkor a” királynő “szót kapjuk, megragadva a”király a királynőnek, mint a férfi a nőnek” analógiát.
megállapítottuk, hogy ezek a reprezentációk meglepően jól rögzítik a nyelv szintaktikai és szemantikai szabályszerűségeit, és hogy minden kapcsolatot relációspecifikus vektor eltolás jellemez. Ez lehetővé teszi a vektor-orientált érvelést a szavak közötti eltolások alapján. Például, a férfi / nő kapcsolat automatikusan megtanulják, és az indukált vektor ábrázolások, ” király-Férfi + Nő “eredményez vektor nagyon közel van a” királynő.”
— nyelvi szabályszerűségek a folyamatos Űrszórábrázolásokban, 2013.
két különböző tanulási modellt vezettek be, amelyek a word2vec megközelítés részeként használhatók a szó beágyazásának megtanulására; ezek:
- folyamatos Bag-of-szavak, vagy CBOW modell.
- Folyamatos Skip-Gram Modell.
a CBOW modell megtanulja a beágyazást azáltal, hogy megjósolja az aktuális szót annak kontextusa alapján. A folyamatos skip-gram modell megtanulja előrejelzésével a környező szavakat adott aktuális szót.
a folyamatos skip-gram modell megtanulja előrejelzésével a környező szavakat adott aktuális szót.
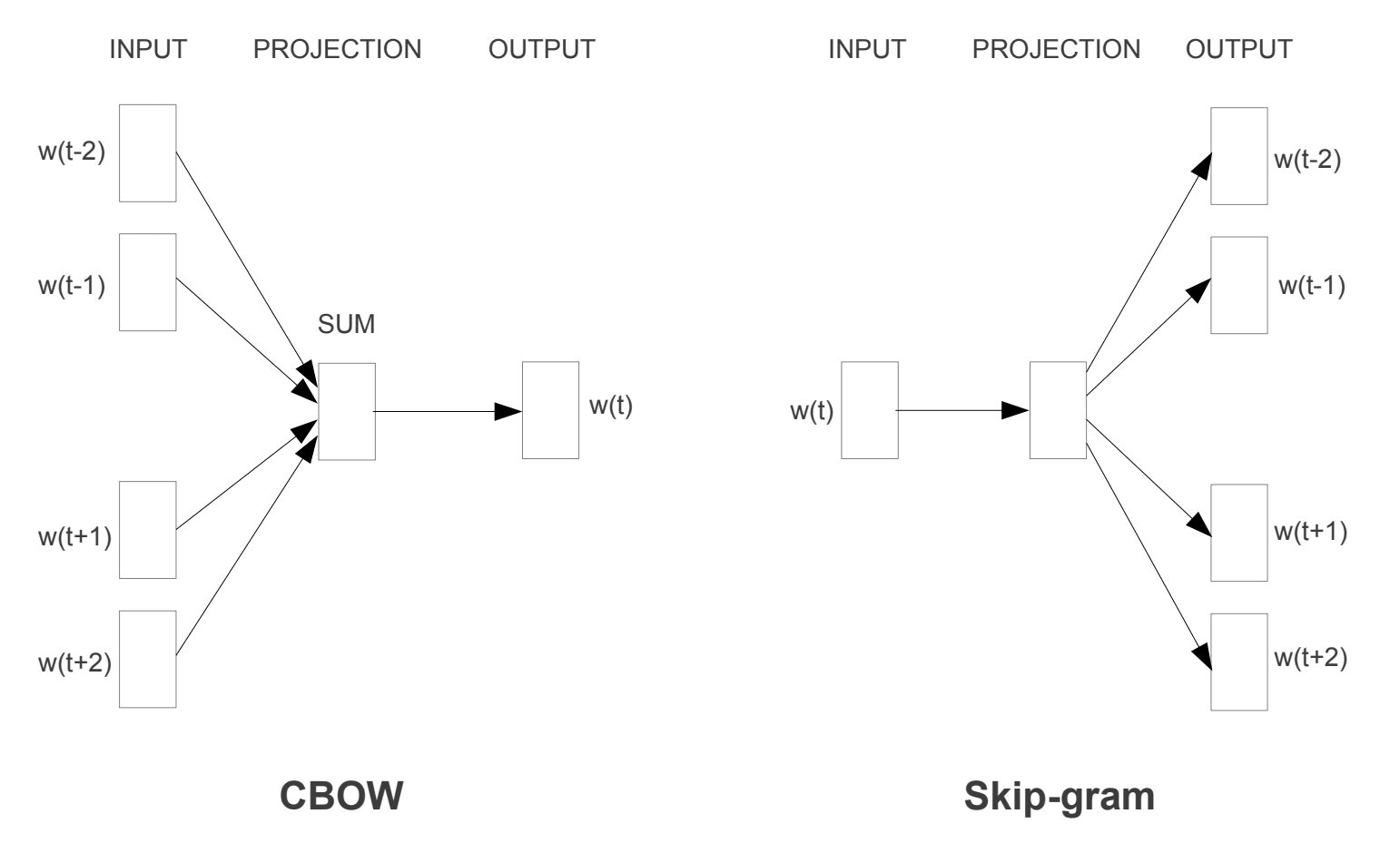
Word2Vec képzési modellek
vett “hatékony becslése szó reprezentációk vektortérben”, 2013
mindkét modell a szavak megismerésére összpontosít, tekintettel a helyi Használati kontextusra, ahol a kontextust a szomszédos szavak ablaka határozza meg. Ez az ablak a modell konfigurálható paramétere.
a tolóablak mérete erősen befolyásolja a kapott vektor hasonlóságokat. A nagy ablakok általában több aktuális hasonlóságot mutatnak, míg a kisebb ablakok inkább funkcionális és szintaktikai hasonlóságokat eredményeznek.
— 128. oldal, neurális hálózati módszerek a természetes nyelv feldolgozásában, 2017.
a megközelítés legfontosabb előnye, hogy a jó minőségű szó beágyazások hatékonyan megtanulhatók (alacsony tér-és időösszetétel), lehetővé téve a nagyobb beágyazások megtanulását (több dimenzió) sokkal nagyobb szöveges korpuszokból (több milliárd szó).
GloVe
a globális Vektorok szó reprezentáció, vagy kesztyű, algoritmus kiterjesztése a word2vec módszer hatékony tanulás szó vektorok által kifejlesztett Pennington, et al. a Stanfordon.
a szavak klasszikus vektortér-modell-reprezentációit olyan mátrixfaktorizációs technikákkal fejlesztették ki, mint a látens szemantikai elemzés (LSA), amelyek jó munkát végeznek a globális szöveges statisztikák használatában, de nem olyan jók, mint a tanult módszerek, mint a word2vec a jelentés rögzítésében és bemutatásában olyan feladatokon, mint az analógiák kiszámítása (pl. a király és a királyné példája).
a kesztyű olyan megközelítés, amely a mátrixfaktorizációs technikák, például az LSA globális statisztikáit a word2vec helyi kontextusalapú tanulásával veszi feleségül.
ahelyett, hogy ablakot használna a helyi kontextus meghatározásához, a GloVe explicit szó-kontextust vagy szó-előfordulási mátrixot épít fel a teljes szöveges korpusz statisztikáinak felhasználásával. Az eredmény egy tanulási modell, amely általában jobb szó beágyazásokat eredményezhet.
GloVe, egy új globális log-bilineáris regressziós modell a felügyelet nélküli tanulás szó reprezentációk, amely felülmúlja más modellek szó analógia, szó hasonlóság, és elemzi entitás felismerési feladatokat.
— kesztyű: globális Vektorok a szó ábrázolásához, 2014.
a Word beágyazások használata
van néhány lehetőség, amikor eljön az ideje a word beágyazások használatának a természetes nyelvi feldolgozási projekten.
ez a szakasz felvázolja ezeket a lehetőségeket.
Tanuljon beágyazást
dönthet úgy, hogy megtanul egy beágyazó szót a problémájához.
ez nagy mennyiségű szöveges adatot igényel a hasznos beágyazások megtanulásához, például több millió vagy milliárd szó.
két fő lehetősége van a szó beágyazásának oktatásakor:
- tanulja meg önállóan, ahol egy modellt betanítanak a beágyazás megtanulására, amelyet később egy másik modell részeként mentenek és használnak a feladathoz. Ez egy jó megközelítés, Ha ugyanazt a beágyazást szeretné használni több modellben.
- Tanulj közösen, ahol a beágyazást egy nagy feladat-specifikus modell részeként tanulják meg. Ez akkor jó megközelítés, ha a beágyazást csak egy feladatra kívánja használni.
a beágyazások újrafelhasználása
gyakori, hogy a kutatók előre betanított szó beágyazásokat ingyenesen elérhetővé tesznek, gyakran megengedő licenc alatt, hogy azokat saját tudományos vagy kereskedelmi projektjeiben felhasználhassa.
például mind a word2vec, mind a GloVe word beágyazások ingyenesen letölthetők.
ezeket fel lehet használni a projekt helyett képzés saját beágyazások a semmiből.
két fő lehetősége van az előre betanított beágyazások használatakor:
- statikus, ahol a beágyazást statikus állapotban tartják, és a modell összetevőjeként használják. Ez egy megfelelő megközelítés, ha a beágyazás jól illeszkedik a problémához, és jó eredményeket ad.
- Frissítve, ahol az előre betanított beágyazást használják a modell vetéséhez, de a beágyazást a modell betanítása során közösen frissítik. Ez jó lehetőség lehet, ha a legtöbbet szeretné kihozni a modellből és beágyazni a feladatába.
Melyik Opciót Használja?
fedezze fel a különböző lehetőségeket, és ha lehetséges, tesztelje, hogy melyik adja a legjobb eredményt a problémáján.
talán kezdje gyors módszerekkel, például egy előre betanított Beágyazással, és csak akkor használjon új beágyazást, ha az jobb teljesítményt eredményez a problémán.
Word Embedding oktatóanyagok
ez a szakasz felsorol néhány lépésről-lépésre oktatóanyagot, amelyeket követhet a word embeddings használatához, és a word embedding-et a projektbe hozhatja.
- hogyan fejlesszünk szó beágyazásokat a Pythonban a Gensim segítségével
- Hogyan használjunk szó beágyazási rétegeket a mély tanuláshoz a Keras segítségével
- hogyan fejlesszünk ki mély CNN-t az érzelmek elemzéséhez (szöveg osztályozás)
további olvasmányok
ez a szakasz további forrásokat tartalmaz a témában, ha keres mélyebbre.
cikkek
- szó beágyazása a Wikipédiába
- Word2vec a Wikipédiába
- kesztyű a Wikipédiába
- áttekintés a szó beágyazásáról és kapcsolatáról az elosztási szemantikai modellekkel, 2016.
- Deep Learning, NLP és reprezentációk, 2014.
papírok
- disztribúciós szerkezet, 1956.
- Neurális Valószínűségi Nyelvi Modell, 2003.
- egységes architektúra a természetes nyelv feldolgozásához: mély neurális hálózatok Multitask tanulással, 2008.
- folyamatos tér nyelvi modellek, 2007.
- a szavak reprezentációjának hatékony becslése a vektortérben, 2013
- szavak és kifejezések elosztott reprezentációi és összetételük, 2013.
- kesztyű: globális Vektorok a szó ábrázolásához, 2014.
projektek
- word2vec a Google kódon
- kesztyű: globális Vektorok a szó ábrázolásához
Könyvek
- neurális hálózati módszerek a természetes nyelv feldolgozásában, 2017.
összefoglaló
ebben a bejegyzésben felfedezte a szó beágyazását, mint a szöveg ábrázolási módszerét a mély tanulási alkalmazásokban.
konkrétan megtanultad:
- mi a reprezentációs szöveg szó beágyazási megközelítése, és miben különbözik a többi jellemző kibontási módszertől.
- hogy 3 fő algoritmus létezik a szavak beágyazásának megtanulására a szöveges adatokból.
- hogy Ön vagy kiképezhet egy új beágyazást, vagy használhat egy előre betanított beágyazást a természetes nyelv feldolgozási feladatához.
van kérdése?
tegye fel kérdéseit az alábbi megjegyzésekben, és mindent megteszek, hogy válaszoljak.
fejleszteni mély tanulási modellek szöveges adatok ma!

percek alatt készítse el saját szöveges modelljeit
…csak néhány sor python kódot
fedezze fel, hogyan az én új Ebook:
mély tanulás természetes nyelvi feldolgozás
ez biztosítja önálló tanulás oktatóanyagok témákban, mint:
zsák-of-szavak, szó beágyazása, nyelvi modellek, felirat generáció, szöveg fordítás és még sok más…
végül hozza mély tanulás a természetes nyelv feldolgozó projektek
ugrás a tudósok. Csak Eredmények.
nézze meg, mi van benne