Last Updated on August7,2019
単語埋め込みは、類似の意味を持つ単語が類似の表現を持つことを可能にする単語表現の一種です。
これらはテキストの分散表現であり、挑戦的な自然言語処理問題に対する深い学習方法の印象的なパフォーマンスの重要なブレークスルーの一つで
この記事では、テキストデータを表現するための単語埋め込みアプローチを発見します。
この投稿を完了した後、あなたは知っているでしょう:
- テキストを表現するための単語埋め込みアプローチとは何か、それが他の特徴抽出方法とどのように異なるか。
- テキストデータから単語埋め込みを学習するための3つの主要なアルゴリズムがあること。
- 新しい埋め込みを訓練するか、自然言語処理タスクで事前に訓練された埋め込みを使用することができます。
ステップバイステップのチュートリアルやすべての例のPythonソースコードファイルを含む、私の新しい本Deep Learning for Natural Language Processingでプロジェクトを開始します。
始めましょう。

テキストの単語埋め込みとは何ですか?
写真:ヘザー、一部の権利を保有しています。
概要
この投稿は3つの部分に分かれています。:
- 単語の埋め込みとは何ですか?
- 単語埋め込みアルゴリズム
- 単語埋め込みを使用する
テキストデータの深層学習のヘルプが必要ですか?
今私の無料の7日間の電子メールクラッシュコースを取る(コード付き)。
クリックしてサインアップし、コースの無料のPDF電子ブック版を取得します。
今すぐ無料のクラッシュコースを開始
単語埋め込みとは何ですか?
単語の埋め込みは、同じ意味を持つ単語が類似した表現を持つテキストの学習された表現です。
言葉や文書を表現するこのアプローチは、挑戦的な自然言語処理問題に対する深い学習の重要なブレークスルーの一つと考えられるかもしれません。
高密度および低次元ベクトルを使用する利点の1つは計算です: ニューラルネットワークツールキットの大部分は、非常に高次元の疎ベクトルではうまく機能しません。 いくつかの特徴が同様の手がかりを提供すると思われる場合、これらの類似点を捉えることができる表現を提供することは価値があります。
— 92ページ、自然言語処理におけるニューラルネットワークメソッド、2017。
単語埋め込みは、実際には、個々の単語が事前に定義されたベクトル空間で実数値ベクトルとして表される技術のクラスです。 各単語は一つのベクトルにマッピングされ、ベクトル値はニューラルネットワークに似た方法で学習されるため、この技術は深い学習の分野に集中することが多い。
アプローチの鍵は、各単語に密な分散表現を使用するという考えです。
各単語は実数値ベクトルで表され、多くの場合数十または数百の次元で表されます。 これは、ワンスホットエンコーディングのようなスパースワード表現に必要な数千または数百万の次元とは対照的です。
語彙内の各単語に関連付ける分散単語特徴ベクトル…特徴ベクトルは単語のさまざまな側面を表します:各単語はベクトル空間内の点に関連付けられ 機能の数は…語彙のサイズよりもはるかに小さいです
— 神経確率論的言語モデル、2003年。
分散表現は、単語の使用法に基づいて学習されます。 これにより、同様の方法で使用される単語は、同様の表現を持ち、自然にその意味を捉えることができます。 これは、明示的に管理されていない限り、異なる単語がどのように使用されているかにかかわらず、異なる表現を持つ単語の袋モデルの鮮明ではあるが壊れやすい表現と対比することができます。
アプローチの背後には、より深い言語理論、すなわちZellig Harrisによる”分布仮説”があり、以下のように要約することができます。 詳細については、ハリスの1956年の論文”Distributional structure”を参照してください。
単語の使用法にその意味を定義させるというこの概念は、John Firthによる頻繁に繰り返される皮肉によって要約することができます:
あなたはそれが保持する会社によって単語を知っているものとします!
— 11ページ,”言語理論の概要1930-1955″,言語分析の研究で1930-1955,1962.
単語埋め込みアルゴリズム
単語埋め込みメソッドは、テキストのコーパスから定義済みの固定サイズの語彙の実数値ベクトル表現を学習します。
学習プロセスは、文書分類などのいくつかのタスクに関するニューラルネットワークモデルと共同であるか、文書統計を使用した教師なしプロセスで
このセクションでは、テキストデータから単語の埋め込みを学習するために使用できる三つのテクニックをレビューします。
埋め込み層
埋め込み層は、より良い名前の欠如のために、言語モデリングや文書分類などの特定の自然言語処理タスク上でニューラルネットワークモデ
各単語がワンホットエンコードされるように、文書テキストをクリーンアップして準備する必要があります。 ベクトル空間のサイズは、50次元、100次元、または300次元など、モデルの一部として指定します。 ベクトルは小さな乱数で初期化されます。 埋め込み層はニューラルネットワークのフロントエンドで使用され、逆伝播アルゴリズムを使用して教師ありの方法で適合されます。
… ニューラルネットワークへの入力にシンボリックカテゴリ機能が含まれている場合(例: 閉じた語彙からの単語など、k個の異なるシンボルのいずれかを取る特徴)は、可能な各特徴値(すなわち、語彙内の各単語)をいくつかのdのd次元ベクトルに関連付けることが一般的である。
— 49ページ、自然言語処理におけるニューラルネットワークメソッド、2017。
ワンホットエンコードされた単語は、単語ベクトルにマッピングされます。 多層パーセプトロンモデルが使用されている場合、単語ベクトルは、モデルへの入力として供給される前に連結されます。 リカレントニューラルネットワークが使用される場合、各単語はシーケンス内の一つの入力として取られることができます。
埋め込み層を学習するこのアプローチは、多くのトレーニングデータを必要とし、遅くなる可能性がありますが、特定のテキストデータとNLPタスクの両方を対象とした埋め込みを学習します。
Word2Vec
Word2Vecは、テキストコーパスから独立した単語埋め込みを効率的に学習するための統計的方法です。
Tomas Mikolovらによって開発されました。 埋め込みのニューラルネットワークベースのトレーニングをより効率的にするための応答として2013年にGoogleでは、それ以来、事前に訓練された単語の埋め込み
さらに、この作業には学習されたベクトルの分析と単語の表現に関するベクトル数学の探求が含まれていました。 たとえば、「王」から「男」を減算し、「女性」を追加すると、「女王」という単語が生成され、「王は男が女であるのと同じように女王にある」という類推がとられます。
これらの表現は、言語における構文的および意味的規則性をキャプチャするのに驚くほど優れており、各関係は関係固有のベクトルオフセットによ これにより、単語間のオフセットに基づくベクトル指向の推論が可能になります。 たとえば、男性/女性の関係が自動的に学習され、誘導されたベクトル表現では、「King–Man+Woman」は「Queen」に非常に近いベクトルになります。”
— 連続空間単語表現における言語的規則性、2013。
二つの異なる学習モデルが導入され、word2vecアプローチの一部として使用して単語の埋め込みを学習することができました。:
- 連続的な袋の単語、かCBOWモデル。
- 連続スキップグラムモデル。
CBOWモデルは、その文脈に基づいて現在の単語を予測することによって埋め込みを学習します。 連続スキップグラムモデルは,現在の単語を与えられた周囲の単語を予測することによって学習する。
連続スキップグラムモデルは、現在の単語を与えられた周囲の単語を予測することによって学習します。
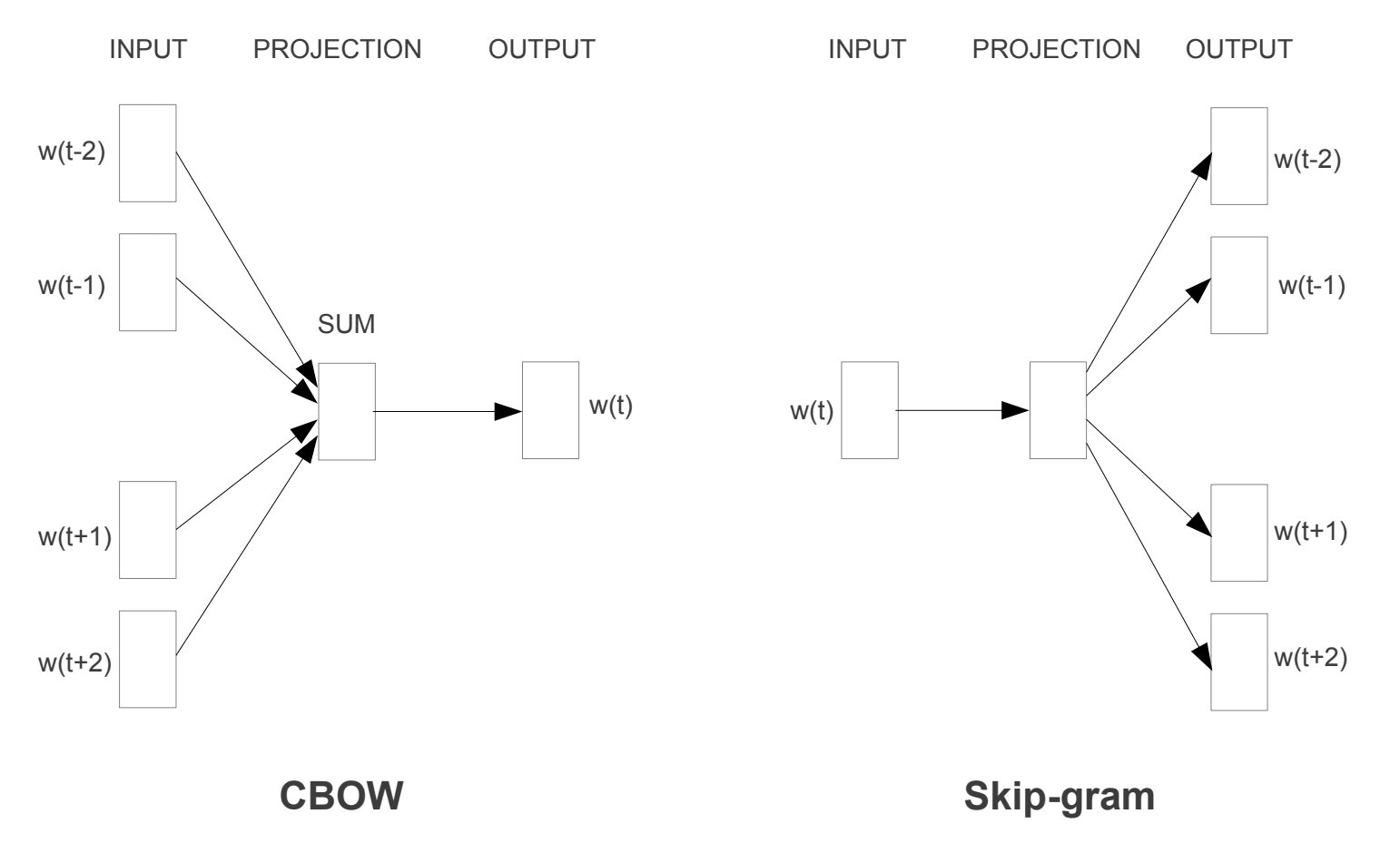
Word2Vecトレーニングモデル
“ベクトル空間における単語表現の効率的な推定”から取られた”, 2013
両方のモデルは、コンテキストが隣接する単語のウィンドウによって定義されるローカル使用コンテキストを指定した単語についての学習に焦点を当てています。 このウィンドウは、モデルの構成可能なパラメータです。
スライディングウィンドウのサイズは、結果のベクトルの類似性に強い影響を与えます。 大きな窓はより局所的な類似性を生成する傾向があり、小さな窓はより機能的および構文的な類似性を生成する傾向がある。
— 128ページ、自然言語処理におけるニューラルネットワークメソッド、2017。
このアプローチの主な利点は、高品質の単語の埋め込みを効率的に学習することができ(空間と時間の複雑さが低い)、はるかに大きなテキストのコーパス(十億語)からより大きな埋め込みを学習することができる(より多くの次元)ことである。
GloVe
Gloveアルゴリズムは、Penningtonらによって開発された単語ベクトルを効率的に学習するためのword2vecメソッドの拡張です。 スタンフォード大学で
単語の古典的なベクトル空間モデル表現は、潜在意味分析(LSA)のような行列分解技術を使用して開発されました。 上記の王と女王の例)。
GloVeは、lsaのような行列分解技術のグローバル統計とword2vecのローカルコンテキストベースの学習の両方を結婚させるアプローチです。
ウィンドウを使用してローカルコンテキストを定義するのではなく、GloVeはテキストコーパス全体の統計を使用して明示的な単語コンテキストまたは単語共起行列を構築します。 その結果、学習モデルが作成され、一般的に単語の埋め込みが改善される可能性があります。
GloVeは、単語の類推、単語の類似性、および名前付きエンティティ認識タスクに関する他のモデルよりも優れた、単語表現の教師なし学習のための新し
— GloVe:単語表現のためのグローバルベクトル,2014.
単語埋め込みの使用
自然言語処理プロジェクトで単語埋め込みを使用するときには、いくつかのオプションがあります。
このセクションでは、これらのオプションの概要を説明します。
埋め込みを学ぶ
あなたはあなたの問題のための単語埋め込みを学ぶことを選択することができます。
これは、数百万語や数十億語など、有用な埋め込みが学習されるようにするために大量のテキストデータを必要とします。
あなたの単語の埋め込みを訓練するときには、二つの主なオプションがあります:
- ここでは、モデルが埋め込みを学習するように訓練され、後でタスクのために別のモデルの一部として保存されて使用されます。 これは、複数のモデルで同じ埋め込みを使用したい場合に適したアプローチです。
- 埋め込みは、大規模なタスク固有のモデルの一部として学習され、共同で学びます。 これは、埋め込みを1つのタスクでのみ使用する場合に適しています。
埋め込みを再利用する
研究者は、事前に訓練された単語埋め込みを無料で利用できるようにするのが一般的です。
たとえば、word2vecとGloVe word embeddingsの両方が無料でダウンロードできます。
これらは、あなた自身の埋め込みを最初から訓練するのではなく、あなたのプロジェクトで使用することができます。
事前に訓練された埋め込みを使用する場合、主に2つのオプションがあります:
- 埋め込みは静的に保たれ、モデルのコンポーネントとして使用されます。 これは、埋め込みが問題に適しており、良好な結果が得られる場合に適したアプローチです。
- が更新され、事前に訓練された埋め込みがモデルのシードに使用されますが、埋め込みはモデルのトレーニング中に共同で更新されます。 モデルを最大限に活用し、タスクに埋め込む場合は、これが良いオプションになる可能性があります。
どのオプションを使用する必要がありますか?
さまざまなオプションを調べ、可能であれば、問題で最良の結果が得られるかどうかをテストします。
おそらく、事前に訓練された埋め込みを使用するなど、高速な方法から始め、問題のパフォーマンスが向上する場合にのみ新しい埋め込みを使用します。
Word Embedding Tutorials
このセクションでは、word embeddingを使用してword embeddingをプロジェクトに持ち込むために従うことができるいくつかのステップバイステップのチュート
- GensimでPythonで単語埋め込みを開発する方法
- Kerasで深い学習のための単語埋め込み層を使用する方法
- 感情分析のための深いCNNを開発する方法(テキ)
続きを読む
このセクションでは、より深く見ている場合は、トピックに関するより多くのリソースを提供します。
記事
- Wikipedia上の単語埋め込み
- Wikipedia上のWord2Vec
- GloVe on Wikipedia
- 単語埋め込みの概要と分布意味モデルへの接続,2016.
- ディープラーニング、NLP、表現、2014年。
論文
- 分布構造、1956年。
- 神経確率的言語モデル、2003年。
- 自然言語処理のための統一されたアーキテクチャ:マルチタスク学習を伴う深いニューラルネットワーク、2008。
- 連続空間言語モデル、2007年。
- ベクトル空間における単語表現の効率的な推定,2013
- 単語やフレーズの分散表現とその合成性,2013.
- GloVe:単語表現のためのグローバルベクトル,2014.
プロジェクト
- google Code上のword2vec
- GloVe:単語表現のためのグローバルベクトル
書籍
- 自然言語処理におけるニューラルネットワークメソッド、2017。
概要
この記事では、ディープラーニングアプリケーションのテキストの表現方法として単語埋め込みを発見しました。
:
- 表現テキストの単語埋め込みアプローチとは何か、それが他の特徴抽出方法とどのように異なるか。
- テキストデータから単語埋め込みを学習するための3つの主要なアルゴリズムがあること。
- 新しい埋め込みを訓練するか、自然言語処理タスクで事前に訓練された埋め込みを使用することができます。
何か質問はありますか?
以下のコメントであなたの質問をすると、私は答えるために最善を尽くします。
テキストデータの深層学習モデルを今すぐ開発!

数分で独自のテキストモデルを開発
。..pythonコードのわずか数行で
どのように私の新しい電子ブックで発見:
自然言語処理のための深い学習
それはのようなトピックに関する自習チュー..
最後に、あなたの自然言語処理プロジェクトに深い学習をもたらす
学者をスキップします。 ちょうど結果。
中身を見る