変数を含めることができる間違った方法もいくつかあります。 重力モデルは、各変数が次の基準を満たしていない限り機能しません:
- 数値
- Complete
- Reliable
数値データのみ
重力モデルは数学的な方程式であるため、すべての入力変数は数値でなければなりません。 これは、カウント(人口)、空間的尺度(面積、距離など)、時間(徒歩でロンドンからの時間)、パーセンテージ(賃金の増減)、通貨価値(シリングでの賃金)、またはモデルに関
数値は意味のあるものでなければならず、定性的属性のスタンドインとして機能する名目上のカテゴリ変数にすることはできません。 たとえば、数値に意味がない場合(たとえば、road quality=good、またはroad quality=4)、任意に数値を割り当ててモデルで使用することはできません。 後者は数値ですが、道路の品質の尺度ではありません。 代わりに、道路の品質のプロキシとして、時速マイルでの平均移動速度を使用することができます。 平均速度が道路品質の意味のある尺度であるかどうかは、研究の著者として決定し、守るのはあなた次第です。
一般的に言えば、それを測定したり、それを数えることができれば、あなたはそれをモデル化することができます。
完全なデータのみ
すべてのカテゴリのデータは、関心のあるポイントごとに存在する必要があります。 つまり、分析対象の32の郡のすべてが、プッシュおよびプル係数ごとに信頼性の高いデータを持っている必要があります。 あなたは、このようなあなたが平均賃金を持っていない一つの郡として、任意のギャップや空白を持つことはできません。
信頼できるデータのみ
コンピュータサイエンスの格言”garbage in,garbage out”は、重力モデルにも適用され、重力モデルを構築するために使用されるデータと同じくらい信頼性があります。 信頼できるソースから堅牢で信頼性の高い履歴データを選択する以外にも、モデルの出力を無意味にするミスを犯す方法はたくさんあります。 たとえば、持っているデータがテリトリーと正確に一致していることを確認する価値があります(たとえば、郡を表す郡データではなく、郡を表す都市データ)。
研究の時間と場所によっては、モデルの基礎となる信頼できる一連のデータを得ることが困難な場合があります。 過去の自分の研究でさらに戻って、それはより困難かもしれません。 同様に、ヨーロッパや北米のように、官僚主義が強く、生き残った紙の痕跡を残した社会では、これらのタイプの分析を行う方が簡単かもしれません。
このケーススタディでは、データ品質を確保するために、各変数を確実に計算するか、公開された査読済み履歴データから導出しました(表1参照)。 これらのデータがどのようにコンパイルされたかは、元の記事で深く説明されているところで読むことができます。11
私たちの五つのモデル変数
上記の原則を念頭に置いて、移行のプッシュとプル要因について知っていたことを考えると、任意の数の変数を選 私たちは、私たちが最も重要だと思ったものに基づいて選択され、信頼性の高いデータでバックアップできることを知っていた5つ(5)に落ち着きました。
| 変数 | ソース |
|---|---|
| 起源の人口 | 1771values,Wrigley,”English county populations”,pp.54-5.12 |
| ロンドンからの距離 | ソフトウェアで計算 |
| 小麦の価格 | 大砲と矛先、”週間英国の穀物価格”13 |
| 起源の平均賃金 | ハント、”産業化と地域格差”、pp.965-6.14 |
| 賃金の軌跡 | ハント、”産業化と地域格差”、pp.965-6.15 |
表1: モデルで使用されている5つの変数と、査読された文献
のそれぞれのソースは、これらの変数を決定したので、元の研究の共著者であるAdam Dennettは、これらの5つの変数のそれぞれにどのビットが関係しているかを簡単に知ることができるように、式を自己文書化するように書き直すことにしました。 これが、上記の式が元の研究論文の式とは異なるように見える理由です。 新しい記号は表2に見ることができます:
2つの追加の変数i i.とj j.は、それぞれ”原点で”と”ロンドンで”を意味します。 $Wa_{i}.は「原点での賃金水準」を意味し、$Wa_{j}.は「ロンドンの賃金水準」を意味します。 これらの7つの新しいシンボルは、式のより一般的なものを置き換えることができます:
\
これはより冗長で、前の式のわずかに自己文書化されたバージ 変更は純粋に表面的であり、人間のユーザーの利益のためであるため、両方ともまったく同じ方法で数学的に解決します。
完成した変数データセット
チュートリアルをより簡単に完了させるために、5つの変数と32の郡のそれぞれのデータはすでにコンパイルされ、クリーン この表には、プライマリソースレコードで観察された、その郡からの既知の浮浪者の数も含まれています:
| 郡 | や浮浪者 | $d$kmロンドン | $P$人口(人) | $は$平均賃金(シリング) | $ワット$賃金の軌跡1767-95に変更いたしました。) | $Wh$小麦価格(シリング) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| バークシャー | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| バッキンガムシャー | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| ケンブリッジシャー | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| チェシャー州 | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| コーンウォール | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| カンバーランド | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| ダービーシャー | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| デヴォン | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| ドーセット | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| ダーラム | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| グロスターシャー | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| ハンプシャー | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| ヘレフォードシャー | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| ハートフォードシャー | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| ハンティングドンシャー | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| ランカシャー州 | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| レスターシャー | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| リンカンシャー | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| ノーサンプトンシャー | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| ノーサンバーランド | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| ノッティンガムシャー | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| オックスフォードシャー | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| ラトランド | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| シュロップシャー | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| サマセット | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| スタッフォードシャー | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| ウォリックシャー | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| ウェストモーランド | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| ウィルトシャー | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| ウスターシャー | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| ヨークシャー | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
この式と元の記事で使用されている式との最終的な違いは、自然対数でプロットされたときに、2つの変数が浮浪とのより強い関係を持つことです。 彼らは起源(P P.)の人口であり、起源からロンドンまでの距離(d d.)です。 これが意味することは、この研究のデータについては、回帰直線(時には最良適合線と呼ばれる)が、データが記録されていない場合よりも良好に適合する これは図7で確認でき、左側にログに記録されていない母集団の数値、右側にログに記録されたバージョンが表示されます。 ログに記録されていないグラフよりも多くの点がログに記録されたグラフに最も適した線に近い点になります。
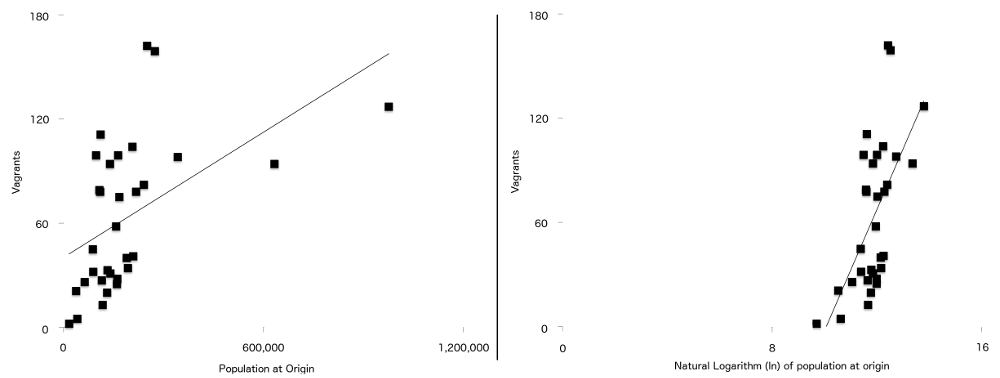
図7: 原点の母集団に対してプロットされた浮浪者の数(左)、および原点の母集団の自然対数(右)の両方に単純な回帰線がオーバーレイされています。 2番目のグラフに表示される2つの変数間のより強い関係に注意してください。
これはこの特定のデータの場合であるため(同様のタイプの研究の独自のデータはこのパターンに従わない可能性があります)、式はこれら二つの変数の自然にログに記録されたバージョンを使用するように調整され、重力モデルで使用される最終的な式が得られました(図8)。 変数データを収集した後まで、この調整の必要性について知ることはできませんでした:
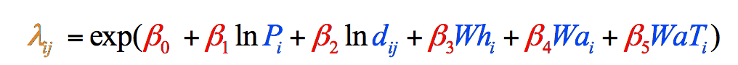
図8:最終的な重力モデルの公式は、ステップごとに分解され、色分けされています。 黒の要素は数学的演算です。 青色の要素は、収集したばかりの変数を表します(ステップ1)。 赤の要素は各変数の重み付けを表し、計算する必要があります(ステップ2)、オレンジの要素はその郡からの浮浪者の最終的な推定値であり、他の情報
表3の値は、図8の各方程式の青い部分を埋めるために必要なすべてを示しています。 これで、各変数がモデル全体でどのように重要であるかを教えてくれる赤い部分に注意を向けることができ、方程式を完成させるために必要な数
ステップ2:重みの決定
各変数の重みは、特定の郡から来るはずの浮浪者の数を推定しようとするとき、プッシュ/プル係数が他の変数と比較して Β β parametersパラメータは、既知のデータからデータセット全体で決定する必要があります。 これらを手にすることで、個々の起源固有の観測値を一般的なモデルと比較することができます。 その後、これらを調べ、さまざまな起源と目的地の間の予測された流れの上および下を特定することができます。
この段階では、それぞれがどれほど重要であるかはわかりません。 おそらく、小麦の価格は距離よりも移行のより良い予測因子ですか? 上記の式を解くことによってβ β1throughからβ β5.(重み)の値を計算するまではわかりません。 Y切片(β β0-)は、他のすべて(β β1-β5.)を知っていれば計算することができます。 これらは上の図8の赤の値です。 重み付けは、元の紙の表4および表A1に見ることができる。16私たちは今、私たちはこれらの値に来た方法を実証します。
これらの値を計算するには、長い手には信じられないほどの作業が必要です。 William VenablesとBrian RipleyのMASSパッケージを利用したRプログラミング言語で、重力モデルのような負の二項回帰方程式を1行のコードで解くことができる簡単な解を使用します。 しかし、コードが何をしているのかを理解するためには、何をしているのかの背後にある原則を理解することが重要です(次のセクションでは計算を行
計算個々の価格下落を過大に評価(原則)
$β_{1}$,$β_{2}$どと同じで$β$単純な線形回帰モデルの上に傾斜の回帰直線(上昇は、どんなに多く$y$が$x$の増加による1)です。 単純な線形回帰と重力モデルの唯一の違いは、1ではなく5つの傾きを計算する必要があることです。次のステップでy切片を計算する前に、単純な線形回帰\(y=α+θ x\)
次のステップでy切片を計算する前に、これらの5つの傾きのそれぞれについて解 これは、さまざまなβ β β値の傾きがy切片を計算するための式の一部であるためです。
回帰分析でβ β βを計算するための式は次のとおりです:
\
ピアソンの相関係数
ピアソンの相関係数は長い手で計算することができますが、この場合はかなり長い計算であり、64個の数字が必要です。 あなたは長い手の計算を行う方法のウォークスルーを見たい場合は、オンラインで利用可能な英語でいくつかの素晴らしいビデオチュートリアルがあり17あなたがデータを提供するならばあなたのためにr r.を計算する多くのオンライン計算機もあります。 計算する桁数が多いため、この計算を行うために設計されたツールが組み込まれたwebサイトをお勧めします。 大学が提供するサイトなど、評判の良いサイトを選択することを確認してください。
Calculating s_{y}Calculating&$s_{x}Standard(標準偏差)を計算する
標準偏差は、データにある平均(平均)からどれくらいの変動があるかを表現する方法です。 言い換えれば、データは平均の周りにかなりクラスタ化されているのですか、それとも広がりがはるかに広いのですか?
ここでも、データを提供すればこの計算を行うことができるオンライン計算機と統計ソフトウェアパッケージがあります。
Calculating β_{0}Calculating(y切片)を計算する
次に、y切片を計算する必要があります。 単純な線形回帰でy切片を計算する式は次のとおりです。
\
ただし、重回帰分析では、各変数が計算に影響を与えるため、計算がはるかに複雑になります。 これにより、手作業で行うことは非常に困難になり、プログラムによるソリューションを選択する理由の一つです。
重みを計算するためのコード
Rプログラミング言語用に書かれた質量統計パッケージには、負の二項回帰方程式を解くことができる関数があり、それ以外の場合は非常に困難な長い手の式を計算することが非常に簡単になります。
このセクションでは、Rをインストールし、MASSパッケージをインストールしたことを前提としています。 あなたがそうしていない場合は、先に進む前にする必要があります。 表形式のデータを使用したRの基本に関するTaryn Dewarのチュートリアルには、Rのインストール手順が含まれています。
このコードを使用するには、5つの変数のデータセットのコピーと32の郡のそれぞれから観測された浮浪者の数をダウンロードする必要があります。 これは、表のように上記で利用可能です3,またはとしてダウンロードすることができます.csvファイル。 どのモードを選択しても、ファイルをVagrantsExampleDataとして保存します。——- Macを使用している場合は、Windows形式で保存してください。csvファイル。 VagrantsExampleDataを開きます。csvとその内容を自分で精通しています。 このチュートリアルで説明した変数のそれぞれと一緒に、32の郡のそれぞれに気づく必要があります。 私たちは、私たちのコンピュータプログラムでこのデータにアクセスするために列ヘッダーを使用します。 私はそれらを何かと呼ぶことができましたが、このファイルでは:
vagrantspopulationdistancewheatwageswageTrajectory
csvファイルを保存したのと同じディレクトリに、新しいRスクリプトファイルを作成して保存します(これは任意のテキストエディタまたはRStudioで行 WeightingsCalculationsとして保存します。r.
私たちは今、その短いプログラムを書きます:
- は大量パッケージをインストールします
- は大量パッケージを呼び出しますので、コードで使用できます
- の内容を格納します。csvファイルをプログラムで使用できる変数に
- データセットを使用して重力モデル方程式を解き、
- 計算の結果を出力します。
これらの各タスクは、コードの一行で順番に達成されます
上記のコードをweightingsCalculationsにコピーします。rファイルと保存。 お気に入りのR環境(私はRStudioを使用)を使用してコードを実行すると、計算結果がコンソールウィンドウに表示されます(これは環境によって異なります)。 R環境の作業ディレクトリをあなたのものを含むディレクトリに設定する必要があるかもしれません。csvと.rファイル。 RStudioを使用している場合は、メニューからこれを行うことができます(Session->Set Working Directory->Choose Directory)。 また、次のコマンドで同じことを達成することもできます:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundglmを使用して、4行目が方程式を解く行であることに注意してください。nb関数は、”一般化線形モデル-負の二項式”の略です。 この行にはいくつかの入力が必要です:
- に書かれているように、列ヘッダーを使用して、私たちの変数.csvファイルと、それらに実行する必要があるログ(
vagrants、log(population)、log)。(distance),wheat,wages,wageTrajectory). 独自のデータを使用してモデルを実行している場合は、データセット内の列ヘッダーを反映するようにこれらを調整します。コードがデータを見つけることができる - -この場合、3行目で定義した変数は
gravityModelDataと呼ばれます。
計算の出力は図で見ることができます9:
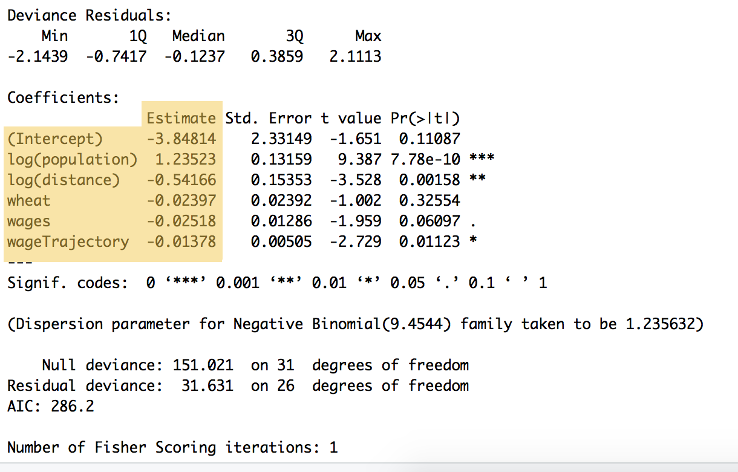
図9:上記のコードの要約で、各変数の重みとy切片を示し、’推定値’見出し(bet beta_{0}to〜bet beta_{5}.)の下にリストされています。 この要約には、統計的有意性を含む他の多くの計算も示されています。
ステップ3: 各郡の推定値を計算する
32の郡ごとに1回これを行う必要があります。
関数電卓を使って、スプレッドシートの数式を作成したり、コンピュータプログラムを書いたりすることができます。 Rでこれを自動的に行うには、コードに次のものを追加してプログラムを再実行します。 このforループは、この例の32の郡のそれぞれから期待される浮浪者の数を計算し、結果を表示します。
理解を深めるために、私は1つの郡を長い手で行うことをお勧めします。 このチュートリアルでは、長い手の例としてHertfordshireを使用します(ただし、プロセスは他の31の郡でもまったく同じです)。
表3のHertfordshireのデータと表4の各変数の重みを使用して、95の結果が得られる式を完成させることができます。
まず、上記の表から取得した数字の記号を交換してみましょう。
次に、推定値を取得するための値の計算を開始します。 演算の数学的順序を覚えて、加算する前に値を乗算します。 したがって、各変数を計算することから始めます(これには関数電卓を使用できます):
次のステップは、数値を一緒に追加することです:
estimated vagrants = exp(4.56232408897)そして最後に、指数関数を計算するには(関数電卓を使用してください):
estimated vagrants = 95.8059926832私たちは残りを落とし、このモデルのHertfordshireからの浮浪者の推定数は95であると宣言しました。 あなたは、スプレッドシートプログラムを使用して高速化することができ、他の郡のそれぞれについて同じ計算を行う必要があります。 もう一度できることを確認するために、Buckinghamshireの番号も含めました:
Hertfordshire
\
Buckinghamshire
\
他の郡を選択して計算することをお勧めします。 正しい答えは表5にあり、観測値(プライマリソースレコードに見られる)と推定値(重力モデルによって計算される)を比較します。 “残留”は両者の違いであり、大きな違いは、歴史家の帽子をかぶって詳しく見る価値があるかもしれない予期せぬ数の浮浪者を示唆しています。
| 郡 | 観測値 | 推定値 | 残差 |
|---|---|---|---|
| ベッドフォードシャー | 26 | 41 | -15 |
| バークシャー | 111 | 76 | 35 |
| バッキンガムシャー | 79 | 83 | -4 |
| ケンブリッジシャー | 32 | 48 | -16 |
| チェシャー州 | 34 | 44 | -10 |
| コーンウォール | 40 | 42 | -2 |
| カンバーランド | 13 | 21 | -8 |
| ダービーシャー | 28 | 36 | -8 |
| デヴォン | 98 | 121 | -23 |
| ドーセット | 27 | 36 | -9 |
| ダーラム | 25 | 31 | -6 |
| グロスターシャー | 162 | 123 | 39 |
| ハンプシャー | 78 | 92 | -14 |
| ヘレフォードシャー | 45 | 39 | 6 |
| ハートフォードシャー | 99 | 95 | 4 |
| ハンティングドンシャー | 21 | 18 | 3 |
| ランカシャー州 | 94 | 84 | 10 |
| レスターシャー | 20 | 28 | -8 |
| リンカンシャー | 41 | 86 | -45 |
| ノーサンプトンシャー | 33 | 78 | -45 |
| ノーサンバーランド | 58 | 29 | 29 |
| ノッティンガムシャー | 31 | 28 | 3 |
| オックスフォードシャー | 78 | 52 | 26 |
| ラトランド | 2 | 4 | -2 |
| シュロップシャー | 75 | 66 | 9 |
| サマセット | 159 | 145 | 14 |
| スタッフォードシャー | 82 | 85 | -3 |
| ウォリックシャー | 104 | 70 | 34 |
| ウェストモーランド | 5 | 5 | 0 |
| ウィルトシャー | 99 | 95 | 4 |
| ウスターシャー | 94 | 53 | 41 |
| ヨークシャー | 127 | 207 | -80 |
ステップ4-歴史的解釈
この段階で、モデリングプロセスは完了し、最終段階は歴史的解釈です。
このケーススタディの基礎となった元の出版された記事は、主にモデル化の結果が18世紀の下層階級の移住についての理解に何を意味するかを解釈することに専念している。 図5の地図に見られるように、モデルが強く示唆した国の一部は、ロンドンに下層階級の移住者を送りすぎているか、または送りすぎていないかのい
共著者は、なぜこれらのパターンが現れたのかについての解釈を提供した。 これらの解釈は場所によって異なります。 ヨークシャーやマンチェスターのような急速に工業化していたイングランド北部の地域では、地元での機会は人々に去る理由を少なくするように見え、ロンドンへの移住は予想よりも少なかった。 ブリストルのような西の衰退した地域では、より多くの人々が首都で仕事を求めて去ったので、ロンドンの魅力は強くなった。
すべてのパターンが予想されたわけではありません。 極東のノーサンバーランドは地域の異常であることが判明し、私たちが予想するよりもはるかに多くの(女性の)移住者をロンドンに送りました。 モデルの出力がなければ、特に大都市から遠く離れていて、ロンドンとの関係が弱いと推定されたため、ノーサンバーランドをまったく考慮することは考えられないでしょう。 このモデルは、歴史家として考慮すべき新しい証拠を提供し、ロンドンとノーサンバーランドの関係についての理解を変えました。 私たちの調査結果の完全な議論は、元の記事で読むことができます。18
あなたの知識を前進させる
この例の問題を試した後、この例の式の使い方と、重力モデルがあなたの研究問題の適切な解決策であるかどうかを明確に理解している必要があります。 あなたは、あなた自身のケーススタディにそれを適応させるのを助けることができる適切に数学的に識字協力者と重力モデルに近づき、議論する経験と語彙を持っています。
幸運にも、18世紀後半のロンドンへの移住者に関するデータを持っていて、上記の同じ5つの変数を使用してモデル化したい場合、この式はそのまま しかし、このモデルは、ロンドンへの移住者に関する研究にのみ有効ではありません。 変数は変更でき、宛先はロンドンである必要はありません。 あなたがデータと研究の質問を持っているならば、重力モデルを使って古代ローマ、または21世紀のバンコクへの移住を研究することは可能でしょう。 それは移行のモデルである必要さえありません。 移行ではなく貿易に焦点を当てた導入からのコロンビアのコーヒーケーススタディを使用するには、表6は、変更されていない同じ式の実行可能な使用を示
| コーヒー輸出例 | |
|---|---|
| 原産地の一点 | コロンビアのバランキージャ港からのコーヒー輸出 |
| 複数の有限の目的地 | で西半球の21カ国1950 |
| 五つの説明変数 | (1)受け入れ国の大西洋港の数(2)コロンビアからのマイル,(3)受け入れ国の国内総生産,(4)トンで栽培された国内コーヒー,(5)10,000人あたりのコーヒーショップ |
学術奨学金には重力モデルの長い歴史があります。 研究に効果的に使用するには、それらの背後にある基本的な理論と数学、そして彼らが持っているように発展した理由を理解する必要があります。 また、それらを適切に使用するための限界および条件を理解することも重要であり、そのうちのいくつかは上記で議論された。 それはまた知るのに役立つかもしれません:
-
この例で使用されているような重力モデルは、密閉されたシステムでのみ機能します。 上記のモデルは32の可能な原点のみを持っていたため、モデルを32回実行することが可能になりました。 未知または無限に多数の原点(またはモデルに応じて目的地)がある場合は、別の方程式が必要になります。
-
重力モデルの概念はまた、動き(移住、貿易など)は、外部要因の影響を受ける可能性があるが、それらによって完全に制御されていない自発的な個々の決定の集合に基づいているという前提に基づいて構築されている。 例えば、自発的な移動や自由意志で作られた購入は、この技術を使用してモデル化することができますが、強制的な移動、強制的な購入、または鳥の移動や川の流れなどの自然なプロセスは同じ原則に従わない可能性があるため、異なるタイプのモデルが必要になる可能性があります。
-
重力モデルは人口の行動を予測するために使用できますが、個人は予測できないため、統計的有意性を確保するために、データをモデル化しようとする試みには多数の動きが含まれている必要があります。
さらに多くの落とし穴がありますが、途方もない可能性もあります。 重力モデルのこのウォークスルーとそれに付随する出版された研究が、この強力なツールを歴史家にとってよりアクセスしやすくすることを私の希望 あなたの学術研究で重力モデルを使用することを計画している場合、著者は強く、次の記事をお勧めします:
謝辞
この記事の以前の草案を読み、コ また、この記事が起草されたコロンビアのボゴタでの執筆ワークショップに資金を提供した英国アカデミーのおかげで。 そして最後に、これらの素晴らしい公式に私を紹介し、歴史家のための彼らの可能性を解き放つためのアダム*デネットに。