Auto-Encoderの簡単な紹介とPythonコードでの一般的なユースケースのいくつか
背景:
Autoencoderは、データを効率的に圧縮してエンコードする方法を学習し、縮小されたエン
Autoencoderは、設計上、データ内のノイズを無視する方法を学習することにより、データ次元を削減します。
MNISTデータセットからオートエンコーダへの入出力イメージの例を次に示します。
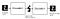
Autoencoderコンポーネント:
Autoencoderは4つの主要な部分で構成されています:
1-Encoder:入力次元を縮小し、入力データをエンコードされた表現に圧縮する方法をモデル
2-ボトルネック: これは、入力データの圧縮された表現を含むレイヤーです。 これは、入力データの最小次元です。
3-Decoder:このモデルでは、エンコードされた表現からデータを可能な限り元の入力に近づけるように再構築する方法を学習します。
4-再構成損失:これは、デコーダがどれだけうまく実行しているか、そして出力が元の入力にどれだけ近いかを測定する方法です。
このトレーニングでは、ネットワークの再構成損失を最小限に抑えるために逆伝播を使用します。
入力とまったく同じ画像やデータを出力するためだけにニューラルネットワークを訓練するのはなぜだろうかと疑問に思っている必要があります! この記事では、Autoencoderの最も一般的なユースケースについて説明します。 始めましょう:
Autoencoder Architecture:
autoencoderのネットワークアーキテクチャは、ユースケースに応じて、単純なフィードフォワードネットワーク、LSTMネットワーク、畳み込みニューラルネットワーク 私たちは、新しい次の数行でこれらのアーキテクチャのいくつかを探索します。
異常値や異常値を検出する方法や手法はたくさんあります。 私は以下の別の記事でこのトピックをカバーしています:
しかし、入力データを相関させている場合、エンコード操作は相関機能に依存してデータを圧縮するため、autoencoderメソッドは非常にうまく動作します。
MNISTデータセットでオートエンコーダーをトレーニングしたとしましょう。 単純なフィードフォワードニューラルネットワークを使用して、以下のように単純な6層ネットワークを構築することによ:
上記のコードの出力は次のとおりです:出力でわかるように、検証セットの最後の再構成損失/エラーは0.0193で、これは素晴らしいことです。 さて、MNISTデータセットから通常の画像を渡すと、再構成損失は非常に低くなります(<0.02)が、他の異なる画像(外れ値または異常値)を渡そうとすると、ネットワー
注意上記のコードでは、エンコーダ部分のみを使用して一部のデータまたは画像を圧縮し、デコーダ部分のみを使用してデコーダー層をロードしてデータを解凍することもできます。
さて、いくつかの異常検出をしましょう。 以下のコードでは、2つの異なる画像を使用して、上記で訓練したオートエンコーダネットワークを使用して異常スコア(再構成誤差)を予測します。 最初の画像はMNISTからのもので、結果は5.43209です。 これは、画像が異常ではないことを意味します。 私が使用した2番目の画像は、トレーニングデータセットに属していない完全にランダムな画像であり、結果は6789.4907でした。 この高い誤差は、画像が異常であることを意味します。 同じ概念は、任意のタイプのデータセットにも適用されます。