消費者業界のデータサイエンティストとして、私が通常感じるのは、boosting algorithmは、少なくとも今では、ほとんどの予測学習タスクには十分です。 彼らは、強力な柔軟性があり、いくつかのトリックでうまく解釈することができます。 したがって、私はいくつかの資料を読んで、昇圧アルゴリズムについて何かを書く必要があると思います。
このacticleのコンテンツのほとんどは、論文に基づいています:Xgboostを使用したTree Boosting:なぜXGBoostは”すべての”機械学習競争に勝つのですか?. それは本当に有益な論文です。 この論文では、ブーストアルゴリズムに関するほとんどすべてが非常に明確に説明されています。 したがって、この論文には110ページが含まれています:(
私にとって、私は基本的に最も人気のある3つのブーストアルゴリズムに焦点を当てます:AdaBoost、GBM、XGBoost。 私はコンテンツを2つの部分に分けました。 最初の記事(この記事)ではAdaBoostアルゴリズムに焦点を当て、2番目の記事ではGBMとXGBoostの比較に焦点を当てます。
AdaBoostは、”Adaptive Boosting”の略で、FreundとSchapireによって1996年に提案された最初の実用的なブーストアルゴリズムです。 それは分類問題に焦点を当て、弱い分類器のセットを強いものに変換することを目指しています。 分類のための最終的な方程式は、次のように表すことができます
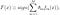
ここで、f_mはm_番目の弱分類器を表し、theta_mは対応する重みです。 それは正確にM個の弱い分類器の加重組み合わせです。 AdaBoostアルゴリズムの全体の手順は、以下のように要約することができます。
AdaBoostアルゴリズム
n個の点を含むデータセットが与えられたとき、次のようになります

ここで、-1は負のクラスを表し、1は正のクラスを表します。
各データポイントの重みを次のように初期化します:

反復m=1,…,Mの場合:
(1) 弱い分類器をデータセットに近似し、加重分類誤差が最も小さい分類器を選択します:

(2) m_番目の弱分類器の重みを計算します:

精度が50%を超える分類器では、重みは正の値になります。 分類器がより正確であればあるほど、重みは大きくなります。 精度が50%未満の分類器では、重みは負です。 それは、符号を反転させることによってその予測を組み合わせることを意味します。 たとえば、予測の符号を反転することで、精度が40%の分類器を精度が60%の分類器に変換できます。 したがって、分類器でさえ、ランダムな推測よりも悪いパフォーマンスを発揮し、最終的な予測に寄与します。 正確な50%の精度を持つ分類器は必要ありませんが、これは情報を追加しないため、最終的な予測には何も寄与しません。
(3)各データポイントの重みを次のように更新します:

ここで、Z_Mは、すべてのインスタンス重みの合計が1に等しいことを保証する正規化係数です。
誤分類されたケースが正の重み付き分類器からのものである場合、分子内の”exp”項は常に1より大きくなります(y*fは常に-1、theta_mは正です)。 したがって、誤分類されたケースは、反復後に大きな重みで更新されます。 負の重み付き分類器にも同じ論理が適用されます。 唯一の違いは、元の正しい分類が符号を反転した後に誤分類になることです。
M回の反復の後、各分類子の加重予測を合計することによって最終予測を得ることができます。
Adaboost As A Forward Stagewise Additive Model
この部分は紙に基づいています:加法ロジスティック回帰:ブーストの統計的見解。 詳細については、原著論文を参照してください。
2000年、Friedman et al. AdaBoostアルゴリズムの統計ビューを開発しました。 彼らは、adaboostを加法ロジスティック回帰モデルを近似するための段階的推定手順として解釈しました。 彼らは、AdaBoostが実際に指数損失関数を最小化していることを示しました

それはで最小化されます

AdaBoostの場合、yは-1または1のみになるため、損失関数は次のように書き換えることができます

F(x)を解くために続けて、我々は得る

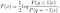
さらに、F(x)の最適解から正規ロジスティックモデルを導出することができます):

これは、因子2にもかかわらず、ロジスティック回帰モデルとほぼ同じです。
F(x)の現在の推定値があり、改善された推定値F(x)+cf(x)を求めようとするとします。 固定されたcとxの場合、L(y、F(x)+cf(x))をf(x)について2次に展開できます)=0,

このように,

ここで、E_W(.|x)は重み付けされた条件付き期待値を示し、各データポイントの重みは次のように計算されます

c>0の場合、加重条件付き期待値を最小化することは最大化に等しくなります

yは1または-1のみであるため、重み付き期待値は次のように書き換えることができます

最適解は次のようになります

f(x)を決定した後、重みcは、L(y,F(x)+cf(x))を直接最小化することによって計算することができる。:

cを解くと、次のようになります


εを誤分類されたケースの重み付けされた合計に等しくすると、

弱い学習者がランダムな推測(50%)よりも悪い場合、cは負になる可能性があることに注意してください。 どの場合それは自動的に極性を逆転させます。
インスタンスの重みに関しては、改良された追加の後、単一のインスタンスの重みは次のようになります,

したがって、インスタンスの重みは次のように更新されます

AdaBoostアルゴリズムで使用されるものと比較して,

私たちは、彼らが同一の形である見ることができます。 したがって、AdaBoostを指数損失関数を持つ前方段階的加法モデルとして解釈することは合理的であり、各反復mでの現在の推定値を改善するために弱分類器を反復的に適合させることができる。:
