소비자 업계의 데이터 과학자로서,내가 일반적으로 느끼는 것은,부스팅 알고리즘은 적어도 지금까지,예측 학습 작업의 대부분을 위해 아주 충분하다. 그들은 강력하고 유연하며 몇 가지 트릭으로 멋지게 해석 될 수 있습니다. 따라서,나는 몇 가지 자료를 읽고 증폭 알고리즘에 대해 뭔가를 쓸 필요가 있다고 생각합니다.
이 액티클의 대부분의 콘텐츠는 종이를 기반으로합니다.. 그것은 정말 유익한 종이입니다. 알고리즘을 강화하는 것과 관련된 거의 모든 것이 논문에서 매우 명확하게 설명되어 있습니다. 그래서 논문은 110 페이지가 포함되어 있습니다:(
나를 위해,나는 기본적으로 세 가지 가장 인기있는 부스팅 알고리즘에 초점을 맞출 것이다. 나는 내용을 두 부분으로 나누었다. 첫 번째 기사(이 기사)는 애드부스트 알고리즘에 초점을 맞추고 두 번째 기사는 하드 디스크와 하드 디스크 사이의 비교로 전환됩니다.
“적응 부스팅”에 대한 짧은 아다 부스트는 1996 년 프로 인트와 샤피어에 의해 제안 된 최초의 실용적인 부스팅 알고리즘이다. 이 분류 문제에 초점을 맞추고 강한 하나에 약한 분류의 집합을 변환하는 것을 목표로하고있다. 분류에 대한 최종 방정식은 다음과 같이 나타낼 수 있습니다
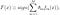
여기서 에프_미디엄 미디엄_번째 약한 분류 자 및 태타_미디엄 해당 가중치입니다. 그것은 정확히 가중치 조합 미디엄 약한 분류 자. 아다 부스트 알고리즘의 전체 절차는 다음과 같이 요약 할 수 있습니다.
아다부스트 알고리즘
다음을 포함하는 데이터 세트 주어진 엔 포인트,여기서

여기서-1 은 음수 클래스를 나타내고 1 은 양수를 나타냅니다.
각 데이터 요소의 가중치를 다음과 같이 초기화합니다.:

반복의 경우 미디엄=1,…,미디엄:
(1) 약한 분류자를 데이터 세트에 맞추고 가중 분류 오류가 가장 낮은 분류자를 선택합니다:

(2) 약한 분류자에 대한 가중치 계산:

50%보다 높은 정확도를 가진 모든 분류기에 대해 무게는 양수입니다. 더 정확한 분급자,더 큰 무게. 50%미만 정확도를 가진 분류기를 위해,무게가 부정적인 동안. 그것은 우리가 기호를 뒤집어서 그 예측을 결합한다는 것을 의미합니다. 예를 들어,예측의 부호를 뒤집어서 40%정확도의 분류자를 60%정확도로 바꿀 수 있습니다. 따라서 분류 자조차도 무작위 추측보다 더 나쁜 성능을 발휘하지만 여전히 최종 예측에 기여합니다. 우리는 정확한 50%의 정확도를 가진 분류 자만 원하지 않으므로 정보를 추가하지 않으므로 최종 예측에 아무런 기여도하지 않습니다.
(3)각 데이터 요소의 가중치를 다음과 같이 업데이트합니다:

여기서 지 _엠은 모든 인스턴스 가중치의 합이 1 이 되도록 하는 정규화 요인입니다.
잘못 분류된 사례가 양의 가중치 분류기에서 나온 경우 분자의”경험치”용어는 항상 1 보다 큽니다. 따라서 잘못 분류 된 사례는 반복 후에 더 큰 가중치로 업데이트됩니다. 동일한 논리가 음수 가중치 분류기에 적용됩니다. 유일한 차이점은 원래의 올바른 분류가 기호를 뒤집은 후 잘못 분류된다는 것입니다.
미디엄 반복 후 각 분류 자의 가중 예측을 합산하여 최종 예측을 얻을 수 있습니다.
순방향 단계적 가산 모델
이 부분은 종이:가산 로지스틱 회귀 분석:부스팅에 대한 통계적 뷰를 기반으로합니다. 자세한 내용은 원본 문서를 참조하십시오.
2000 년,프리드먼 외. 아다 부스트 알고리즘의 통계 뷰를 개발. 그들은 추가 로지스틱 회귀 모델을 맞추기위한 단계 별 추정 절차로 아다 부스트를 해석했습니다. 그들은 아다 부스트가 실제로 지수 손실 함수를 최소화하고 있음을 보여주었습니다

그것은에 극소화됩니다

손실 함수는 다음과 같이 다시 쓸 수 있습니다

에 대한 해결을 계속 에프(엑스),우리는 얻을

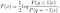
우리는 최적의 솔루션에서 일반 물류 모델을 더 도출 할 수 있습니다.):

요인 2 에도 불구하고 로지스틱 회귀 모델과 거의 동일합니다.
현재 추정치가 있다고 가정 에프(엑스)개선 된 추정치를 찾으려고 노력 에프(엑스)+참조(엑스). 에 대한 고정 씨 과 엑스,우리는 확장 할 수 있습니다 엘(와이,에프(엑스)+참조(엑스))에 대한 두 번째 순서 에프(엑스)=0,

따라서,

(./엑스)가중 조건부 기대치를 나타내며 각 데이터 요소에 대한 가중치는 다음과 같이 계산됩니다

만약 씨>0,가중 조건부 기대치를 최소화하는 것은 최대화와 같습니다

이후 와이 1 또는-1 일 수 있으므로 가중 기대치는 다음과 같이 다시 쓸 수 있습니다

최적의 솔루션은 다음과 같이 제공됩니다

측정 후 에프(엑스),무게 씨 직접 최소화하여 계산할 수 있습니다 엘(와이,에프(엑스)+에프(엑스)):

에 대한 해결 기음,우리는 얻을


하자 엡실론 같음 잘못 분류 된 사례의 가중 합계,그런 다음

참고 씨 약한 학습자가 무작위 추측(50%)보다 나쁘면 음수가 될 수 있습니다. 어떤 경우 자동으로 극성을 반전시킵니다.
인스턴스 가중치 측면에서 향상된 추가 후에 단일 인스턴스의 가중치가 됩니다,

따라서 인스턴스 가중치는 다음과 같이 업데이트됩니다

애다부스트 알고리즘에 사용되는 것과 비교,

우리는 그들이 동일한 형태로 볼 수 있습니다. 따라서 아다 부스트를 지수 손실 함수가 있는 순방향 단계별 가산 모델로 해석하는 것이 합리적입니다.이 함수는 약한 분류자를 반복적으로 적합하여 각 반복에서 현재 추정치를 향상시킵니다 미디엄:
