som datavitenskapsmann i forbrukerindustrien, er det jeg vanligvis føler, å øke algoritmer nok for de fleste prediktive læringsoppgaver, i hvert fall nå. De er kraftige, fleksible og kan tolkes pent med noen triks. Dermed tror jeg det er nødvendig å lese gjennom noen materialer og skrive noe om boosting algoritmer.
Det Meste av innholdet i denne acticle er basert på papiret: Tree Boosting With XGBoost: Hvorfor Vinner XGBoost «Hver» Maskinlæringskonkurranse?. Det er et veldig informativt papir. Nesten alt om å øke algoritmer forklares veldig tydelig i papiret. Så papiret inneholder 110 sider: (
For meg vil jeg i utgangspunktet fokusere på de tre mest populære forsterkningsalgoritmene: AdaBoost, GBM og XGBoost. Jeg har delt innholdet i to deler. Den første artikkelen (denne) vil fokusere På adaboost-algoritmen, og den andre vil vende seg til sammenligningen MELLOM GBM og XGBoost.
AdaBoost, kort for «Adaptive Boosting», er Den første praktiske boosting algoritmen foreslått Av Freund Og Schapire i 1996. Den fokuserer på klassifiseringsproblemer og tar sikte på å konvertere et sett med svake klassifiserere til en sterk. Den endelige ligningen for klassifisering kan representeres som
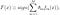
hvor f_m står for m_th svak klassifikator og theta_m er den tilsvarende vekten. Det er akkurat den vektede kombinasjonen Av m svake klassifikatorer. Hele prosedyren I adaboost-algoritmen kan oppsummeres som følger.
adaboost-algoritme
Gitt et datasett som inneholder n punkter, hvor

her -1 betegner den negative klassen mens 1 representerer den positive.
Initialiser vekten for hvert datapunkt som:

For iterasjon m = 1,…, M:
(1) Tilpass svake klassifikatorer til datasettet og velg den med lavest vektede klassifiseringsfeil:

(2) Beregn vekten for m_th svak klassifikator:

for enhver klassifikator med nøyaktighet høyere enn 50%, er vekten positiv. Jo mer nøyaktig klassifikatoren er, desto større er vekten. Mens for klassifikatoren med mindre enn 50% nøyaktighet, er vekten negativ. Det betyr at vi kombinerer sin prediksjon ved å bla skiltet. For eksempel kan vi slå en klassifikator med 40% nøyaktighet til 60% nøyaktighet ved å vende tegn på prediksjonen. Dermed utfører klassifikatoren verre enn tilfeldig gjetting, det bidrar fortsatt til den endelige prediksjonen. Vi vil bare ikke ha noen klassifikator med nøyaktig 50% nøyaktighet, noe som ikke legger til noen informasjon og dermed ikke bidrar til den endelige prediksjonen.
(3) Oppdater vekten for hvert datapunkt som:

Hvor Z_m er en normaliseringsfaktor som sikrer at summen av alle forekomstvekter er lik 1.
hvis en feilklassifisert sak er fra en positiv vektet klassifikator, vil» exp » – termen i telleren alltid være større enn 1 (y * f er alltid -1, theta_m er positiv). Dermed feilklassifiserte tilfeller vil bli oppdatert med større vekter etter en iterasjon. Den samme logikken gjelder for de negative vektede klassifikatorene. Den eneste forskjellen er at de opprinnelige korrekte klassifiseringene vil bli feilklassifikasjoner etter å ha vendt skiltet.
etter M iterasjon kan vi få den endelige prediksjonen ved å oppsummere den vektede prediksjonen til hver klassifikator.
AdaBoost Som En Forward Stagewise Additive Model
denne delen er basert på papir: Additiv logistisk regresjon: en statistisk visning av boosting. For mer detaljert informasjon, se originalpapiret.
I 2000 Ble Friedman Et al. utviklet en statistisk visning Av adaboost-algoritmen. De tolket AdaBoost som stagewise estimeringsprosedyrer for montering av en additiv logistisk regresjonsmodell. De viste At AdaBoost faktisk minimerte eksponentiell tapfunksjon

det er minimert ved

siden For AdaBoost kan y bare være -1 eller 1, kan tap-funksjonen omskrives som

fortsett å løse For F (x), får vi

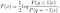
vi kan videre utlede den normale logistiske modellen fra den optimale løsningen Av F (x):

det er nesten identisk med den logistiske regresjonsmodellen til tross for en faktor 2.
Anta at vi har et nåværende estimat Av F (x) og prøver å søke et forbedret estimat F (x) + cf (x). For fast c og x kan vi utvide L (y, F(x)+cf (x)) til andre rekkefølge om f (x)=0,

Dermed,

hvor E_w(./ x) angir en vektet betinget forventning, og vekten for hvert datapunkt beregnes som

hvis c > 0, er minimering av vektet betinget forventning lik maksimering

siden y bare kan være 1 eller -1, kan den vektede forventningen omskrives som

den optimale løsningen kommer som

etter å ha bestemt f(x), kan vekten c beregnes ved å minimere L(y, F(x)+cf(x))direkte:

Løsning for c, får vi


La epsilon være lik den vektede summen av feilklassifiserte tilfeller, da

Merk at c kan være negativ hvis den svake eleven gjør verre enn tilfeldig gjetning (50%), i i så fall reverserer den automatisk polariteten.
når det gjelder forekomstvekter, blir vekten for en enkelt forekomst etter forbedret tillegg,

dermed er forekomstvekten oppdatert som

Sammenlignet med De som brukes I adaboost-algoritmen,

vi kan se at de er i identisk form. Derfor er Det rimelig å tolke AdaBoost som en forward stagewise additiv modell med eksponentiell tap-funksjon, som iterativt passer til en svak klassifikator for å forbedre dagens estimat ved hver iterasjon m:
