Sist Oppdatert 7. August 2019
ordinnbygginger er en type ordrepresentasjon som gjør at ord med lignende betydning kan ha en lignende representasjon.
de er en distribuert representasjon for tekst som kanskje er et av de viktigste gjennombruddene for den imponerende ytelsen til dype læringsmetoder på utfordrende naturlige språkbehandlingsproblemer.
i dette innlegget vil du oppdage ordet embedding tilnærming for å representere tekstdata.
etter å ha fullført dette innlegget, vil du vite:
- hva ordet embedding tilnærming for å representere tekst er og hvordan den skiller seg fra andre funksjonen utvinning metoder.
- At det er 3 hovedalgoritmer for å lære et ord embedding fra tekstdata.
- At du enten kan trene en ny innebygging eller bruke en forhåndslært innebygging på din naturlige språkbehandlingsoppgave.
Start prosjektet ditt Med Min nye bok Deep Learning for Naturlig Språkbehandling, inkludert trinnvise opplæringsprogrammer og Python-kildekodefilene for alle eksempler.
La oss komme i gang.

Hva Er Ordinnbygginger For Tekst?
Foto Av Heather, noen rettigheter reservert.
- Oversikt
- Trenger Du Hjelp Med Dyp Læring For Tekstdata?
- Hva Er Ordinnbygginger?
- Algoritmer For Embedding Av Ord
- Innebyggingslag
- Word2Vec
- Hanske
- Bruke Word Embeddings
- Lær En Embedding
- Gjenbruk En Embedding
- Hvilket Alternativ Bør Du Bruke?
- Word Embedding Tutorials
- Videre Lesing
- Artikler
- Papirer
- Prosjekter
- Bøker
- Sammendrag
- Utvikle Dype læringsmodeller For Tekstdata I Dag!
- Utvikle Dine Egne Tekstmodeller på Få Minutter
- Endelig Ta Med Dyp Læring til Dine Naturlige Språkbehandlingsprosjekter
Oversikt
dette innlegget er delt inn i 3 deler; de er:
- Hva Er Ordet Embeddings?
- Ord Embedding Algoritmer
- Bruke Word Embeddings
Trenger Du Hjelp Med Dyp Læring For Tekstdata?
Ta mitt gratis 7-dagers e-postkrasjkurs nå (med kode).
Klikk for å registrere deg og få også en GRATIS Pdf Ebook-versjon av kurset.
Start DITT Gratis Krasjkurs Nå
Hva Er Ordinnbygginger?
et ord embedding er en lært representasjon for tekst der ord som har samme betydning har en lignende representasjon.
det er denne tilnærmingen til å representere ord og dokumenter som kan betraktes som et av de viktigste gjennombruddene i dyp læring på utfordrende naturlige språkbehandlingsproblemer.
en av fordelene ved å bruke tette og lavdimensjonale vektorer er beregningsmessige: flertallet av neural network toolkits spiller ikke bra med svært høy-dimensjonale, sparsomme vektorer. Hovedfordelen med de tette representasjonene er generaliseringskraft: hvis vi tror at noen funksjoner kan gi lignende ledetråder, er det verdt å gi en representasjon som er i stand til å fange opp disse likhetene.
— Side 92, Nevrale Nettverksmetoder I Naturlig Språkbehandling, 2017.
ord embeddings er faktisk en klasse av teknikker der enkelte ord er representert som reelle vektorer i et forhåndsdefinert vektorrom. Hvert ord er kartlagt til en vektor og vektorverdiene læres på en måte som ligner et nevralt nettverk, og derfor er teknikken ofte klumpet inn i feltet dyp læring.
Nøkkelen til tilnærmingen er ideen om å bruke en tett distribuert representasjon for hvert ord.
hvert ord representeres av en vektor med virkelig verdi, ofte titalls eller hundrevis av dimensjoner. Dette er i kontrast til de tusenvis eller millioner av dimensjoner som kreves for sparsomme ordrepresentasjoner, for eksempel en en-varm koding.
knytte til hvert ord i vokabularet en distribuert ordfunksjonsvektor … funksjonsvektoren representerer forskjellige aspekter av ordet: hvert ord er knyttet til et punkt i et vektorrom. Antall funksjoner … er mye mindre enn størrelsen på vokabularet
— En Neural Probabilistisk Språkmodell, 2003.
den distribuerte representasjonen læres basert på bruk av ord. Dette gjør at ord som brukes på lignende måter å resultere i å ha lignende representasjoner, naturlig fange deres mening. Dette kan kontrasteres med den skarpe, men skjøre representasjonen i en pose med ordmodell der, med mindre det er eksplisitt administrert, har forskjellige ord forskjellige representasjoner, uansett hvordan de brukes.
det er dypere språklig teori bak tilnærmingen, nemlig «fordelingshypotesen» Av Zellig Harris som kan oppsummeres som: ord som har lignende kontekst vil ha lignende betydninger. For mer dybde se Harris ‘ 1956 papir «Fordelingsstruktur».
denne oppfatningen om å la bruken av ordet definere dens betydning kan oppsummeres med En Ofte gjentatt quip Av John Firth:
Du skal kjenne et ord av selskapet det holder!
— Side 11 ,» en synopsis av lingvistisk teori 1930-1955″, I Studier I Lingvistisk Analyse 1930-1955, 1962.
Algoritmer For Embedding Av Ord
metoder for Embedding av Ord lær en virkelig verdsatt vektorrepresentasjon for et forhåndsdefinert ordforråd med fast størrelse fra et tekstkorpus.
læringsprosessen er enten felles med den nevrale nettverksmodellen på en oppgave, for eksempel dokumentklassifisering, eller er en uovervåket prosess, ved hjelp av dokumentstatistikk.
Denne delen gjennomgår tre teknikker som kan brukes til å lære et ord embedding fra tekstdata.
Innebyggingslag
et innebyggingslag, i mangel av et bedre navn, er et ordinnbyggingslag som læres sammen med en nevral nettverksmodell på en bestemt naturlig språkbehandlingsoppgave, for eksempel språkmodellering eller dokumentklassifisering.
det krever at dokumentteksten rengjøres og klargjøres slik at hvert ord er en-hot kodet. Størrelsen på vektorrommet er spesifisert som en del av modellen, for eksempel 50, 100 eller 300 dimensjoner. Vektorene er initialisert med små tilfeldige tall. Embedding laget brukes på forsiden av et nevralt nettverk og passer på en overvåket måte ved Hjelp Av Backpropagation algoritmen.
… når inngangen til et nevralt nettverk inneholder symbolske kategoriske funksjoner (f. eks. for eksempel ord fra et lukket ordforråd), er det vanlig å knytte hver mulig funksjonsverdi (dvs. hvert ord i vokabularet) med en d-dimensjonal vektor for noen d. disse vektorene betraktes da som parametere for modellen, og blir trent sammen med de andre parametrene.
— Side 49, Nevrale Nettverksmetoder I Naturlig Språkbehandling, 2017.
de en-varme kodede ordene er kartlagt til ordvektorer. Hvis en Flerlags Perceptron-modell brukes, blir ordvektorene sammenkoblet før de blir matet som inngang til modellen. Hvis et tilbakevendende nevralt nettverk brukes, kan hvert ord tas som en inngang i en sekvens.
denne tilnærmingen til å lære et innebyggingslag krever mye treningsdata og kan være treg, men vil lære en innebygging både rettet mot de spesifikke tekstdataene og nlp-oppgaven.
Word2Vec
Word2Vec er en statistisk metode for effektivt å lære et frittstående ord embedding fra en tekst corpus.
det ble utviklet Av Tomas Mikolov, et al. på Google i 2013 som et svar for å gjøre den nevrale nettverksbaserte opplæringen av embedding mer effektiv og siden da har blitt de facto-standarden for å utvikle pre-trent ordinnbygging.
I tillegg involverte arbeidet analyse av de lærte vektorer og utforskning av vektormatte på representasjoner av ord. For eksempel, som trekker «mann-ness «fra» Konge «og legger til» kvinne-ness «resulterer i ordet «Dronning», fange analogien «konge er til dronning som mann er til kvinne».
vi finner at disse representasjonene er overraskende gode til å fange syntaktiske og semantiske regulariteter i språk, og at hvert forhold er preget av en relasjonsspesifikk vektorforskyvning. Dette tillater vektororientert resonnement basert på forskyvninger mellom ord. For eksempel læres det mannlige/kvinnelige forholdet automatisk, og med de induserte vektorrepresentasjonene resulterer «King – Man + Woman» i en vektor svært nær «Queen».»
— Lingvistiske Regulariteter I Kontinuerlige Romordrepresentasjoner, 2013.
To forskjellige læringsmodeller ble introdusert som kan brukes som en del av word2vec-tilnærmingen for å lære ordet embedding; de er:
- Kontinuerlig Bag-Of-Ord, ELLER CBOW modell.
- Kontinuerlig Skip-Gram Modell.
CBBOW-modellen lærer innebygging ved å forutsi gjeldende ord basert på konteksten. Den kontinuerlige hopp-gram-modellen lærer ved å forutsi de omkringliggende ordene gitt et gjeldende ord.
den kontinuerlige skip-gram-modellen lærer ved å forutsi de omkringliggende ordene gitt et gjeldende ord.
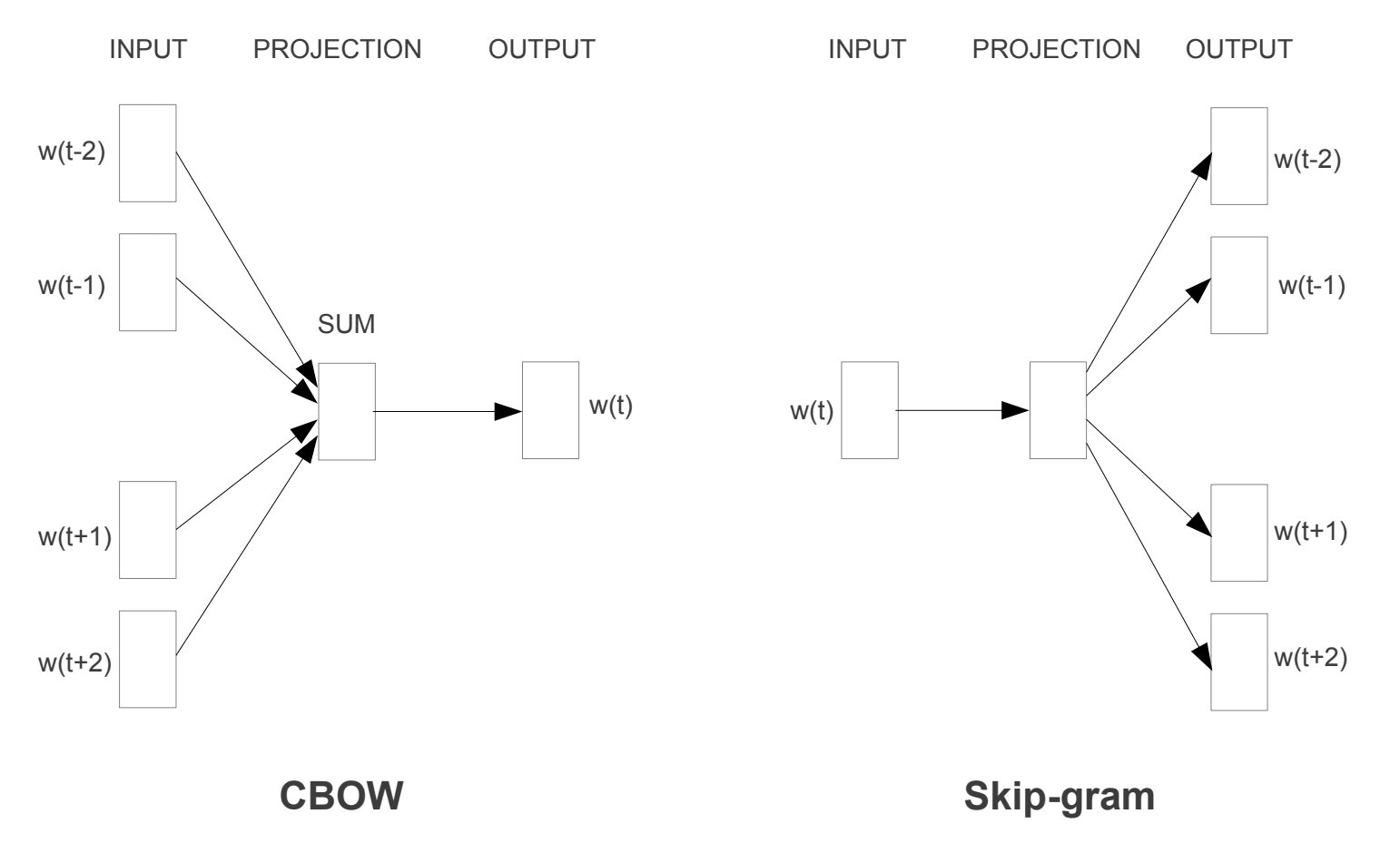
Word2Vec Treningsmodeller
Hentet fra «Effektiv Estimering Av Ordrepresentasjoner I Vektorrom», 2013
begge modellene er fokusert på å lære om ord gitt deres lokale brukskontekst, hvor konteksten er definert av et vindu av naboord. Dette vinduet er en konfigurerbar parameter av modellen.
størrelsen på skyvevinduet har en sterk effekt på de resulterende vektorlikhetene. Store vinduer har en tendens til å produsere mer aktuelle likheter, mens mindre vinduer har en tendens til å produsere mer funksjonelle og syntaktiske likheter.
— Side 128, Nevrale Nettverksmetoder I Naturlig Språkbehandling, 2017.
den viktigste fordelen med tilnærmingen er at høy kvalitet ord embeddings kan læres effektivt (lav plass og tid kompleksitet), slik at større embeddings å bli lært (flere dimensjoner) fra mye større korpus av tekst (milliarder av ord).
Hanske
Den Globale Vektorer For Ord Representasjon, eller Hanske, algoritmen er en utvidelse til word2vec metode for effektivt å lære ord vektorer, utviklet av Pennington, et al. På Stanford.
Klassiske vektorromsmodellrepresentasjoner av ord ble utviklet ved hjelp av matrisefaktoriseringsteknikker som Latent Semantisk Analyse (Lsa) som gjør en god jobb med å bruke global tekststatistikk, men er ikke så gode som de lærte metodene som word2vec til å fange mening og demonstrere det på oppgaver som å beregne analogier (f. eks. Kongen og Dronningens eksempel).
Hanske er en tilnærming til å gifte både den globale statistikken over matrisefaktoriseringsteknikker som LSA med lokal kontekstbasert læring i word2vec.
I Stedet for å bruke et vindu for å definere lokal kontekst, konstruerer Hansken en eksplisitt ordkontekst eller ordkombinasjonsmatrise ved hjelp av statistikk over hele tekstkorpuset. Resultatet er en læringsmodell som kan resultere i generelt bedre ordinnbygginger.
Hanske, er en ny global log-bilineær regresjonsmodell for ukontrollert læring av ordrepresentasjoner som overgår andre modeller på ordanalogi, ordlikhet og navngitte enhetsgjenkjenningsoppgaver.
— Hanske: Globale Vektorer For Ordrepresentasjon, 2014.
Bruke Word Embeddings
Du har noen alternativer når det gjelder å bruke word embeddings på ditt naturlige språkbehandlingsprosjekt.
denne delen skisserer disse alternativene.
Lær En Embedding
Du kan velge å lære et ord embedding for problemet ditt.
Dette vil kreve en stor mengde tekstdata for å sikre at nyttige innlemminger blir lært, for eksempel millioner eller milliarder ord.
du har to hovedalternativer når du trener ordet embedding:
- Lær Det Frittstående, der en modell er opplært til å lære innebygging, som lagres og brukes som en del av en annen modell for oppgaven senere. Dette er en god tilnærming hvis du vil bruke samme embedding i flere modeller.
- Lær I Fellesskap, hvor innlemmingen læres som en del av en stor oppgavespesifikk modell. Dette er en god tilnærming hvis du bare har tenkt å bruke embedding på en oppgave.
Gjenbruk En Embedding
det er vanlig for forskere å gjøre pre-trente ord embeddinger tilgjengelig gratis, ofte under en permissiv lisens, slik at du kan bruke dem på dine egne akademiske eller kommersielle prosjekter.
for eksempel er både word2vec og Hanske ord embeddings tilgjengelig for gratis nedlasting.
disse kan brukes på prosjektet i stedet for å trene dine egne innbygginger fra bunnen av.
du har to hovedalternativer når det gjelder å bruke pre-trent embeddings:
- Statisk, der embedding holdes statisk og brukes som en del av modellen. Dette er en passende tilnærming hvis embedding passer godt til ditt problem og gir gode resultater.
- Oppdatert, Hvor pre-trent embedding brukes til å frø modellen, men embedding oppdateres i fellesskap under trening av modellen. Dette kan være et godt alternativ hvis du ønsker å få mest mulig ut av modellen og innebygging på oppgaven.
Hvilket Alternativ Bør Du Bruke?
Utforsk de forskjellige alternativene, og hvis mulig, test for å se hvilke som gir de beste resultatene på problemet ditt.
kanskje starte med raske metoder, som å bruke en pre-trent innebygging, og bare bruke en ny innebygging hvis det resulterer i bedre ytelse på problemet.
Word Embedding Tutorials
denne delen viser noen trinnvise tutorials som du kan følge for å bruke word embeddings og bringe word embedding til prosjektet.
- Hvordan Utvikle Ordinnbygginger i Python Med Gensim
- Hvordan Bruke Ordinnbyggingslag For Dyp Læring Med Keras
- Hvordan Utvikle En Dyp CNN For Sentimentanalyse (Tekstklassifisering)
Videre Lesing
Denne delen gir flere ressurser om emnet hvis du ser gå dypere.
Artikler
- embedding Av Ord På Wikipedia
- Word2vec På Wikipedia
- Hanske På Wikipedia
- en oversikt over embedding av ord og deres tilknytning til distributionelle semantiske modeller, 2016.
- Dyp Læring, Nlp og Representasjoner, 2014.
Papirer
- Fordelingsstruktur, 1956.
- En Neural Probabilistisk Språkmodell, 2003.
- En Enhetlig Arkitektur For Naturlig Språkbehandling: Dype Nevrale Nettverk med Fleroppgavelæring, 2008.
- Modeller For Sammenhengende romspråk, 2007.
- Effektiv Estimering Av Ordrepresentasjoner I Vektorrom, 2013
- Distribuerte Representasjoner Av Ord og Uttrykk og Deres Sammensetning, 2013.
- Hanske: Globale Vektorer For Ordrepresentasjon, 2014.
Prosjekter
- word2vec På Google Code
- Hanske: Globale Vektorer For Ordrepresentasjon
Bøker
- Nevrale Nettverksmetoder I Naturlig Språkbehandling, 2017.
Sammendrag
i dette innlegget oppdaget Du Ordinnbygginger som en representasjonsmetode for tekst i dype læringsprogrammer.
spesielt lærte Du:
- hva ordet embedding tilnærming for representasjon tekst er og hvordan den skiller seg fra andre funksjonen utvinning metoder.
- At det er 3 hovedalgoritmer for å lære et ord embedding fra tekstdata.
- at du du kan enten trene en ny embedding eller bruke en pre-trent embedding på naturlig språk prosessering oppgave.
har du noen spørsmål?
Still dine spørsmål i kommentarene nedenfor, og jeg vil gjøre mitt beste for å svare.
Utvikle Dype læringsmodeller For Tekstdata I Dag!

Utvikle Dine Egne Tekstmodeller på Få Minutter
…Med bare noen få linjer med python-kode
Oppdag hvordan i min nye Ebok:
Dyp Læring For Naturlig Språkbehandling
det gir selvstudium tutorials om emner som:
Bag-Of-Ord, Ord Embedding, Språkmodeller, Bildetekst Generasjon, Tekst Oversettelse og mye mer…
Endelig Ta Med Dyp Læring til Dine Naturlige Språkbehandlingsprosjekter
Hopp Over Akademikerne. Bare Resultater.
Se Hva Som Er Inni