Als data scientist in de consumentenindustrie denk ik meestal dat het stimuleren van algoritmen voldoende is voor de meeste predictieve leertaken, althans nu. Ze zijn krachtig, flexibel en kunnen mooi worden geïnterpreteerd met enkele trucs. Dus, ik denk dat het noodzakelijk is om te lezen door middel van een aantal materialen en iets te schrijven over de stimuleren algoritmen.
de meeste inhoud in dit artikel is gebaseerd op het artikel: Boomversterking met XGBoost: waarom wint XGBoost “elke” machine Learning wedstrijd?. Het is echt een informatief document. Bijna alles met betrekking tot het stimuleren van algoritmen wordt heel duidelijk uitgelegd in de krant. Dus het papier bevat 110 pagina ‘ s 🙁
voor mij zal ik me voornamelijk richten op de drie meest populaire boosting algoritmen: AdaBoost, GBM en XGBoost. Ik heb de inhoud in twee delen verdeeld. Het eerste artikel (Dit) zal zich richten op AdaBoost algoritme, en het tweede zal zich richten op de vergelijking tussen GBM en XGBoost.
AdaBoost, kort voor “Adaptive Boosting”, is het eerste praktische Booster algoritme dat Freund en Schapire in 1996 hebben voorgesteld. Het richt zich op classificatieproblemen en heeft tot doel een reeks zwakke classifiers om te zetten in een sterke. De uiteindelijke vergelijking voor classificatie kan worden weergegeven als
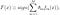
waar f_m staat voor de m_th zwakke classifier en theta_m is het overeenkomstige gewicht. Het is precies de gewogen combinatie van M zwakke classifiers. De hele procedure van het AdaBoost-algoritme kan als volgt worden samengevat.
AdaBoost-algoritme
gegeven een gegevensverzameling met n-punten, waarbij

hier staat -1 voor de negatieve klasse, terwijl 1 voor de positieve klasse staat.
Initialiseer het gewicht voor elk gegevenspunt als:

voor iteratie m = 1,…, M:
(1) pas zwakke classifiers aan op de gegevensset en selecteer degene met de laagste gewogen classificatiefout:

(2) Bereken het gewicht voor de m_th zwakke classifier:

voor elke classifier met een nauwkeurigheid van meer dan 50% is het gewicht positief. Hoe nauwkeuriger de classifier, hoe groter het gewicht. Terwijl voor de classifer met een nauwkeurigheid van minder dan 50%, het gewicht negatief is. Het betekent dat we de voorspelling combineren door het bord om te draaien. We kunnen bijvoorbeeld een classifier met een nauwkeurigheid van 40% omzetten in een nauwkeurigheid van 60% door het teken van de voorspelling om te draaien. Dus zelfs de classifier presteert slechter dan willekeurig raden, het draagt nog steeds bij aan de uiteindelijke voorspelling. We willen alleen geen classifier met exacte 50% nauwkeurigheid, die geen informatie toevoegt en dus niets bijdraagt aan de uiteindelijke voorspelling.
(3) het gewicht voor elk gegevenspunt bijwerken als:

waar Z_m een normalisatiefactor is die ervoor zorgt dat de som van alle instanties gewichten gelijk is aan 1.
indien een verkeerd geclassificeerd geval afkomstig is van een positief gewogen classificeerder, zou de term “exp” in de teller altijd groter zijn dan 1 (y*f is altijd -1, theta_m is positief). Dus verkeerd geclassificeerde gevallen zouden worden bijgewerkt met grotere gewichten na een iteratie. Dezelfde logica is van toepassing op de negatief gewogen classifiers. Het enige verschil is dat de originele correcte classificaties misclassificaties zouden worden na het omdraaien van het teken.
Na M iteratie kunnen we de uiteindelijke voorspelling verkrijgen door de gewogen voorspelling van elke classifier samen te vatten.
AdaBoost as a Forward Stagewise Additive Model
dit deel is gebaseerd op papier: Additive logistic regression: a statistical view of boosting. Voor meer gedetailleerde informatie verwijzen wij u naar het originele document.
in 2000, Friedman et al. ontwikkelde een statistische weergave van het AdaBoost algoritme. Zij interpreteerden AdaBoost als stagewise schattingsprocedures voor het aanbrengen van een additief logistisch regressiemodel. Zij toonden aan dat AdaBoost was eigenlijk het minimaliseren van de exponentiële functie verlies

Het is geminimaliseerd op

Aangezien voor AdaBoost, y kan alleen worden -1 of 1, het verlies van de functie kan worden herschreven als

Verder is op te lossen met F(x), krijgen we

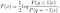
we kunnen het normale logistieke model verder afleiden uit de optimale oplossing van F (x):

het is vrijwel identiek aan het logistieke regressiemodel ondanks een factor 2.
stel dat we een huidige schatting van F(x) hebben en proberen een verbeterde schatting te zoeken F(x)+cf(x). Voor vaste c en x kunnen we L(y, F(x)+cf(x)) uitbreiden naar de tweede orde over f(x))=0,

aldus,

waarbij E_w(.|x) geeft een gewogen voorwaardelijke verwachting en het gewicht voor elk gegevenspunt wordt berekend als

Als c > 0, het minimaliseren van de gewogen voorwaardelijke verwachting is gelijk aan het maximaliseren van

Sinds y kan slechts 1 of -1 is, is het gewogen verwachting kan worden herschreven als

De optimale oplossing komt als

na het bepalen van f (x) kan het gewicht c worden berekend door L(y, F(x)+cf(x) direct te minimaliseren):

voor het Oplossen van c, dan krijgen we


Laat epsilon is gelijk aan de gewogen som van de verkeerd geclassificeerde gevallen, dan

Merk op dat c kan negatief zijn als de zwakke leerling doet slechter dan willekeurig raden (50%), in in dat geval keert het automatisch de polariteit om.
In termen van bijvoorbeeld gewichten, na de verbeterde bovendien het gewicht voor een enkel exemplaar wordt,

Dus de aanleg gewicht wordt bijgewerkt als

Vergeleken met die welke gebruikt worden in het AdaBoost algoritme,

we zien ze in identieke vorm. Daarom is het redelijk om AdaBoost te interpreteren als een forward stagewise additive model met exponentiële verliesfunctie, die iteratief past op een zwakke classifier om de huidige schatting bij elke iteratie m te verbeteren:
