er zijn ook een aantal verkeerde manieren waarop u variabelen kunt opnemen. Een zwaartekrachtmodel werkt niet tenzij elke variabele aan de volgende criteria voldoet::
- numeriek
- volledig
- betrouwbaar
numerieke gegevens alleen
aangezien het zwaartekrachtmodel een wiskundige vergelijking is, moeten alle invoervariabelen numeriek zijn. Dat kan een telling (bevolking), ruimtelijke maat (oppervlakte, afstand, enz.), tijd (uren van Londen te voet), percentage (loonstijging/ – daling), valuta waarde (lonen in shilling), of een andere maat van de plaatsen die betrokken zijn bij het model.
getallen moeten betekenisvol zijn en kunnen geen nominale categorische variabelen zijn die als stand-in voor een kwalitatieve eigenschap fungeren. U kunt bijvoorbeeld niet willekeurig een getal toewijzen en het in het model gebruiken als het getal geen betekenis heeft (bijvoorbeeld road quality = goed, of road quality = 4). Hoewel dit laatste getalsmatig is, is het geen maatstaf voor de kwaliteit van het wegverkeer. In plaats daarvan kunt u de gemiddelde rijsnelheid in mijlen per uur gebruiken als een proxy voor de kwaliteit van de weg. Of de gemiddelde snelheid een zinvolle maat is voor de kwaliteit van de weg is aan u om te bepalen en te verdedigen als de auteur van de studie.
in het algemeen, als u het kunt meten of tellen, kunt u het modelleren.
volledige gegevens alleen
alle categorieën gegevens moeten bestaan voor elk interessant punt. Dat betekent dat alle 32 onderzochte provincies betrouwbare gegevens moeten hebben voor elke push-en pull-factor. Je kunt geen gaten of lege plekken hebben, zoals een provincie waar je niet het gemiddelde loon hebt.
betrouwbare gegevens alleen
het computerwetenschappelijk adagium “garbage in, garbage out” is ook van toepassing op zwaartekrachtmodellen, die slechts zo betrouwbaar zijn als de gegevens die worden gebruikt om ze te bouwen. Naast het kiezen van robuuste en betrouwbare historische gegevens uit bronnen die u kunt vertrouwen, zijn er veel manieren om fouten te maken die de resultaten van uw model zinloos maken. Het is bijvoorbeeld de moeite waard om ervoor te zorgen dat de gegevens die u hebt precies overeenkomen met de gebieden (bijvoorbeeld county-gegevens om Provincies te vertegenwoordigen, niet city-gegevens om een provincie te vertegenwoordigen).
afhankelijk van het tijdstip en de plaats van uw studie, kunt u het moeilijk vinden om een betrouwbare reeks gegevens te verkrijgen waarop u uw model kunt baseren. Hoe verder terug in het verleden je studie, hoe moeilijker dat kan zijn. Ook kan het gemakkelijker zijn om dit soort analyses uit te voeren in samenlevingen die zwaar bureaucratisch waren en een goed bewaard gebleven papieren spoor achterlieten, zoals in Europa of Noord-Amerika.
om de kwaliteit van de gegevens in deze casestudy te garanderen, werd elke variabele betrouwbaar berekend of afgeleid van gepubliceerde peer-reviewed Historische gegevens (Zie tabel 1). Precies hoe deze gegevens werden samengesteld kan worden gelezen in het oorspronkelijke artikel waar het uitgebreid werd uitgelegd.11
onze vijf modelvariabelen
met de bovenstaande principes in gedachten hadden we een willekeurig aantal variabelen kunnen kiezen, gezien wat we wisten over migratiepush-en pull-factoren. We besloten op vijf (5), gekozen op basis van wat we dachten dat het belangrijkste zou zijn, en waarvan we wisten dat kon worden back-up met betrouwbare gegevens.
| variabele | bron |
|---|---|
| population at origin | 1771 values, Wrigley ,” English county populations”, PP. 54-5.12 |
| afstand vanaf Londen | berekend met software |
| graanprijzen | Prijzen Per Week Britse graanprijzen”13 |
| gemiddelde lonen bij de oorsprong | Hunt, “Industrialization and Regional Inequality”, blz. 965-6.14 |
| trajection of wages | Hunt, “Industrialization and Regional Inequality”, blz. 965-6.15 |
Tabel 1: De vijf variabelen die in het model worden gebruikt, en de bron van elk in de peer reviewed literatuur
nadat de coauteur van de oorspronkelijke studie, Adam Dennett, over deze variabelen had beslist, besloot hij de formule te herschrijven om deze zelfdocumenterend te maken, zodat het gemakkelijk was om te bepalen welke bits betrekking hadden op elk van deze vijf variabelen. Daarom ziet de bovenstaande formule er anders uit dan die in het oorspronkelijke onderzoekspaper. De nieuwe symbolen zijn te zien in Tabel 2:
twee extra variabelen $i$ en $j$, betekenen respectievelijk” op het punt van oorsprong “en” op Londen”. $Wa_{i}$ betekent “loonniveaus op het punt van oorsprong” terwijl $Wa_{j}$ “loonniveaus in Londen” zou betekenen. Deze zeven nieuwe symbolen kunnen de meer generieke symbolen in de formule vervangen:
\
Dit is nu uitgebreider en een enigszins zelf gedocumenteerde versie van de vorige vergelijking. Beide lossen wiskundig op precies dezelfde manier op, omdat de veranderingen puur oppervlakkig zijn en in het voordeel van een menselijke gebruiker.
de voltooide variabele Dataset
om de tutorial sneller gemakkelijker te maken, zijn de gegevens voor elk van de 5 variabelen en elk van de 32 counties al gecompileerd en schoongemaakt, en kunnen worden bekeken in Tabel 3 of gedownload als een csv-bestand. Deze tabel bevat ook het bekende aantal zwervers uit dat Graafschap, zoals waargenomen in het primaire bronrecord:
| County | Landlopers | $d$ km naar Londen | $P$ Bevolking (personen) | $Wa$ Gemiddelde Loon (shillings) | $WaT$ Loon Traject 1767-95 (verandering in%) | $Wh$ Tarwe Prijs (shillings) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornwall | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
Het uiteindelijke verschil tussen deze formule wordt gebruikt dan in het originele artikel, is dat twee van de variabelen gebeuren om een sterkere relatie met landloperij wanneer uitgezet natuurlijk logaritmisch. Ze zijn bevolking bij oorsprong ($P$) en afstand van oorsprong naar Londen ($d$). Wat dit betekent is dat Voor de gegevens in deze studie, de regressielijn (soms genoemd regel van best fit) is een betere pasvorm wanneer de gegevens zijn gelogd dan wanneer het niet is geweest. U kunt dit zien in Figuur 7, met de niet-gelogde populatie cijfers aan de linkerkant, en de gelogde versie aan de rechterkant. Meer van de punten liggen dichter bij de regel van best fit op de gelogde grafiek dan op de niet-gelogde.
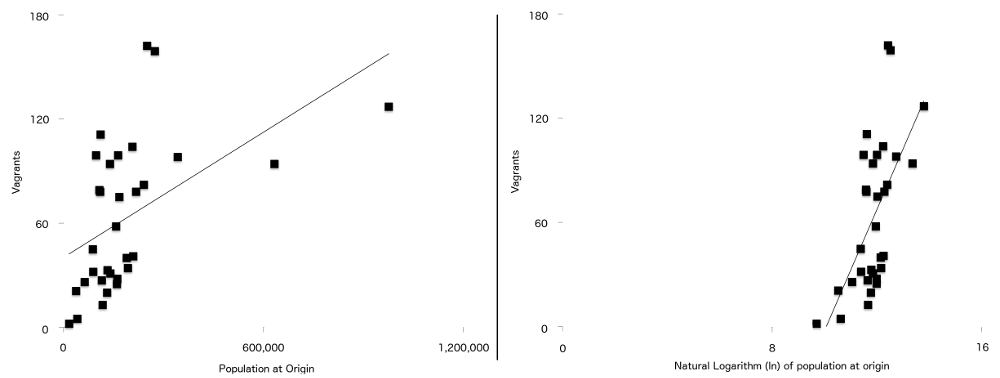
Figuur 7: Aantal zwervers uitgezet tegen populatie bij oorsprong (links), en natuurlijk log van populatie van oorsprong (rechts)met een eenvoudige regressielijn op beide. Let op de sterkere relatie tussen de twee variabelen zichtbaar op de tweede grafiek.
omdat dit het geval is met deze specifieke gegevens (uw eigen gegevens in een vergelijkbaar type studie kunnen dit patroon niet volgen), werd de formule aangepast om de natuurlijk gelogde versies van deze twee variabelen te gebruiken, resulterend in de uiteindelijke formule die wordt gebruikt in het zwaartekrachtmodel (Figuur 8). We hadden onmogelijk kunnen weten over de noodzaak van deze aanpassing tot nadat we onze variabele gegevens hadden verzameld:
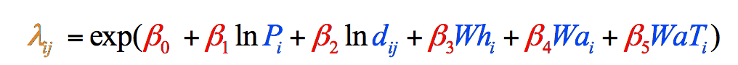
Figuur 8: de uiteindelijke formule van het zwaartekrachtmodel, opgesplitst in stappen en met een kleurcode. Elementen in het zwart zijn wiskundige bewerkingen. Elementen in blauw vertegenwoordigen onze variabelen, die we zojuist hebben verzameld (Stap 1). Elementen in rood vertegenwoordigen de wegingen van elke variabele, die we moeten berekenen (Stap 2), en het Element in Oranje is de uiteindelijke schatting van zwervers uit dat Graafschap, die we kunnen berekenen zodra we de andere informatie hebben (Stap 3).
de waarden in Tabel 3 geven ons alles wat we nodig hebben om de blauwe delen van elke vergelijking in Figuur 8 in te vullen. We kunnen nu onze aandacht richten op de rode delen, die ons vertellen hoe belangrijk elke variabele is in het model overall, en geeft ons de nummers die we nodig hebben om de vergelijking te voltooien.
Stap 2: Bepaling van de wegingen
de wegingen voor elke variabele vertellen ons hoe belangrijk de push – /pull-factor is ten opzichte van de andere variabelen bij het schatten van het aantal zwervers dat uit een bepaald Graafschap had moeten komen. De$ β $ parameters moeten worden bepaald over de hele dataset van de bekende gegevens. Met deze bij de hand kunnen we individuele origine-specifieke observaties vergelijken met het algemene model. We kunnen deze dan onderzoeken en over en onder voorspelde stromen tussen de verschillende oorsprong en de bestemming identificeren.
in dit stadium weten we niet hoe belangrijk elk is. Misschien is tarweprijs een betere voorspeller van migratie dan Afstand? We zullen het niet weten totdat we de waarden van $β1$ door $β5$ (de wegingen) berekenen door de vergelijking hierboven op te lossen. De Y-ordinaat ($β0$) kan alleen worden berekend als je alle anderen kent ($β1-β5$). Dit zijn de rode waarden in Figuur 8 hierboven. De wegingen zijn te zien in Tabel 4 en in tabel A1 van het oorspronkelijke document.16 We zullen nu laten zien hoe we tot deze waarden zijn gekomen.
om deze waarden te berekenen vereist long-hand een ongelooflijke hoeveelheid werk. We zullen een snelle oplossing in de R-programmeertaal gebruiken die gebruik maakt van William Venables en Brian Ripley ‘ s MASSAPAKKET dat negatieve binomiale regressievergelijkingen zoals ons zwaartekrachtmodel kan oplossen met één regel code. Het is echter belangrijk om de principes achter wat men doet te begrijpen om te waarderen wat de code doet (merk op dat de volgende secties niet de berekening doen, maar de stappen voor u uitleggen; we zullen de berekening met de code verderop in de pagina doen).
de berekening van de individuele wegingen (in principe)
$ β_{1}$, $β_{2}$, enz. is gelijk aan $β$ in het eenvoudige lineaire regressiemodel hierboven, dat de helling van de regressielijn is (de stijging over de loop, of hoeveel $y $ toeneemt wanneer $x$ met 1 toeneemt). Het enige verschil tussen een eenvoudige lineaire regressie en ons zwaartekrachtmodel is dat we 5 hellingen moeten berekenen in plaats van 1.
een eenvoudige lineaire regressie\(y = α + ßx\)
moeten we oplossen voor elk van deze vijf hellingen voordat we de Y-as kunnen berekenen in de volgende stap. Dat komt omdat de hellingen van de verschillende $β$ waarden deel uitmaken van de vergelijking voor het berekenen van de Y-as.
de formule voor het berekenen van $ β$ in een regressieanalyse is::
\
Pearson ’s correlatiecoëfficiënt
Pearson’ s correlatiecoëfficiënt kan long-hand worden berekend, maar het is een vrij lange berekening in dit geval, waarvoor 64 getallen nodig zijn. Er zijn een aantal grote video tutorials in het Engels online beschikbaar als u wilt zien een walk-through van hoe de berekeningen lange hand te doen.17 Er zijn ook een aantal online rekenmachines die $r$ voor u berekenen als u de gegevens. Gezien het grote aantal cijfers om te berekenen, zou ik een website aanraden met een ingebouwde tool die is ontworpen om deze berekening te maken. Zorg ervoor dat u kiest voor een gerenommeerde site, zoals een aangeboden door een universiteit.
het berekenen van $s_{y}$ & $s_{x}$ (standaardafwijking)
standaardafwijking is een manier om uit te drukken hoeveel variatie er is ten opzichte van het gemiddelde (gemiddelde) in de gegevens. Met andere woorden, zijn de gegevens vrij geclusterd rond het gemiddelde, of is de verspreiding veel breder?
ook hier zijn er online rekenmachines en statistische softwarepakketten die deze berekening voor u kunnen uitvoeren als u de gegevens verstrekt.
het berekenen van $β_{0}$ (De Y-as)
vervolgens moeten we de Y-as berekenen. De formule voor het berekenen van de Y-ordinaat in een eenvoudige lineaire regressie is:
\
de berekening wordt echter veel ingewikkelder in een meervoudige regressieanalyse, omdat elke variabele de berekening beïnvloedt. Dit maakt het met de hand doen erg moeilijk, en is een van de redenen waarom we kiezen voor een programmatische oplossing.
de code voor de berekening van de wegingen
het statistisch MASSAPAKKET, geschreven voor de programmeertaal R, heeft een functie die negatieve binomiale regressievergelijkingen kan oplossen, waardoor het zeer eenvoudig is om te berekenen wat anders een zeer moeilijke formule met lange hand zou zijn.
in deze sectie wordt ervan uitgegaan dat u R hebt geïnstalleerd en het MASS package hebt geïnstalleerd. Als u dat niet hebt gedaan, moet u dat doen voordat u verder gaat. Taryn Dewar ‘ s tutorial over R Basics met tabelgegevens bevat R installatie-instructies.
om deze code te gebruiken, moet u een kopie downloaden van de dataset van de vijf variabelen plus het aantal waargenomen zwervers uit elk van de 32 provincies. Dit is hierboven beschikbaar als Tabel 3, of kan worden gedownload als een .csv-bestand. Welke modus u ook kiest, sla het bestand op als VagrantsExampleData.csv. Als u een Mac gebruikt, zorg er dan voor dat u deze opslaat als een Windows-indeling .csv-bestand. Open VagrantsExampleData.csv en vertrouwd te raken met de inhoud ervan. Je moet elk van de 32 provincies opmerken, samen met elk van de variabelen die we hebben besproken in deze tutorial. We zullen de kolomkoppen gebruiken om toegang te krijgen tot deze gegevens met ons computerprogramma. Kon ik hen geroepen heb van alles, maar in dit bestand zijn ze:
vagrantspopulationdistancewheatwageswageTrajectory
In dezelfde map als u het csv-bestand maken en opslaan van een nieuwe R-script-bestand (u kunt dit doen met een tekst-editor of met RStudio, maar maak geen gebruik van een tekstverwerker als MS word). Sla het op als gewichtsberekeningen.r.
we zullen nu een kort programma schrijven dat:
- installeert het MASSAPAKKET
- roept het MASSAPAKKET aan, zodat we het kunnen gebruiken in onze code
- slaat de inhoud van het op .csv-bestand naar een variabele die we programmatisch kunnen gebruiken
- lost de vergelijking van het zwaartekrachtmodel op met behulp van de dataset
- voert de resultaten van de berekening uit.
elk van deze taken zal beurtelings worden uitgevoerd met een enkele regel code
kopieer de bovenstaande code in uw weegberekeningen.R bestand en opslaan. U kunt nu de code uitvoeren met behulp van uw favoriete R omgeving (Ik gebruik RStudio) en de resultaten van de berekening moeten verschijnen in het consolevenster (hoe dit eruit ziet zal afhangen van uw omgeving). Het kan nodig zijn om de werk Directory van uw R omgeving in te stellen op de directory die uw bevat .csv en .r bestanden. Als u RStudio gebruikt, kunt u dit doen via de menu ‘ s (sessie -> werkmap instellen -> map kiezen). U kunt ook hetzelfde bereiken met het commando:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundmerk op dat Lijn 4 de lijn is die de vergelijking voor ons oplost, met behulp van de glm.nb-functie, een afkorting voor”generalized linear model – negative binomial”. Deze lijn vereist een aantal ingangen:
- onze variabelen met behulp van de kolom headers zoals geschreven in de .csv-bestand, samen met elke logging die moet worden gedaan om hen (
vagrants, log (population), log(distance),wheat,wages,wageTrajectory). Als u een model met uw eigen gegevens zou draaien, zou u deze aanpassen om uw kolomkoppen in uw dataset weer te geven. - waar de code de gegevens kan vinden-in dit geval een variabele die we hebben gedefinieerd in regel 3 genaamd
gravityModelData.
de resultaten van de berekening zijn te zien in Figuur 9:
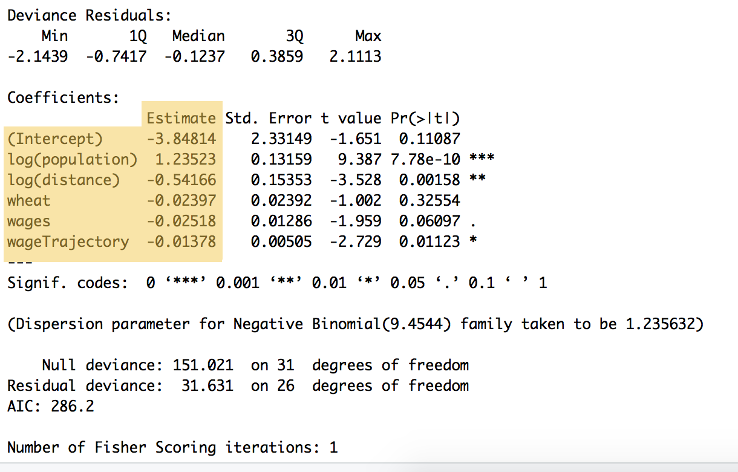
figuur 9: de samenvatting van de bovenstaande code, met de wegingen voor elke variabele en de Y-as, vermeld onder de rubriek ‘schatting’ ($\beta_{0}$ tot $\beta_{5}$. Deze samenvatting toont ook een aantal andere berekeningen, waaronder statistische significantie.
Stap 3: Het berekenen van de schattingen voor elke County
moeten we dit één keer doen voor elk van de 32 county ‘ s.
u kunt dit doen met een wetenschappelijke rekenmachine, door een spreadsheetformule aan te maken of door een computerprogramma te schrijven. Om dit automatisch in R te doen, kunt u het volgende aan uw code toevoegen en het programma opnieuw uitvoeren. Deze for lus berekent het verwachte aantal vagrants van elk van de 32 counties in het voorbeeld en drukt de resultaten af zodat u ze kunt zien:
om begrip op te bouwen, stel ik voor om één county long-hand te doen. Deze tutorial zal Hertfordshire gebruiken als het lange-hand voorbeeld (maar het proces is precies hetzelfde voor de andere 31 graafschappen).
met behulp van de gegevens voor Hertfordshire in Tabel 3, en de wegingen voor elke variabele in Tabel 4, kunnen we nu onze formule invullen, die het resultaat van 95 geeft:
laten we eerst de symbolen voor de getallen uit de bovenstaande tabellen omwisselen.
begin dan met het berekenen van waarden om tot de schatting te komen. Het onthouden van wiskundige volgorde van operaties, vermenigvuldig waarden voor het toevoegen. Dus begin met het berekenen van elke variabele (je kunt hiervoor een wetenschappelijke rekenmachine gebruiken):
de volgende stap is om de getallen bij elkaar op te tellen:
estimated vagrants = exp(4.56232408897)en tot slot, om de exponentiële functie te berekenen (gebruik een wetenschappelijke rekenmachine):
estimated vagrants = 95.8059926832We hebben de rest laten vallen en verklaard dat het Geschatte aantal zwervers uit Hertfordshire in dit model 95 is. Je moet dezelfde berekeningen uitvoeren voor elk van de andere provincies, die je zou kunnen versnellen met behulp van een spreadsheet programma. Om er zeker van te zijn dat u het opnieuw kunt doen, heb ik ook de getallen voor Buckinghamshire opgenomen:
Hertfordshire
\
Buckinghamshire
\
Ik adviseer om een andere county te kiezen en deze met lange hand te berekenen voordat u verder gaat, om ervoor te zorgen dat u de berekeningen zelf kunt uitvoeren. Het juiste antwoord is te vinden in Tabel 5, waarin de waargenomen waarden (zoals te zien in het primaire bronrecord) worden vergeleken met de geschatte waarden (zoals berekend door ons zwaartekrachtmodel). Het “restant” is het verschil tussen de twee, met een groot verschil dat wijst op een onverwacht aantal zwervers die misschien een kijkje waard zijn met de hoed van een historicus op.
| County | Waargenomen Waarde | Geschatte Waarde | Resterende |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornwall | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Warwickshire | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Stap 4 – Historische Interpretatie
In dit stadium, de modellering proces is voltooid en de laatste fase is de historische interpretatie.
het oorspronkelijk gepubliceerde artikel waarop deze casestudy is gebaseerd, is voornamelijk gewijd aan het interpreteren van wat de resultaten van de modellering betekenen voor ons begrip van de lagere klassenmigratie in de achttiende eeuw. Zoals te zien in de kaart in Figuur 5, waren er delen van het land die het model sterk suggereerde waren ofwel over – of onder-sturen lagere klasse migranten naar Londen.
de coauteurs gaven hun interpretaties aan waarom deze patronen zijn verschenen. Deze interpretaties varieerden per plaats. In gebieden in het noorden van Engeland die snel industrialiseerden, zoals Yorkshire of Manchester, leken de lokale mogelijkheden mensen minder redenen te geven om te vertrekken, wat resulteerde in een lager dan verwachte migratie naar Londen. In afnemende gebieden in het Westen, zoals Bristol, was de verleiding van Londen sterker als meer mensen vertrokken op zoek naar werk in de hoofdstad.
niet alle patronen werden verwacht. Northumberland in het verre noordoosten bleek een regionale anomalie te zijn en stuurde veel meer (vrouwelijke) migranten naar Londen dan we zouden verwachten. Zonder de resultaten van het model, is het onwaarschijnlijk dat we zouden hebben gedacht om Northumberland helemaal te overwegen, vooral omdat het was zo ver van de metropool en we veronderstelden zou zwakke banden met Londen hebben. Het model leverde dus nieuw bewijs voor ons om als historici te beschouwen en veranderde ons begrip van de relatie tussen Londen en Northumberland. Een volledige bespreking van onze bevindingen kan worden gelezen in het oorspronkelijke artikel.18
uw kennis vooruit helpen
nadat u dit voorbeeldprobleem hebt geprobeerd, moet u duidelijk weten hoe u deze voorbeeldformule moet gebruiken en of een zwaartekrachtmodel een geschikte oplossing voor uw onderzoeksprobleem kan zijn. Je hebt de ervaring en woordenschat om zwaartekrachtmodellen te benaderen en te bespreken met een geschikte wiskundig geletterde medewerker, mocht dat nodig zijn, die je kan helpen om het aan te passen aan je eigen casestudy.
als je het geluk hebt om ook gegevens te hebben over migranten die naar het eind van de achttiende eeuw in Londen verhuizen en je wilt het modelleren met dezelfde vijf variabelen die hierboven zijn vermeld, zou deze formule werken zoals-is – er is een eenvoudige studie hier voor iemand met de juiste gegevens. Dit model werkt echter niet alleen voor studies over migranten die naar Londen verhuizen. De variabelen kunnen veranderen en de bestemming hoeft niet Londen te zijn. Het zou mogelijk zijn om een zwaartekrachtmodel te gebruiken om migratie naar het oude Rome te bestuderen, of eenentwintigste eeuw Bangkok, als je de gegevens en de onderzoeksvraag hebt. Het hoeft niet eens een model van migratie te zijn. Om gebruik te maken van de Colombiaanse koffie case study uit de inleiding, die zich richt op handel in plaats van migratie, Tabel 6 toont een levensvatbaar gebruik van dezelfde formule, ongewijzigd.
| Criteria | Koffie Exporteren Voorbeeld |
|---|---|
| EEN punt van oorsprong | koffie-export vanuit de haven van Barranquilla, Colombia |
| MEERDERE eindige bestemmingen | de 21 landen van het Westelijk Halfrond in 1950 |
| VIJF verklarende variabelen | (1) nummer van de Atlantische Oceaan poorten in het ontvangende land (2) km van Colombia (3) Bruto Binnenlands Product van het ontvangende land, (4) Binnenlandse Koffie geteeld in de ton, (5) coffeeshops per 10.000 mensen |
er is een lange geschiedenis van zwaartekrachtmodellen in de academische wetenschap. Om een effectief te gebruiken voor onderzoek, moet je de basistheorie en wiskunde achter hen en de redenen die ze hebben ontwikkeld als ze hebben begrijpen. Het is ook belangrijk om hun beperkingen en voorwaarden voor het gebruik ervan goed te begrijpen, waarvan sommige hierboven zijn besproken. Het kan ook helpen om te weten:
-
een zwaartekrachtmodel zoals dat in dit voorbeeld wordt gebruikt, kan alleen in een gesloten systeem werken. Het bovenstaande model had slechts 32 mogelijke punten van herkomst, waardoor het mogelijk was om het model 32 keer te draaien. Een onbekend of oneindig groot aantal punten van herkomst (of bestemmingen afhankelijk van uw model), zou een andere vergelijking vereisen.
-
het concept van het zwaartekrachtmodel is ook gebaseerd op de vooronderstelling dat bewegingen (migratie, handel, enz.) gebaseerd zijn op een verzameling vrijwillige individuele beslissingen die door externe factoren kunnen worden beïnvloed, maar niet volledig door hen worden beheerst. Vrijwillige migraties of aankopen uit vrije wil kunnen bijvoorbeeld worden gemodelleerd met behulp van deze techniek, maar gedwongen migratie, verplichte aankoop of natuurlijke processen zoals vogeltrek of rivierstroming kunnen niet dezelfde principes volgen en daarom kan een ander type model nodig zijn.
-
Zwaartekrachtmodellen kunnen worden gebruikt om het gedrag van populaties te voorspellen, maar niet van individuen, en daarom moeten pogingen om gegevens te modelleren een groot aantal bewegingen omvatten om statistische significantie te garanderen.
er zijn veel meer valkuilen, maar ook enorme mogelijkheden. Het is mijn hoop dat deze doorloop van een zwaartekrachtmodel, en het bijbehorende gepubliceerde onderzoek, dit krachtige instrument toegankelijker zal maken voor historici. Als u van plan bent om een zwaartekrachtmodel te gebruiken in uw wetenschappelijk onderzoek, raadt de auteur ten zeerste de volgende artikelen aan:
Dankbetuigingen
met dank aan Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas en Leanne Calvert voor het lezen en becommentariëren van eerdere ontwerpen van dit artikel. Ook met dank aan de British Academy voor de financiering van de schrijfworkshop in Bogotá, Colombia waar dit artikel werd opgesteld. En tot slot op Adam Dennett voor het introduceren van deze prachtige formules en het ontketenen van hun potentieel voor historici.