laatst bijgewerkt op 7 augustus 2019
Woordinbeddingen zijn een type woordweergave waarmee woorden met een vergelijkbare betekenis een vergelijkbare representatie kunnen hebben.
ze zijn een gedistribueerde representatie voor tekst die misschien een van de belangrijkste doorbraken is voor de indrukwekkende prestaties van deep learning-methoden bij uitdagende problemen met de verwerking van natuurlijke talen.
in dit bericht vindt u de benadering van het inbedden van woorden voor het weergeven van tekstgegevens.
na het voltooien van dit bericht, zult u weten:
- wat het woord inbedden benadering voor het vertegenwoordigen van tekst is en hoe het verschilt van andere functie extractie methoden.
- dat er 3 hoofdalgoritmen zijn om een woord te leren inbedden uit tekstgegevens.
- dat u een nieuwe inbedding kunt trainen of een vooraf getrainde inbedding kunt gebruiken voor uw taak voor het verwerken van natuurlijke taal.
start uw project met mijn nieuwe boek Deep Learning voor natuurlijke taalverwerking, inclusief stap-voor-stap tutorials en de Python broncode bestanden voor alle voorbeelden.
laten we beginnen.

Wat zijn Woordinbeddingen voor tekst?
foto door Heather, enkele rechten voorbehouden.
- overzicht
- hulp nodig met Deep Learning voor tekstgegevens?
- Wat zijn Woordinbeddingen?
- algoritmen voor het inbedden van woorden
- Embedding Layer
- Word2Vec
- Woordinbeddingen gebruiken
- Leer een inbedding
- hergebruik een inbedding
- Welke Optie Moet U Gebruiken?
- Tutorials voor Woordinbedding
- verder lezen
- artikelen
- papier
- Projects
- Books
- samenvatting
- ontwikkel Deep Learning modellen voor tekst Data vandaag!
- Ontwikkel uw eigen Tekstmodellen in minuten
- ten slotte Deep Learning brengen in uw natuurlijke Taalverwerkingsprojecten
overzicht
dit bericht is verdeeld in 3 delen; :
- Wat zijn Woordinbeddingen?
- algoritmen voor Woordinbedding
- met behulp van Woordinbeddingen
hulp nodig met Deep Learning voor tekstgegevens?
Volg nu mijn gratis 7-daagse e-mail spoedcursus (met code).
klik om u aan te melden en ontvang ook een gratis PDF Ebook versie van de cursus.
Start nu uw gratis spoedcursus
Wat zijn Woordinbeddingen?
een woordinbedding is een geleerde representatie voor tekst waarbij woorden met dezelfde betekenis een soortgelijke representatie hebben.
het is deze benadering van het weergeven van woorden en documenten die kan worden beschouwd als een van de belangrijkste doorbraken van deep learning op uitdagende natuurlijke taalverwerkingsproblemen.
een van de voordelen van het gebruik van dichte en laagdimensionale vectoren is computationeel: de meerderheid van neurale netwerk toolkits niet goed spelen met zeer hoog-dimensionale, schaarse vectoren. … Het belangrijkste voordeel van de dichte representaties is generalisatiekracht: als we geloven dat sommige functies soortgelijke aanwijzingen kunnen bieden, is het de moeite waard om een representatie te bieden die in staat is om deze overeenkomsten vast te leggen.
— pagina 92, Neural Network Methods in Natural Language Processing, 2017.
Woordinbeddingen zijn in feite een klasse van technieken waarbij individuele woorden worden weergegeven als reële vectoren in een vooraf gedefinieerde vectorruimte. Elk woord wordt in kaart gebracht aan één vector en de vectorwaarden worden geleerd op een manier die op een neuraal netwerk lijkt, en vandaar wordt de techniek vaak op een hoop gegooid op het gebied van diep leren.
de sleutel tot de aanpak is het idee om voor elk woord een dichte gedistribueerde representatie te gebruiken.
elk woord wordt weergegeven door een reële vector, vaak tientallen of honderden dimensies. Dit staat in contrast met de duizenden of miljoenen dimensies die nodig zijn voor schaarse woordrepresentaties, zoals een one-hot codering.
associeer met elk woord in de woordenschat een gedistribueerde woordeigenschap … de eigenschap-vector vertegenwoordigt verschillende aspecten van het woord: elk woord wordt geassocieerd met een punt in een vectorruimte. Het aantal functies … is veel kleiner dan de grootte van de woordenschat
— a Neural Probabilistic Language Model, 2003.
de gedistribueerde weergave wordt geleerd op basis van het gebruik van woorden. Dit maakt het mogelijk dat woorden die op vergelijkbare manieren worden gebruikt, resulteren in vergelijkbare representaties, waardoor hun betekenis op natuurlijke wijze wordt vastgelegd. Dit kan worden vergeleken met de scherpe maar fragiele representatie in een zak woorden model waar, tenzij expliciet beheerd, verschillende woorden hebben verschillende representaties, ongeacht hoe ze worden gebruikt.
er is een diepere linguïstische theorie achter de benadering, namelijk de “verdelingshypothese” van Zellig Harris die kan worden samengevat als: woorden die een vergelijkbare context hebben, zullen dezelfde betekenissen hebben. Voor meer diepte zie Harris ‘1956 paper ” Distributional structure”.
deze notie om het gebruik van het woord de betekenis ervan te laten bepalen kan worden samengevat door een vaak herhaalde uitspraak van John Firth:
u zult een woord kennen van het bedrijf dat het houdt!
— Page 11, “A synopsis of linguistic theory 1930-1955”, in Studies in Linguistic Analysis 1930-1955, 1962.
algoritmen voor het inbedden van woorden
methoden voor het inbedden van woorden Leer een reële vectorweergave voor een vooraf gedefinieerde woordenschat van vaste grootte uit een corpus van tekst.
het leerproces is ofwel verbonden met het neurale netwerkmodel voor een bepaalde taak, zoals documentclassificatie, ofwel is het een proces zonder toezicht, waarbij gebruik wordt gemaakt van documentstatistieken.
in deze sectie worden drie technieken besproken die kunnen worden gebruikt om een woord te leren inbedden uit tekstgegevens.
Embedding Layer
een inbedding laag is, bij gebrek aan een betere naam, Een woord inbedding die samen met een neuraal netwerkmodel wordt geleerd op een specifieke natuurlijke taalverwerkingstaak, zoals taalmodellering of documentclassificatie.
het vereist dat de tekst van het document zodanig wordt opgeschoond en voorbereid dat elk woord één-hot gecodeerd is. De grootte van de vectorruimte wordt gespecificeerd als onderdeel van het model, zoals 50, 100 of 300 dimensies. De vectoren worden geïnitialiseerd met kleine willekeurige getallen. De inbedding laag wordt gebruikt op de front-end van een neuraal netwerk en is geschikt op een gecontroleerde manier met behulp van de Backpropagation algoritme.
… wanneer de invoer van een neuraal netwerk symbolische categorische kenmerken bevat (bijv. functies die een van k verschillende symbolen, zoals woorden uit een gesloten woordenschat), is het gebruikelijk om elke mogelijke functie waarde (dat wil zeggen, elk woord in de woordenschat) te associëren met een D-dimensionale vector voor sommige d. deze vectoren worden dan beschouwd als parameters van het model, en worden getraind samen met de andere parameters.
— pagina 49, Neural Network Methods in Natural Language Processing, 2017.
de één-hot gecodeerde woorden worden toegewezen aan de woordvectoren. Als een meerlagig Perceptron model wordt gebruikt, dan worden de woordvectoren aaneengeschakeld alvorens als input aan het model te worden ingevoerd. Als een terugkerend neuraal netwerk wordt gebruikt, dan kan elk woord worden genomen als een ingang in een reeks.
deze benadering van het leren van een inbeddinglaag vereist veel trainingsgegevens en kan traag zijn, maar zal een inbedding leren die zowel gericht is op de specifieke tekstgegevens als op de NLP-taak.
Word2Vec
Word2Vec is een statistische methode voor het efficiënt leren van een zelfstandig woord inbedding uit een tekstcorpus.Het werd ontwikkeld door Tomas Mikolov, et al. bij Google in 2013 als reactie op de neurale-netwerk-gebaseerde training van de inbedding efficiënter te maken en sindsdien is uitgegroeid tot de de facto standaard voor het ontwikkelen van pre-getrainde woord inbedding.
daarnaast omvatte het werk de analyse van de geleerde vectoren en de exploratie van vectormath op de representaties van woorden. Bijvoorbeeld, dat het aftrekken van de “man-heid” van “koning” en het toevoegen van “vrouw-heid” resulteert in het woord “koningin”, het vastleggen van de analogie “koning is tot koningin als man is tot vrouw”.
we vinden dat deze representaties verrassend goed zijn in het vastleggen van syntactische en semantische regulariteiten in taal, en dat elke relatie wordt gekenmerkt door een relatiespecifieke Vector offset. Dit staat vector-georiënteerd redeneren toe op basis van de offsets tussen woorden. Bijvoorbeeld, de man/vrouw relatie wordt automatisch geleerd, en met de geïnduceerde Vector voorstellingen, “koning – Man + Vrouw” resulteert in een vector zeer dicht bij ” Koningin.”
— Linguistic Regularities in Continuous Space Word Representations, 2013.
twee verschillende leermodellen werden geïntroduceerd die kunnen worden gebruikt als onderdeel van de word2vec-benadering om het woord inbedding te leren; ze zijn:
- continue Bag-of-Words, of CBOW model.
- Continu Skip-Grammodel.
het CBOW-model leert de inbedding door het huidige woord te voorspellen op basis van zijn context. Het continue skip-gram model leert door het voorspellen van de omringende woorden gegeven een actueel woord.
het continue skip-gram model leert door het voorspellen van de omringende woorden gegeven een actueel woord.
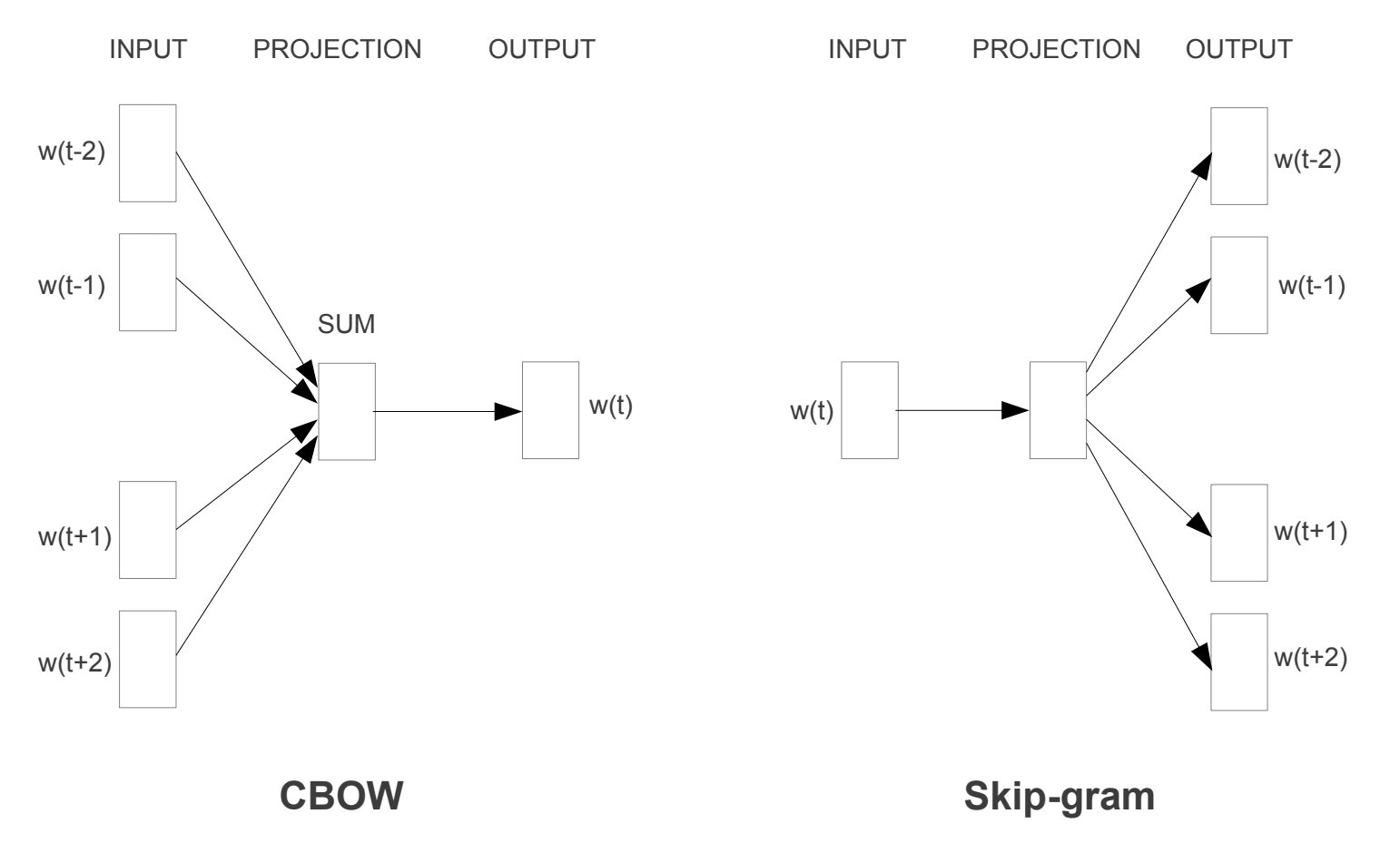
Word2Vec-opleidingsmodellen
ontleend aan “Efficient Estimation of Word Representations in Vector Space””, 2013
beide modellen zijn gericht op het leren over woorden gezien hun lokale gebruik context, waarbij de context wordt gedefinieerd door een venster van naburige woorden. Dit venster is een configureerbare parameter van het model.
de grootte van het schuifraam heeft een sterk effect op de resulterende vector gelijkenissen. Grote vensters hebben de neiging om meer actuele gelijkenissen te produceren, terwijl kleinere vensters hebben de neiging om meer functionele en syntactische gelijkenissen te produceren.
— pagina 128, Neural Network Methods in Natural Language Processing, 2017.
het belangrijkste voordeel van de aanpak is dat woordinbeddingen van hoge kwaliteit efficiënt kunnen worden geleerd (lage ruimte-en tijdcomplexiteit), waardoor grotere inbeddingen (meer dimensies) kunnen worden geleerd van veel grotere corpora van tekst (miljarden woorden).Handschoen
de Globale vectoren voor Woordrepresentatie, of Handschoen, algoritme is een uitbreiding van de word2vec methode voor het efficiënt leren van woordvectoren, ontwikkeld door Pennington, et al. op Stanford.
klassieke vectorruimte modelrepresentaties van woorden werden ontwikkeld met behulp van Matrix factorisatie technieken zoals latente semantische analyse (LSA) die goed werk doen van het gebruik van globale tekststatistieken, maar niet zo goed zijn als de geleerde methoden zoals word2vec in het vastleggen van betekenis en het demonstreren van deze op taken zoals het berekenen van analogieën (bijv. de koning en Koningin voorbeeld hierboven).GloVe is een benadering om zowel de globale statistieken van Matrix factorisatie technieken zoals LSA te combineren met het lokale context-based learning in word2vec.
in plaats van een venster te gebruiken om de lokale context te definiëren, construeert GloVe een expliciete woordcontext of een co-occurrence matrix met behulp van statistieken over het hele tekstcorpus. Het resultaat is een leermodel dat kan resulteren in over het algemeen betere woordinbeddingen.
GloVe, is een nieuw globaal log-bilineair regressiemodel voor het zonder toezicht leren van woordrepresentaties die beter presteren dan andere modellen op woordanalogie, woordgelijkheidstaken en named entity recognition-taken.
— Handschoen: Global Vectors for Word Representation, 2014.
Woordinbeddingen gebruiken
u hebt enkele opties wanneer het tijd is om woordinbeddingen te gebruiken in uw project voor natuurlijke taalverwerking.
in deze paragraaf worden deze opties beschreven.
Leer een inbedding
u kunt ervoor kiezen om een woord inbedding te leren voor uw probleem.
dit vereist een grote hoeveelheid tekstgegevens om ervoor te zorgen dat nuttige inbeddingen worden geleerd, zoals miljoenen of miljarden woorden.
u hebt twee hoofdopties bij het trainen van uw woordinbedding:
- Leer Het Standalone, waar een model wordt getraind om de inbedding te leren, die later wordt opgeslagen en gebruikt als onderdeel van een ander model voor uw taak. Dit is een goede aanpak als u dezelfde inbedding in meerdere modellen wilt gebruiken.
- gezamenlijk leren, waarbij de inbedding wordt geleerd als onderdeel van een groot taakspecifiek model. Dit is een goede aanpak als u alleen van plan om de inbedding te gebruiken op een taak.
hergebruik een inbedding
het is gebruikelijk dat onderzoekers voorgetrainde woordinbeddingen gratis beschikbaar stellen, vaak onder een permissieve licentie, zodat u ze kunt gebruiken voor uw eigen academische of commerciële projecten.
bijvoorbeeld, zowel word2vec als GloVe word embeddings zijn beschikbaar voor gratis download.
deze kunnen op uw project worden gebruikt in plaats van uw eigen inbeddingen vanaf nul te trainen.
u hebt twee hoofdopties als het gaat om het gebruik van voorgetrainde inbeddingen:
- statisch, waarbij de inbedding statisch wordt gehouden en wordt gebruikt als onderdeel van uw model. Dit is een geschikte aanpak als de inbedding een goede pasvorm is voor uw probleem en goede resultaten oplevert.
- bijgewerkt, waarbij de voorgetrainde inbedding wordt gebruikt om het model te zaaien, maar de inbedding gezamenlijk wordt bijgewerkt tijdens de training van het model. Dit kan een goede optie zijn als u op zoek bent om het meeste uit het model te krijgen en inbedding op uw taak.
Welke Optie Moet U Gebruiken?
verken de verschillende opties, en indien mogelijk, test om te zien welke de beste resultaten geeft op uw probleem.
begin misschien met snelle methoden, zoals het gebruik van een vooraf getrainde inbedding, en gebruik alleen een nieuwe inbedding als dit resulteert in betere prestaties op uw probleem.
Tutorials voor Woordinbedding
deze sectie geeft een aantal stapsgewijze tutorials weer die u kunt volgen om woordinbedding te gebruiken en woordinbedding naar uw project te brengen.
- Hoe Word-Inbeddingen te ontwikkelen in Python met Gensim
- Hoe Word-Inbeddinglagen te gebruiken voor Deep Learning Met Keras
- hoe een Deep CNN te ontwikkelen voor sentimentanalyse (Tekstclassificatie)
verder lezen
deze sectie biedt meer informatie over het onderwerp als u dieper op zoek bent.
artikelen
- Woordinbedding op Wikipedia
- Word2vec op Wikipedia
- handschoen op Wikipedia
- een overzicht van woordinbeddingen en hun verbinding met distributionele semantische modellen, 2016.
- Deep Learning, NLP, and Representations, 2014.
papier
- Verdelingsstructuur, 1956.
- A Neural Probabilistic Language Model, 2003.
- a Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning, 2008.
- Continuous space language models, 2007.
- Efficient Estimation of Word Representations in Vector Space, 2013
- Distributed Representations of Words and frases and their Compositionality, 2013.
- GloVe: Global Vectors for Word Representation, 2014.
Projects
- word2vec on Google Code
- GloVe: Global Vectors for Word Representation
Books
- Neural Network Methods in Natural Language Processing, 2017.
samenvatting
in dit bericht ontdekte u Woordinbeddingen als representatiemethode voor tekst in deep learning-toepassingen.
specifiek heb je geleerd:
- wat het woord inbedden benadering voor representatie tekst is en hoe het verschilt van andere functie extractie methoden.
- dat er 3 hoofdalgoritmen zijn om een woord te leren inbedden uit tekstgegevens.
- dat u een nieuwe inbedding kunt trainen of een voorgetrainde inbedding kunt gebruiken voor uw taak voor het verwerken van natuurlijke taal.
heeft u vragen?
Stel uw vragen in de opmerkingen hieronder en Ik zal mijn best doen om te beantwoorden.
ontwikkel Deep Learning modellen voor tekst Data vandaag!

Ontwikkel uw eigen Tekstmodellen in minuten
…met slechts een paar regels python code
ontdek hoe in mijn nieuwe Ebook:
Deep Learning for Natural Language Processing
het biedt zelfstudie tutorials over onderwerpen als:
Bag-of-Words, woord inbedding, taalmodellen, bijschrift generatie, tekst vertaling en nog veel meer…
ten slotte Deep Learning brengen in uw natuurlijke Taalverwerkingsprojecten
sla de academici over. Alleen Resultaten.
zie wat erin zit