delikatne Wprowadzenie do Auto-enkodera i niektórych jego typowych przypadków użycia z kodem Pythona
Tło:
Autoencoder to nienadzorowana sztuczna sieć neuronowa, która uczy się, jak efektywnie kompresować i kodować dane, a następnie uczy się rekonstruować dane z zredukowanej zakodowanej reprezentacji do reprezentacji, która jest jak najbardziej zbliżona do oryginalnego wejścia.
Autoencoder z założenia redukuje wymiary danych, ucząc się ignorowania szumów w danych.
oto przykład obrazu wejścia/wyjścia ze zbioru danych MNIST do autoencodera.
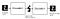
Komponenty Autoencodera:
Autoencodery składają się z 4 głównych części:
1 – enkoder: w którym model uczy się jak zmniejszyć wymiary wejściowe i skompresować dane wejściowe do zakodowanej reprezentacji.
2-wąskie gardło: która jest warstwą, która zawiera skompresowaną reprezentację danych wejściowych. Jest to najniższy możliwy wymiar danych wejściowych.
3 – Dekoder: w którym model uczy się rekonstruować dane z zakodowanej reprezentacji tak, aby były jak najbardziej zbliżone do oryginalnego wejścia.
4-utrata rekonstrukcji: jest to metoda, która mierzy, jak dobrze działa dekoder i jak blisko wyjścia jest do oryginalnego wejścia.
szkolenie polega następnie na wykorzystaniu propagacji pleców w celu zminimalizowania strat w odbudowie sieci.
pewnie zastanawiasz się, dlaczego miałbym trenować sieć neuronową tylko po to, aby wyprowadzić obraz lub dane, które są dokładnie takie same jak dane wejściowe! W tym artykule omówimy najczęstsze przypadki użycia Autoencodera. Zacznijmy:
Architektura Autoencodera:
architektura sieci dla autoencoderów może się różnić w zależności od przypadku użycia w przypadku prostej sieci FeedForward, sieci LSTM lub Konwolucyjnej sieci neuronowej. Niektóre z tych architektur będziemy badać w kolejnych kilku wierszach.
istnieje wiele sposobów i technik wykrywania anomalii i wartości odstających. Omówiłem ten temat w innym poście poniżej:
jednak jeśli masz skorelowane dane wejściowe, metoda autoencoder będzie działać bardzo dobrze, ponieważ operacja kodowania opiera się na skorelowanych funkcjach kompresji danych.
powiedzmy, że wytrenowaliśmy autoencoder na zestawie danych MNIST. Korzystając z prostej sieci neuronowej FeedForward, możemy to osiągnąć, budując prostą 6-warstwową sieć, jak poniżej:
wynik powyższego kodu jest:
jak widać na wyjściu, ostatnia utrata/błąd rekonstrukcji dla zestawu walidacji wynosi 0.0193, co jest świetne. Teraz, jeśli przekażę dowolny normalny obraz z zestawu danych MNIST, utrata rekonstrukcji będzie bardzo niska (< 0.02), ale jeśli spróbuję przekazać inny obraz (odstający lub anomalia), otrzymamy wysoką wartość utraty rekonstrukcji, ponieważ sieć nie zrekonstruowała obrazu/wejścia, który jest uważany za anomalię.
Uwaga w powyższym kodzie możesz użyć tylko części kodera do kompresji niektórych danych lub obrazów, a także możesz użyć tylko części dekodera do dekompresji danych poprzez załadowanie warstw dekodera.
teraz zróbmy wykrywanie anomalii. Poniższy kod wykorzystuje dwa różne obrazy, aby przewidzieć wynik anomalii (błąd rekonstrukcji) za pomocą sieci autoencoder, którą wytrenowaliśmy powyżej. pierwszy obraz pochodzi z MNiSW i daje wynik 5,43209. Oznacza to, że obraz nie jest anomalią. Drugi obraz, którego użyłem, jest całkowicie losowym obrazem, który nie należy do zestawu danych treningowych, a wyniki To: 6789.4907. Ten wysoki błąd oznacza, że obraz jest anomalią. Ta sama koncepcja dotyczy każdego typu zbioru danych.