jako analityk danych w branży konsumenckiej zazwyczaj uważam, że algorytmy boostingu wystarczają przynajmniej do większości zadań predykcyjnych. Są potężne, elastyczne i można je ładnie interpretować za pomocą niektórych sztuczek. Dlatego myślę, że konieczne jest przeczytanie niektórych materiałów i napisanie czegoś o algorytmach wzmacniających.
większość treści w tym artykule jest oparta na artykule: Tree Boosting With XGBoost: Why Does XGBoost Win „Every” machine Learning Competition?. Jest to naprawdę pouczający dokument. Prawie wszystko, co dotyczy algorytmów wzmacniających, zostało bardzo jasno wyjaśnione w artykule. Tak więc artykuł zawiera 110 stron: (
dla mnie w zasadzie skupię się na trzech najpopularniejszych algorytmach wspomagających: AdaBoost, GBM i XGBoost. Podzieliłem treść na dwie części. Pierwszy artykuł (ten) skupi się na algorytmie AdaBoost, a drugi zwróci się do porównania między GBM i XGBoost.
AdaBoost, skrót od „Adaptive Boosting”, jest pierwszym praktycznym algorytmem wspomagającym zaproponowanym przez Freunda i Schapire ’ a w 1996 roku. Koncentruje się na problemach klasyfikacyjnych i ma na celu przekształcenie zestawu słabych klasyfikatorów w silny. Końcowe równanie klasyfikacji można przedstawić jako
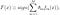
gdzie f_m oznacza klasyfikator słaby m_th, a theta_m jest odpowiednią wagą. Jest to dokładnie ważona kombinacja słabych klasyfikatorów M. Całą procedurę algorytmu AdaBoost można podsumować następująco.
algorytm Adaboosta
dany zbiór danych zawierający n punktów, gdzie

tutaj -1 oznacza klasę ujemną, podczas gdy 1 oznacza klasę dodatnią.
Inicjalizuj wagę dla każdego punktu danych jako:

dla iteracji m=1,…, M:
(1) Dopasuj słabe klasyfikatory do zestawu danych i wybierz ten z NAJNIŻSZYM ważonym błędem klasyfikacji:

(2) Oblicz wagę dla słabego klasyfikatora m_th:

dla każdego klasyfikatora z dokładnością wyższą niż 50%, waga jest dodatnia. Im dokładniejszy klasyfikator, tym większa waga. Podczas gdy dla klasyfikatora z dokładnością mniejszą niż 50%, waga jest ujemna. Oznacza to, że łączymy jego przewidywania przez odwrócenie znaku. Na przykład, możemy zmienić klasyfikator z dokładnością 40% W dokładność 60%, odwracając znak prognozy. Tak więc nawet klasyfikator wykonuje gorzej niż przypadkowe zgadywanie, nadal przyczynia się do ostatecznego przewidywania. Nie chcemy tylko żadnego klasyfikatora z dokładną dokładnością 50%, który nie dodaje żadnych informacji, a tym samym nie przyczynia się do ostatecznego przewidywania.
(3) zaktualizuj wagę dla każdego punktu danych jako:

gdzie Z_m jest współczynnikiem normalizacji zapewniającym, że suma wszystkich wag instancji jest równa 1.
jeśli błędnie zaklasyfikowany przypadek pochodzi od klasyfikatora ważonego dodatnio, termin ” exp ” w liczniku byłby zawsze większy niż 1 (y*f jest zawsze -1, theta_m jest dodatni). W ten sposób błędnie sklasyfikowane przypadki będą aktualizowane z większą wagą po iteracji. Ta sama logika dotyczy ujemnych klasyfikatorów ważonych. Jedyną różnicą jest to, że oryginalne poprawne klasyfikacje staną się błędnymi klasyfikacjami po odwróceniu znaku.
po iteracji M możemy uzyskać ostateczną prognozę, sumując ważoną prognozę każdego klasyfikatora.
AdaBoost as a Forward Stagewise Additive Model
ta część jest oparta na artykule: Additive logistic regression: a statistical view of boosting. Aby uzyskać bardziej szczegółowe informacje, zapoznaj się z oryginalnym dokumentem.
in 2000, Friedman et al. opracowano statystyczny widok algorytmu AdaBoost. Zinterpretowali AdaBoost jako procedury estymacji stagewise w celu dopasowania addytywnego modelu regresji logistycznej. Pokazali, że AdaBoost faktycznie minimalizuje funkcję strat wykładniczych

jest zminimalizowany w

ponieważ dla AdaBoost, y może być tylko -1 lub 1, funkcja utraty może być przepisana jako

kontynuuj rozwiązywanie dla F (x), otrzymujemy

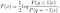
możemy dalej czerpać normalny model logistyczny z optymalnego rozwiązania F (x):

jest prawie identyczny z modelem regresji logistycznej pomimo czynnika 2.
Załóżmy, że mamy aktualne oszacowanie F (x) i staramy się szukać ulepszonego oszacowania F(x)+cf(x). Dla stałych C i x możemy rozszerzyć L(y, F(x)+cf (x)) do drugiego rzędu o f (x)=0,

Tak więc,

gdzie E_w(./ x) wskazuje ważone oczekiwanie warunkowe, a waga dla każdego punktu danych jest obliczana jako

Jeśli c > 0, minimalizacja ważonego oczekiwania warunkowego jest równa maksymalizacji

ponieważ y może być tylko 1 lub -1, oczekiwanie ważone można przepisać jako

optymalne rozwiązanie przychodzi jako

po określeniu F(x), masę C można obliczyć poprzez bezpośrednie zminimalizowanie L(y, F(x)+cf (x)):

rozwiązując dla c, otrzymujemy


niech epsilon jest równy ważonej sumie błędnie sklasyfikowanych przypadków, wtedy

zauważ, że c może być ujemne, jeśli słaby uczeń robi gorsze niż przypadkowe zgadywanie (50%), w w tym przypadku automatycznie odwraca polaryzację.
jeśli chodzi o wagi instancji, po ulepszonym dodaniu waga dla pojedynczej instancji staje się,

Tak więc waga instancji jest aktualizowana jako

w porównaniu z tymi używanymi w algorytmie AdaBoost,

widzimy, że są w identycznej formie. Dlatego rozsądne jest zinterpretowanie AdaBoost jako modelu addytywnego typu forward stagewise z funkcją straty wykładniczej, która iteracyjnie pasuje do słabego klasyfikatora, aby poprawić bieżące oszacowanie przy każdej iteracji m:
