Ostatnia aktualizacja 2019-08-20
osadzanie słów to rodzaj reprezentacji słów, która pozwala na podobną reprezentację słów o podobnym znaczeniu.
są rozproszoną reprezentacją tekstu, która jest być może jednym z kluczowych przełomów dla imponującej wydajności metod głębokiego uczenia w trudnych problemach przetwarzania języka naturalnego.
w tym poście odkryjesz metodę osadzania słowa do reprezentowania danych tekstowych.
po zakończeniu tego postu dowiesz się:
- czym jest metoda osadzania tekstu w słowie i czym różni się od innych metod wyodrębniania funkcji.
- że istnieją 3 główne algorytmy uczenia się osadzania słowa z danych tekstowych.
- że możesz trenować nowe osadzanie lub użyć wstępnie przeszkolonego osadzania w zadaniu przetwarzania języka naturalnego.
Rozpocznij swój projekt dzięki mojej nowej książce Deep Learning for Natural Language Processing, w tym samouczkom krok po kroku i plikom kodu źródłowego Pythona dla wszystkich przykładów.
zaczynajmy.

czym są osadzenia słów dla tekstu?
fot. Heather, niektóre prawa zastrzeżone.
- przegląd
- potrzebujesz pomocy w uczeniu głębokim danych tekstowych?
- czym są osadzanie słów?
- algorytmy osadzania słów
- warstwa osadzania
- Word2Vec
- GloVe
- Korzystanie z osadzeń programu Word
- dowiedz się osadzania
- ponowne wykorzystanie osadzenia
- Której Opcji Powinieneś Użyć?
- samouczki do osadzania programu Word
- Czytaj dalej
- Artykuły
- dokumenty
- projekty
- Książki
- podsumowanie
- opracuj modele głębokiego uczenia dla danych tekstowych już dziś!
- Twórz własne modele tekstowe w ciągu kilku minut
- wreszcie wprowadź głębokie uczenie do swoich projektów przetwarzania języka naturalnego
przegląd
ten post jest podzielony na 3 części; są to:
- czym są osadzanie słów?
- algorytmy osadzania słów
- używanie osadzania słów
potrzebujesz pomocy w uczeniu głębokim danych tekstowych?
weź mój darmowy 7-dniowy crash course e-mail teraz (z kodem).
Kliknij, aby się zapisać, a także otrzymać bezpłatną wersję kursu w formacie PDF.
rozpocznij bezpłatny kurs Crash
czym są osadzanie słów?
osadzanie słów to wyuczona reprezentacja tekstu, w której słowa o tym samym znaczeniu mają podobną reprezentację.
to właśnie takie podejście do reprezentowania słów i dokumentów można uznać za jeden z kluczowych przełomów głębokiego uczenia się w trudnych problemach przetwarzania języka naturalnego.
jedną z zalet stosowania gęstych i niskowymiarowych wektorów jest obliczanie: większość zestawów narzędzi sieci neuronowych nie gra dobrze z bardzo wysokowymiarowymi, rzadkimi wektorami. … Główną zaletą gęstych reprezentacji jest siła uogólniania: jeśli uważamy, że niektóre cechy mogą dostarczać podobnych wskazówek, warto zapewnić reprezentację, która jest w stanie uchwycić te podobieństwa.
— strona 92, Neural Network Methods in Natural Language Processing, 2017.
osadzanie słów jest w rzeczywistości klasą technik, w których poszczególne słowa są reprezentowane jako wektory rzeczywiste w predefiniowanej przestrzeni wektorowej. Każde słowo jest mapowane do jednego wektora, a wartości wektorowe są poznawane w sposób przypominający sieć neuronową, dlatego technika ta jest często wtapiana w pole głębokiego uczenia.
kluczem do tego podejścia jest idea użycia gęstej rozproszonej reprezentacji dla każdego słowa.
każde słowo jest reprezentowane przez wektor rzeczywisty, często dziesiątki lub setki wymiarów. Jest to kontrastowane z tysiącami lub milionami wymiarów wymaganych dla nielicznych reprezentacji wyrazów, takich jak kodowanie one-hot.
kojarzenie z każdym słowem w słownictwie wektor funkcji rozproszonych wyrazów … wektor funkcji reprezentuje różne aspekty słowa: Każde słowo jest związane z punktem w przestrzeni wektorowej. Liczba funkcji … jest znacznie mniejsza niż wielkość słownictwa
— a Neural Probabilistic Language Model, 2003.
rozproszona reprezentacja jest uczona na podstawie użycia słów. Dzięki temu słowa, które są używane w podobny sposób, mogą mieć podobne reprezentacje, naturalnie uchwycając ich znaczenie. Można to skontrastować z wyraźną, ale delikatną reprezentacją w modelu worka słów, w którym, o ile nie jest wyraźnie zarządzane, różne słowa mają różne reprezentacje, niezależnie od tego, jak są używane.
za tym podejściem kryje się głębsza teoria językowa, a mianowicie „hipoteza dystrybucyjna” Zelliga Harrisa, którą można podsumować jako: słowa, które mają podobny kontekst, będą miały podobne znaczenia. Więcej szczegółów można znaleźć w pracy Harrisa z 1956 r. „Distributional structure”.
to pojęcie pozwalania, aby użycie słowa określało jego znaczenie może być podsumowane przez często powtarzany żart Johna Firtha:
poznasz słowo po firmie, którą trzyma!
— Strona 11, „a synopsis of linguistic theory 1930-1955”, in Studies in Linguistic Analysis 1930-1955, 1962.
algorytmy osadzania słów
metody osadzania słów ucz się reprezentacji wektorowej o rzeczywistej wartości dla predefiniowanego słownictwa o stałej wielkości z korpusu tekstu.
proces uczenia się jest połączony z modelem sieci neuronowej w niektórych zadaniach, takich jak klasyfikacja dokumentów, lub jest procesem nienadzorowanym, wykorzystującym statystyki dokumentów.
w tej sekcji omówiono trzy techniki, których można użyć do nauki osadzania słów z danych tekstowych.
warstwa osadzania
warstwa osadzania, z braku lepszej nazwy, jest osadzaniem słowa, które jest poznawane wspólnie z modelem sieci neuronowej w konkretnym zadaniu przetwarzania języka naturalnego, takim jak modelowanie języka lub klasyfikacja dokumentów.
wymaga, aby tekst dokumentu był czyszczony i przygotowany w taki sposób, aby każde słowo było zakodowane jedno-gorące. Rozmiar przestrzeni wektorowej jest określony jako część modelu, np. 50, 100 lub 300 wymiarów. Wektory inicjowane są małymi liczbami losowymi. Warstwa osadzania jest używana na przednim końcu sieci neuronowej i jest dopasowana w nadzorowany sposób za pomocą algorytmu Backpropagacji.
… gdy wejście do sieci neuronowej zawiera symboliczne cechy kategoryczne (np. cechy, które biorą jeden z K różnych symboli, takich jak słowa z zamkniętego słownictwa), to jest wspólne kojarzenie każdej możliwej wartości funkcji (tj. każde słowo w słownictwie) z D-wymiarowym wektorem dla niektórych d. TE wektory są następnie uważane za parametry modelu i są szkolone wspólnie z innymi parametrami.
— strona 49, Neural Network Methods in Natural Language Processing, 2017.
jedno-gorące zakodowane słowa są odwzorowywane na wektory słowa. Jeśli używany jest wielowarstwowy Model perceptronu, to słowo wektory jest łączone przed przekazaniem jako wejście do modelu. Jeśli używana jest powtarzająca się sieć neuronowa, każde słowo może być traktowane jako jedno wejście w sekwencji.
takie podejście do uczenia się warstwy osadzania wymaga dużej ilości danych treningowych i może być powolne, ale nauczy się osadzania zarówno ukierunkowanego na konkretne dane tekstowe, jak i zadanie NLP.
Word2Vec
Word2Vec to statystyczna metoda efektywnej nauki samodzielnego osadzania słów z korpusu tekstowego.
został opracowany przez Tomasa Mikolova i wsp. w Google w 2013 r.jako odpowiedź na usprawnienie szkolenia osadzania opartego na sieciach neuronowych i od tego czasu stał się de facto standardem opracowywania wstępnie wyszkolonego osadzania słów.
dodatkowo prace obejmowały analizę poznanych wektorów i eksplorację matematyki wektorowej na reprezentacjach słów. Przykładowo, to odjęcie ” męskości „od” króla „i dodanie” kobiecości „daje w rezultacie słowo” Królowa”, utrwalając analogię”król jest królową tak jak mężczyzna jest kobietą”.
stwierdzamy, że te reprezentacje są zaskakująco dobre w przechwytywaniu składniowych i semantycznych regularności w języku, a każda relacja charakteryzuje się specyficznym dla relacji przesunięciem wektorowym. Pozwala to na wektorowe rozumowanie oparte na przesunięciach między wyrazami. Na przykład relacja mężczyzna / kobieta jest automatycznie poznawana, a z indukowanymi reprezentacjami wektorowymi „Król-mężczyzna + kobieta „daje wektor bardzo zbliżony do” Królowej.”
— prawidłowości językowe w ciągłych reprezentacjach słowa przestrzeni, 2013.
wprowadzono dwa różne modele uczenia się, które można wykorzystać jako część podejścia word2vec do nauki osadzania słów; są to:
- ciągły worek słów, czyli model CBOW.
- Model Ciągłego Pomijania Gramów.
model CBOW uczy się osadzania, przewidując bieżące słowo na podstawie jego kontekstu. Model continuous skip-gram uczy się poprzez przewidywanie otaczających słów danego słowa bieżącego.
model continuous skip-gram uczy się, przewidując otaczające słowa, które są podane w bieżącym słowie.
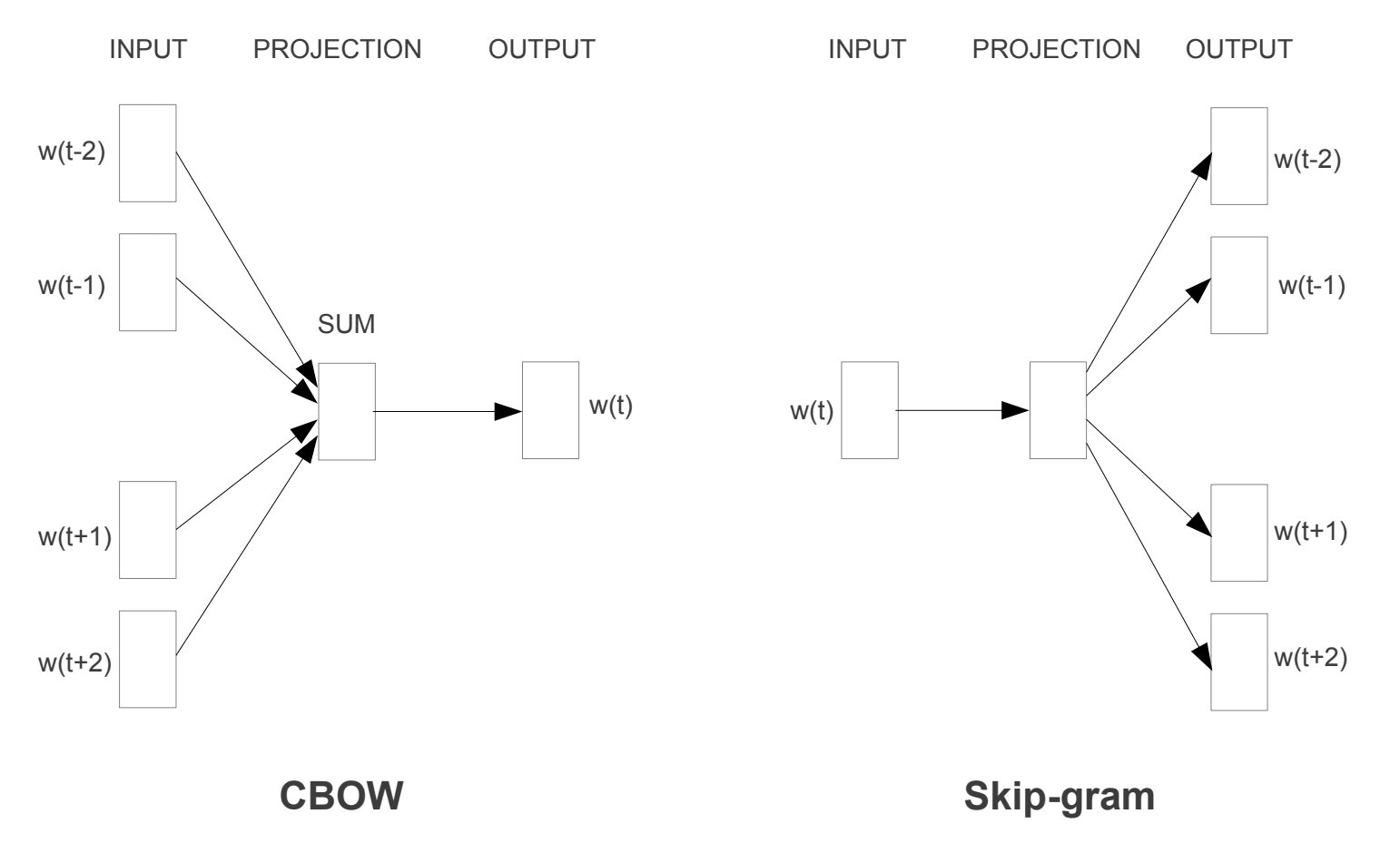
modele szkoleniowe Word2vec
zaczerpnięte z „wydajne Szacowanie reprezentacji słów w przestrzeni wektorowej”, 2013
oba modele koncentrują się na poznawaniu słów, biorąc pod uwagę ich lokalny kontekst użycia, gdzie kontekst jest definiowany przez okno sąsiednich słów. To okno jest konfigurowalnym parametrem modelu.
rozmiar przesuwanego okna ma silny wpływ na powstałe podobieństwa wektorowe. Duże okna mają tendencję do tworzenia bardziej aktualnych podobieństw, podczas gdy mniejsze okna mają tendencję do tworzenia bardziej funkcjonalnych i składniowych podobieństw.
— strona 128, Neural Network Methods in Natural Language Processing, 2017.
kluczową zaletą tego podejścia jest to, że wysokiej jakości osadzenia słów można efektywnie nauczyć się (niska złożoność czasowa i przestrzenna), umożliwiając naukę większych osadzeń (więcej wymiarów) ze znacznie większych korpusów tekstu (miliardy słów).
GloVe
algorytm Global vectors for Word Representation, lub GloVe, jest rozszerzeniem metody word2vec do efektywnego uczenia się wektorów słów, opracowanej przez Penningtona i wsp. w Stanford.
Klasyczne reprezentacje słów w modelu przestrzeni wektorowej zostały opracowane przy użyciu technik faktoryzacji macierzy, takich jak Latent Semantic Analysis (LSA), które dobrze wykorzystują globalne statystyki tekstu, ale nie są tak dobre jak wyuczone metody, takie jak word2vec, w wychwytywaniu znaczenia i demonstrowaniu go w zadaniach takich jak obliczanie analogii (np. Król i Królowa przykład powyżej).
rękawica jest podejściem łączącym zarówno globalne statystyki technik faktoryzacji macierzy, takich jak LSA, z lokalną nauką kontekstową w word2vec.
zamiast używać okna do definiowania lokalnego kontekstu, GloVe konstruuje jawną macierz współwystępowania słowa lub słowa, wykorzystując statystyki całego korpusu tekstu. Rezultatem jest model uczenia się, który może skutkować ogólnie lepszymi osadzeniami słów.
GloVe, to nowy globalny model regresji log-bilinear do nienadzorowanego uczenia się reprezentacji słów, który przewyższa inne modele w zakresie analogii słów, podobieństwa słów i zadań rozpoznawania nazwanych jednostek.
— Global Vectors for Word Representation, 2014.
Korzystanie z osadzeń programu Word
masz kilka opcji, jeśli chodzi o korzystanie z osadzeń programu word w projekcie przetwarzania języka naturalnego.
Ta sekcja przedstawia te opcje.
dowiedz się osadzania
możesz nauczyć się osadzania słowa dla swojego problemu.
wymaga to dużej ilości danych tekstowych, aby zapewnić nauczenie się przydatnych osadzeń, takich jak miliony lub miliardy słów.
masz dwie główne opcje podczas szkolenia osadzania słowa:
- dowiedz się go samodzielnie, gdzie model jest szkolony, aby nauczyć się osadzania, który jest zapisywany i używany jako część innego modelu do twojego zadania później. Jest to dobre podejście, jeśli chcesz użyć tego samego osadzania w wielu modelach.
- Ucz się wspólnie, gdzie Osadzanie jest uczone w ramach dużego modelu specyficznego dla zadań. Jest to dobre podejście, jeśli zamierzasz używać osadzania tylko w jednym zadaniu.
ponowne wykorzystanie osadzenia
często badacze udostępniają wstępnie przeszkolone osadzenia słów za darmo, często na licencji zezwalającej, dzięki czemu można ich używać we własnych projektach akademickich lub komercyjnych.
na przykład zarówno word2vec, jak i osadzenie słowa GloVe są dostępne do pobrania za darmo.
można ich używać w projekcie zamiast trenować własne osadzenia od podstaw.
masz dwie główne opcje, jeśli chodzi o korzystanie z wstępnie przeszkolonych osadzeń:
- Static, gdzie Osadzanie jest statyczne i jest używane jako element Twojego modelu. Jest to odpowiednie podejście, jeśli osadzenie jest dobre dla problemu i daje dobre wyniki.
- Zaktualizowano, gdzie wstępnie przeszkolone Osadzanie jest używane do zalążkowania modelu, ale Osadzanie jest aktualizowane wspólnie podczas szkolenia modelu. Może to być dobra opcja, jeśli chcesz w pełni wykorzystać model i osadzenie w swoim zadaniu.
Której Opcji Powinieneś Użyć?
Poznaj różne opcje i jeśli to możliwe, przetestuj, aby zobaczyć, co daje najlepsze wyniki w Twoim problemie.
być może zacznij od szybkich metod, takich jak użycie wstępnie przeszkolonego osadzania, i używaj nowego osadzania tylko wtedy, gdy spowoduje to lepszą wydajność problemu.
samouczki do osadzania programu Word
Ta sekcja zawiera kilka samouczków krok po kroku, które można śledzić za pomocą osadzania programu word i wprowadzić osadzanie programu word do projektu.
- jak rozwijać osadzanie słów w Pythonie za pomocą Gensim
- jak używać warstw osadzania słów do głębokiego uczenia się za pomocą Keras
- jak opracować głęboką CNN do analizy tonacji (Klasyfikacja tekstu)
Czytaj dalej
Ta sekcja zawiera więcej zasobów na ten temat, jeśli szukasz głębiej.
Artykuły
- osadzanie słów na Wikipedii
- word2vec na Wikipedii
- rękawica na Wikipedii
- przegląd osadzania słów i ich połączenia z dystrybucyjnymi modelami semantycznymi, 2016.
- Deep Learning, NLP, and Representations, 2014.
dokumenty
- struktura dystrybucyjna, 1956.
- A Neural Probabilistic Language Model, 2003.
- a Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning, 2008.
- Continuous space language models, 2007.
- efektywne Szacowanie reprezentacji słów w przestrzeni wektorowej, 2013
- rozproszone reprezentacje słów i fraz oraz ich Składowość, 2013.
- GloVe: Global Vectors for Word Representation, 2014.
projekty
- word2vec w kodzie Google
- Rękawica: Globalne Wektory reprezentacji słowa
Książki
- metody sieci neuronowych w przetwarzaniu języka naturalnego, 2017.
podsumowanie
w tym poście odkryłeś osadzanie słów jako metodę reprezentacji tekstu w aplikacjach do głębokiego uczenia.
konkretnie, nauczyłeś się:
- czym jest podejście do osadzania tekstu w tekście reprezentacji i czym różni się od innych metod ekstrakcji funkcji.
- że istnieją 3 główne algorytmy uczenia się osadzania słowa z danych tekstowych.
- że możesz trenować nowe osadzanie lub użyć wstępnie przeszkolonego osadzania w zadaniu przetwarzania języka naturalnego.
masz pytania?
Zadawaj pytania w komentarzach poniżej, a ja postaram się odpowiedzieć.
opracuj modele głębokiego uczenia dla danych tekstowych już dziś!

Twórz własne modele tekstowe w ciągu kilku minut
…dzięki zaledwie kilku liniom kodu Pythona
Odkryj, jak w moim nowym ebooku:
Deep Learning for Natural Language Processing
zapewnia samouczki do samodzielnej nauki na takie tematy, jak:
work-of-Words, osadzanie słów, modele językowe, generowanie podpisów, tłumaczenie tekstu i wiele więcej…
wreszcie wprowadź głębokie uczenie do swoich projektów przetwarzania języka naturalnego
Pomiń naukowców. Tylko Wyniki.
Zobacz co jest w środku