istnieje również wiele niewłaściwych sposobów uwzględniania zmiennych. Model grawitacji nie będzie działał, chyba że każda zmienna spełnia następujące kryteria:
- numeryczny
- kompletny
- niezawodny
tylko dane numeryczne
ponieważ model grawitacji jest równaniem matematycznym, wszystkie zmienne wejściowe muszą być numeryczne. Może to być Liczba (populacja), miara przestrzenna (powierzchnia, odległość itp.), Czas (godziny z Londynu na piechotę), procent (wzrost/spadek płac), wartość waluty (płace w szylingach) lub inna miara miejsc zaangażowanych w model.
liczby muszą być znaczące i nie mogą być nominalnymi zmiennymi kategorycznymi, które działają jako stand-in dla atrybutu jakościowego. Na przykład nie można dowolnie przypisać numeru i użyć go w modelu, jeśli numer nie ma znaczenia (np. road quality = dobry, lub road quality = 4). Chociaż ten ostatni jest liczbowy, nie jest miarą jakości dróg. Zamiast tego możesz użyć średniej prędkości podróży w milach na godzinę jako wskaźnika jakości drogi. To, czy średnia prędkość jest miarą jakości drogi, zależy od ciebie, aby określić i bronić jako autora badania.
Ogólnie rzecz biorąc, jeśli możesz to zmierzyć lub policzyć, możesz to modelować.
tylko Pełne Dane
Wszystkie kategorie danych muszą istnieć dla każdego punktu zainteresowania. Oznacza to, że wszystkie z 32 analizowanych hrabstw muszą mieć wiarygodne dane dla każdego współczynnika push and pull. Nie możesz mieć żadnych luk lub luk, takich jak jeden powiat, w którym nie masz średniej płacy.
tylko wiarygodne dane
powiedzenie informatyczne „śmieć w, śmieć Na Zewnątrz” odnosi się również do modeli grawitacyjnych, które są tak wiarygodne, jak dane użyte do ich budowy. Oprócz wyboru solidnych i wiarygodnych danych historycznych ze źródeł, którym możesz zaufać, istnieje wiele sposobów na popełnianie błędów, które sprawią, że wyniki twojego modelu będą pozbawione sensu. Na przykład warto upewnić się, że dane, które posiadasz, dokładnie pasują do terytoriów (np. dane hrabstwa reprezentują hrabstwa, a nie dane miasta reprezentują Hrabstwo).
w zależności od czasu i miejsca nauki, może być trudno uzyskać wiarygodny zestaw danych, na których można oprzeć swój model. Im dalej w przeszłości jeden badania, tym trudniejsze może być. Podobnie, może być łatwiej przeprowadzić tego typu analizy w społeczeństwach, które były mocno zbiurokratyzowane i pozostawiły po sobie dobry papierowy ślad, na przykład w Europie czy Ameryce Północnej.
aby zapewnić jakość danych w tym studium przypadku, każda zmienna została wiarygodnie obliczona lub zaczerpnięta z opublikowanych zweryfikowanych danych historycznych (patrz Tabela 1). Dokładnie, jak te dane zostały zebrane, można przeczytać w oryginalnym artykule, w którym zostało to dogłębnie wyjaśnione.11
nasze pięć zmiennych modelu
mając na uwadze powyższe zasady, mogliśmy wybrać dowolną liczbę zmiennych, biorąc pod uwagę to, co wiedzieliśmy o współczynnikach push i pull migracji. Zdecydowaliśmy się na pięć (5), wybranych na podstawie tego, co uważaliśmy za najważniejsze i co wiedzieliśmy, że może być poparte wiarygodnymi danymi.
| zmienna | źródło |
|---|---|
| population at origin | 1771 values, Wrigley, „English county populations”, PP. 54-5.12 |
| odległość od Londynu | obliczona za pomocą oprogramowania |
| cena pszenicy | „13 |
| przeciętne płace w kraju pochodzenia | , „industrializacja i nierówności Regionalne”, s. 11-12. 965-6.14 |
| trajektoria płac | Hunt, „industrializacja i nierówności Regionalne”, s. 10. 965-6.15 |
Tabela 1: Pięć zmiennych użytych w modelu i źródło każdej z nich w recenzowanej literaturze
po podjęciu decyzji w sprawie tych zmiennych, współautor oryginalnego badania, Adam Dennett, postanowił przepisać formułę, aby była ona samodzielna, tak aby łatwo było stwierdzić, które bity dotyczyły każdej z tych pięciu zmiennych. To dlatego powyższy wzór wygląda inaczej niż w oryginalnej pracy badawczej. Nowe symbole można zobaczyć w tabeli 2:
dwie dodatkowe zmienne $i$ I $j$ oznaczają odpowiednio „w punkcie pochodzenia” i „w Londynie”. $Wa_{i}$ oznacza „poziom płac w miejscu pochodzenia”, podczas gdy $Wa_{j}$ oznacza „poziom płac w Londynie”. Te siedem nowych symboli może zastąpić bardziej ogólne we wzorze:
\
jest to teraz bardziej gadatliwa i nieco samo-udokumentowana wersja poprzedniego równania. Obie rozwiązują matematycznie dokładnie w ten sam sposób, ponieważ zmiany są czysto powierzchowne i z korzyścią dla ludzkiego użytkownika.
kompletny zestaw danych zmiennych
aby ułatwić samouczek, dane dla każdej z 5 zmiennych i każdego z 32 hrabstw zostały już skompilowane i wyczyszczone i można je zobaczyć w tabeli 3 lub pobrać jako plik csv. Tabela ta zawiera również znaną liczbę Włóczęgów z tego powiatu, obserwowaną w podstawowym zapisie źródłowym:
| Hrabstwo | włóczęgi | $d$ km do Londynu | $P$ populacja (osoby) | $Wa$ średnia płaca (szylingi) | $WaT$ płaca trajektoria 1767-95 (%zmiana) | $Wh$ cena pszenicy (szylingi) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Kornwalia | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
ostateczna różnica między tą formułą a tą używaną w oryginalnym artykule polega na tym, że dwie zmienne mają silniejszy związek z włóczęgostwem, gdy są wykreślone naturalnie logarytmicznie. Są to populacja w miejscu pochodzenia ($P$) i odległość od miejsca pochodzenia do Londynu ($d$). Oznacza to, że dla danych w tym badaniu linia regresji (czasami nazywana linią najlepszego dopasowania) jest lepszym dopasowaniem, gdy dane zostały zarejestrowane niż wtedy, gdy nie było. Można to zobaczyć na rysunku 7, z niezalogowanymi liczbami populacji po lewej stronie, a zalogowaną wersją po prawej. Więcej punktów znajduje się bliżej linii najlepszego dopasowania na wykresie zalogowanym niż na wykresie niezalogowanym.
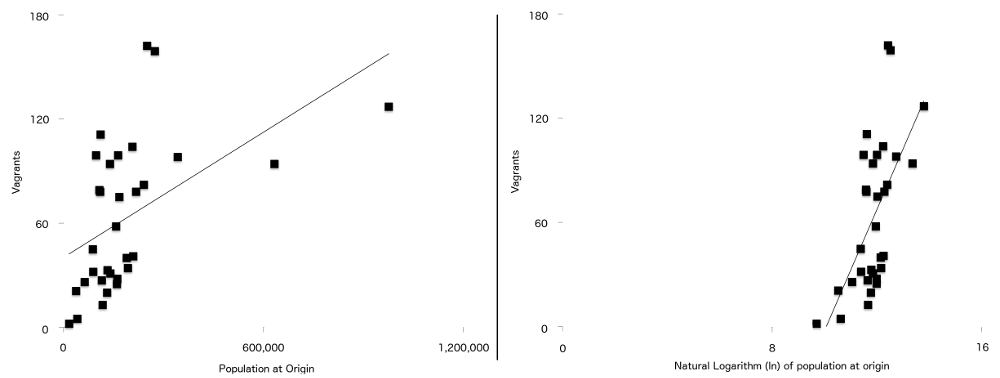
Rysunek 7: Liczba Włóczęgów wykreślona z populacją w miejscu pochodzenia (po lewej) i logiem naturalnym populacji pochodzenia (po prawej) z prostą linią regresji nałożoną na oba. Zwróć uwagę na silniejszą zależność między dwiema zmiennymi widocznymi na drugim wykresie.
ponieważ tak jest w przypadku tych konkretnych danych (twoje własne dane w podobnym badaniu mogą nie podążać za tym wzorem), wzór został dostosowany do korzystania z naturalnie rejestrowanych wersji tych dwóch zmiennych, w wyniku czego końcowy wzór użyty w modelu grawitacji (Rysunek 8). Nie mogliśmy wiedzieć o potrzebie tej korekty, dopóki nie zebraliśmy naszych zmiennych danych:
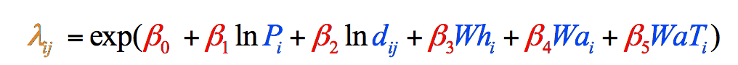
Rysunek 8: końcowy wzór modelu grawitacyjnego w podziale na stopnie i oznaczony kolorami. Elementy w czerni to operacje matematyczne. Elementy w Kolorze Niebieskim reprezentują nasze zmienne, które właśnie zebraliśmy (Krok 1). Elementy w kolorze czerwonym reprezentują wagi każdej zmiennej, którą musimy obliczyć (Krok 2), A Element w kolorze pomarańczowym jest ostatecznym oszacowaniem Włóczęgów z tego hrabstwa, które możemy obliczyć, gdy mamy inne informacje (Krok 3).
wartości w tabeli 3 dają nam wszystko, czego potrzebujemy, aby wypełnić niebieskie części każdego równania na rysunku 8. Możemy teraz zwrócić naszą uwagę na czerwone części, które mówią nam, jak ważna jest każda zmienna w modelu ogólnym, i dają nam liczby potrzebne do wypełnienia równania.
Krok 2: Określanie wag
wagi dla każdej zmiennej mówią nam, jak ważny jest ten współczynnik push/pull w stosunku do innych zmiennych podczas próby oszacowania liczby Włóczęgów, które powinny pochodzić z danego hrabstwa. Parametry $β$ muszą być określone w całym zbiorze danych ze znanych danych. Dzięki nim będziemy mogli porównać Indywidualne obserwacje specyficzne dla Pochodzenia z modelem ogólnym. Następnie możemy zbadać te i zidentyfikować ponad i pod przewidywanymi przepływami między różnymi początkami i miejscem przeznaczenia.
na tym etapie nie wiemy, jak ważna jest każda z nich. Może cena pszenicy jest lepszym wskaźnikiem migracji niż odległość? Nie dowiemy się, dopóki nie obliczymy wartości od $β1$ do $β5$ (wag), rozwiązując powyższe równanie. Punkt przecięcia osi y ($β0$) można obliczyć tylko wtedy, gdy poznamy wszystkie pozostałe ($β1-β5$). Są to czerwone wartości na rysunku 8 powyżej. Wagi można zobaczyć w tabeli 4 i w tabeli A1 oryginalnego papieru.16 teraz zademonstrujemy, w jaki sposób doszliśmy do tych wartości.
aby obliczyć te wartości long-hand wymaga niesamowitej pracy. Użyjemy szybkiego rozwiązania w języku programowania R, które wykorzystuje pakiet masy Williama Venablesa i Briana Ripleya, który może rozwiązać ujemne równania regresji dwumianowej, takie jak nasz model grawitacji za pomocą pojedynczej linii kodu. Jednak ważne jest, aby zrozumieć zasady, które stoją za tym, co się robi, aby docenić to, co robi kod (zwróć uwagę, że poniższe sekcje nie wykonują obliczeń, ale wyjaśniają jej kroki; zrobimy obliczenia z kodem dalej na stronie).
Obliczanie indywidualnych Wag (w zasadzie)
$β_{1}$, $ β_{2}$, itp., są takie same jak $β$ w powyższym prostym modelu regresji liniowej, który jest nachyleniem linii regresji (wzrost w ciągu lub o ile $y$ wzrasta, gdy $x$ wzrasta o 1). Jedyną różnicą między prostą regresją liniową a naszym modelem grawitacji jest to, że musimy obliczyć 5 zboczy zamiast 1.
prosta regresja liniowa\(y = α + ßx\)
musimy rozwiązać dla każdego z tych pięciu zboczy, zanim będziemy mogli obliczyć punkt przecięcia osi Y w następnym kroku. Dzieje się tak dlatego, że zbocza różnych wartości $β$ są częścią równania do obliczania przecięcia osi Y.
wzór na obliczenie $ β$ w analizie regresji to:
\
współczynnik korelacji Pearsona
współczynnik korelacji Pearsona można obliczyć długością, ale w tym przypadku jest to dość długie obliczenie, wymagające 64 liczb. Istnieje kilka świetnych samouczków wideo w języku angielskim dostępnych online, Jeśli chcesz zobaczyć, jak wykonać obliczenia na dłuższą rękę.17 Istnieje również wiele kalkulatorów online, które obliczą $r$ dla Ciebie, jeśli podasz dane. Biorąc pod uwagę dużą liczbę cyfr do obliczenia, polecam stronę internetową z wbudowanym narzędziem zaprojektowanym do tego obliczenia. Upewnij się, że wybierzesz renomowaną stronę, taką jak ta oferowana przez Uniwersytet.
Obliczanie $s_{y}$ & $s_{x}$ (odchylenie standardowe)
odchylenie standardowe jest sposobem wyrażenia, ile odchylenia od średniej (średniej) jest w danych. Innymi słowy, czy dane są dość skupione wokół średniej, czy też rozprzestrzenianie się jest znacznie szersze?
Ponownie, istnieją kalkulatory online i pakiety oprogramowania statystycznego, które mogą wykonać te obliczenia za Ciebie, jeśli podasz dane.
Obliczanie $β_{0}$ (punkt przecięcia osi y)
następnie musimy obliczyć punkt przecięcia osi Y. Wzór na obliczenie punktu przecięcia osi y w prostej regresji liniowej jest następujący:
\
jednak obliczenia stają się znacznie bardziej skomplikowane w analizie regresji wielokrotnej, ponieważ każda zmienna wpływa na obliczenia. To sprawia, że robienie tego ręcznie jest bardzo trudne i jest jednym z powodów, dla których wybieramy rozwiązanie programowe.
kod do obliczania wag
pakiet statystyczny masy, napisany dla języka programowania R, ma funkcję, która może rozwiązywać ujemne równania regresji dwumianowej, dzięki czemu bardzo łatwo jest obliczyć, co w przeciwnym razie byłoby bardzo trudnym wzorem długiej ręki.
Ta sekcja zakłada, że zainstalowałeś R i zainstalowałeś pakiet MASS. Jeśli tego nie zrobiłeś, będziesz musiał to zrobić przed kontynuowaniem. Taryn Dewar ’ s tutorial on R Basics with Tabular Data includes R installation instructions.
aby użyć tego kodu, musisz pobrać kopię zbioru danych pięciu zmiennych plus liczbę obserwowanych Włóczęgów z każdego z 32 hrabstw. Jest to dostępne powyżej jako Tabela 3, lub można pobrać jako .plik csv. Niezależnie od wybranego trybu, zapisz plik jako VagrantsExampleData.csv. Jeśli używasz komputera Mac, zapisz go jako format Windows .plik csv. Otwórz VagrantsExampleData.csv i zapoznać się z jego zawartością. Powinieneś zauważyć każdy z 32 powiatów, wraz z każdą ze zmiennych, które omówiliśmy w tym samouczku. Będziemy używać nagłówków kolumn, aby uzyskać dostęp do tych danych za pomocą naszego programu komputerowego. Mogłem nazwać je cokolwiek, ale w tym pliku są:
vagrantspopulationdistancewheatwageswageTrajectory
w tym samym katalogu, w którym zapisałeś plik csv, Utwórz i zapisz nowy plik skryptu R (możesz to zrobić za pomocą dowolnego edytora tekstu lub RStudio, ale nie używaj edytora tekstu, takiego jak MS Word). Zapisz to jako wag kalkulacje.r.
napiszemy teraz krótki program, który:
- instaluje pakiet MASS
- wywołuje pakiet MASS, dzięki czemu możemy go użyć w naszym kodzie
- przechowuje zawartość .plik csv do zmiennej, której możemy użyć programowo
- rozwiązuje równanie modelu grawitacji za pomocą zestawu danych
- wyprowadza wyniki obliczeń.
każde z tych zadań zostanie zrealizowane z kolei za pomocą jednej linii kodu
skopiuj powyższy kod do swoich obliczeń wagowych.r plik i zapisz. Możesz teraz uruchomić kod używając swojego ulubionego środowiska R (ja używam RStudio) i wyniki obliczeń powinny pojawić się w oknie konsoli (jak to wygląda będzie zależeć od Twojego środowiska). Może być konieczne ustawienie katalogu roboczego środowiska R na katalog zawierający Twoje .csv i .pliki R. Jeśli używasz RStudio możesz to zrobić za pomocą menu (sesja – > Ustaw katalog roboczy – > Wybierz katalog). Możesz również osiągnąć to samo za pomocą polecenia:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundzauważ, że linia 4 jest linią, która rozwiązuje równanie dla nas, używając glm.funkcja nb, która jest skrótem od „uogólnionego modelu liniowego-ujemnego dwumianu”. Ta linia wymaga wielu wejść:
- nasze zmienne za pomocą nagłówków kolumn, jak zapisano w.plik csv, wraz z wszelkimi logami, które należy do nich wykonać (
vagrants, log (population), log(distance),wheat,wages,wageTrajectory). Jeśli używasz modelu z własnymi danymi, dostosujesz je tak, aby odzwierciedlały nagłówki kolumn w zbiorze danych. - gdzie kod może znaleźć dane – w tym przypadku zmienna, którą zdefiniowaliśmy w linii 3 o nazwie
gravityModelData.
wyniki obliczeń można zobaczyć na rysunku 9:
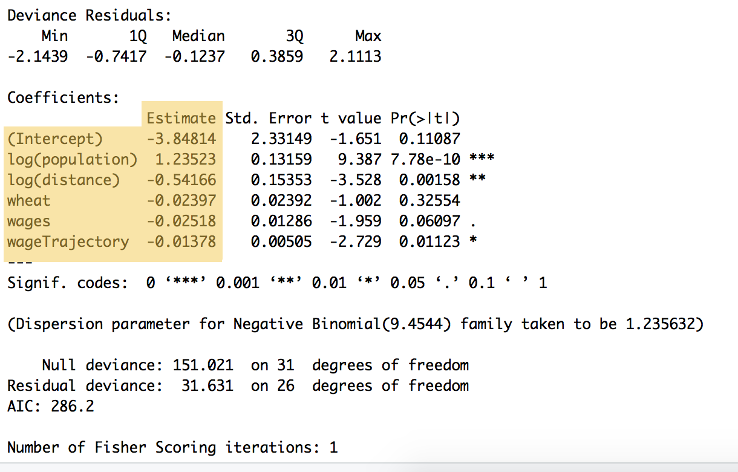
Rysunek 9: podsumowanie powyższego kodu, pokazujące wagi dla każdej zmiennej i punkt przecięcia osi y, wymienione w nagłówku ’ Estimate '($\beta_{0}$ do $\beta_{5}$. W podsumowaniu przedstawiono również szereg innych obliczeń, w tym istotność statystyczną.
Krok 3: Obliczając szacunki dla każdego Hrabstwa
musimy to zrobić raz dla każdego z 32 hrabstw.
można to zrobić za pomocą kalkulatora naukowego, tworząc formułę arkusza kalkulacyjnego lub pisząc program komputerowy. Aby to zrobić automatycznie w R, możesz dodać następujące elementy do kodu i ponownie uruchomić program. Ta pętla for oblicza oczekiwaną liczbę Włóczęgów z każdego z 32 powiatów w przykładzie i drukuje wyniki, które możesz zobaczyć:
aby zbudować zrozumienie, proponuję wykonać jedną długą rękę hrabstwa. W tym samouczku użyjemy Hertfordshire jako przykładu z długimi rękami (ale proces jest dokładnie taki sam dla pozostałych 31 hrabstw).
korzystając z danych dla Hertfordshire w tabeli 3 i wag dla każdej zmiennej w tabeli 4, możemy teraz wypełnić nasz wzór, który da wynik 95:
najpierw wymieńmy symbole na liczby, zaczerpnięte z tabel wymienionych powyżej.
następnie zacznij obliczać wartości, aby dostać się do oszacowania. Zapamiętanie matematycznego porządku operacji, pomnóż wartości przed dodaniem. Zacznij więc od obliczenia każdej zmiennej (możesz do tego użyć kalkulatora naukowego):
następnym krokiem jest dodanie liczb razem:
estimated vagrants = exp(4.56232408897)i wreszcie, aby obliczyć funkcję wykładniczą (użyj kalkulatora naukowego):
estimated vagrants = 95.8059926832wycofaliśmy resztę i zadeklarowaliśmy, że szacowana liczba Włóczęgów z Hertfordshire w tym modelu wynosi 95. Musisz przeprowadzić te same obliczenia dla każdego z pozostałych powiatów, które można przyspieszyć za pomocą programu arkusza kalkulacyjnego. Aby upewnić się, że możesz to zrobić ponownie, dodałem również liczby dla Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
polecam wybranie jednego innego hrabstwa i obliczenie go na długo przed przejściem dalej, aby upewnić się, że możesz wykonać obliczenia samodzielnie. Prawidłowa odpowiedź jest dostępna w tabeli 5, która porównuje zaobserwowane wartości (widoczne w podstawowym rekordzie źródłowym) z wartościami szacunkowymi (obliczonymi przez nasz model grawitacji). „Pozostałość” to różnica między tymi dwoma, z dużą różnicą sugerującą nieoczekiwaną liczbę Włóczęgów, które mogą być warte bliższego przyjrzenia się z czapką historyka.
| Powiat | Wartość Obserwowana | Wartość Szacunkowa | Wartość Rezydualna |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Kornwalia | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| 45 | 39 | 6 | |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| 58 | 29 | 29 | |
| Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| 104 | 70 | 34 | |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Krok 4-interpretacja historyczna
na tym etapie proces modelowania jest zakończony, a ostatnim etapem jest interpretacja historyczna.
oryginalny artykuł, na którym oparto to studium przypadku, poświęcony jest przede wszystkim interpretacji tego, co wyniki modelowania oznaczają dla naszego zrozumienia migracji klas niższych w XVIII wieku. Jak widać na mapie na rysunku 5, były części kraju, które model zdecydowanie sugerował, wysyłały do Londynu imigrantów niższej klasy lub wysyłały ich za mało.
współautorzy przedstawili swoje interpretacje, dlaczego te wzory mogły się pojawić. Interpretacje te różniły się w zależności od miejsca. W rejonach północnej Anglii, które szybko się uprzemysłowiły, takich jak Yorkshire czy Manchester, lokalne możliwości wydawały się dawać ludziom mniej powodów do wyjazdu, co skutkowało niższą niż oczekiwano migracją do Londynu. Na słabnących obszarach na zachodzie, takich jak Bristol, urok Londynu był silniejszy, ponieważ więcej osób wyjechało szukając pracy w stolicy.
nie wszystkie wzory oczekiwano. Northumberland na dalekim północnym wschodzie okazał się regionalną anomalią, wysyłając do Londynu znacznie więcej (kobiet) migrantów, niż byśmy się spodziewali. Bez wyników modelu, jest mało prawdopodobne, że pomyślelibyśmy o rozważeniu Northumberland w ogóle, szczególnie dlatego, że był tak daleko od metropolii i przypuszczaliśmy, że będzie miał słabe powiązania z Londynem. Model ten dostarczył nam nowych dowodów do rozważenia jako historycy i zmienił nasze rozumienie relacji Londyn-Northumberland. Pełne omówienie naszych ustaleń można przeczytać w oryginalnym artykule.18
biorąc swoją wiedzę do przodu
po wypróbowaniu tego przykładowego problemu, powinieneś mieć jasne zrozumienie, jak korzystać z tej przykładowej formuły, a także tego, czy model grawitacji może być odpowiednim rozwiązaniem dla Twojego problemu badawczego. Masz doświadczenie i słownictwo, aby podejść i omówić modele grawitacji z odpowiednio doświadczonym matematycznie współpracownikiem, który pomoże Ci dostosować je do własnego studium przypadku.
jeśli masz szczęście, że masz również dane o migrantach przeprowadzających się do późnego XVIII-wiecznego Londynu i chcesz je modelować za pomocą tych samych pięciu zmiennych wymienionych powyżej, ta formuła działa tak, jak jest – jest tu łatwe badanie dla kogoś z odpowiednimi danymi. Model ten sprawdza się jednak nie tylko w badaniach nad migrantami przeprowadzającymi się do Londynu. Zmienne mogą się zmieniać, a celem podróży nie musi być Londyn. Byłoby możliwe użycie modelu grawitacji do badania migracji do starożytnego Rzymu lub Bangkoku XXI wieku, jeśli masz Dane i Pytanie badawcze. Nie musi to być nawet model migracji. Aby skorzystać z studium przypadku kolumbijskiej kawy ze wstępu, które koncentruje się na handlu, a nie migracji, Tabela 6 pokazuje realne zastosowanie tej samej formuły, niezmienionej.
| kryteria | przykład eksportu kawy |
|---|---|
| jeden punkt pochodzenia | eksport kawy z portu w Barranquilla w Kolumbii |
| wiele skończonych miejsc docelowych | 21 krajów półkuli zachodniej w 1950 |
| pięć zmiennych wyjaśniających | (1) Liczba portów Oceanu Atlantyckiego w kraju przyjmującym (2) mile od Kolumbii, (3) Produkt krajowy brutto kraju przyjmującego, (4) Krajowa Kawa uprawiana w tonach, (5) kawiarnie na 10 000 osób |
jest długa historia modeli grawitacji w nauce. Aby skutecznie wykorzystać je do badań, musisz zrozumieć podstawową teorię i matematykę za nimi oraz powody, dla których tak się rozwinęły. Ważne jest również, aby zrozumieć ich granice i warunki prawidłowego korzystania z nich, z których niektóre zostały omówione powyżej. Może również pomóc wiedzieć:
-
model grawitacji, taki jak ten użyty w tym przykładzie, może działać tylko w układzie zamkniętym. Powyższy model miał tylko 32 możliwe punkty pochodzenia, dzięki czemu można go było uruchomić 32 razy. Nieznana lub nieskończenie duża liczba punktów początkowych (lub miejsc docelowych w zależności od modelu) wymagałaby innego równania.
-
koncepcja modelu grawitacji opiera się również na założeniu, że ruchy (migracja, handel itp.) opierają się na zbiorze dobrowolnych indywidualnych decyzji, na które mogą mieć wpływ czynniki zewnętrzne, ale nie są przez nie całkowicie kontrolowane. Na przykład, dobrowolne migracje lub zakupy dokonane z wolnej woli mogą być modelowane za pomocą tej techniki, ale przymusowa migracja, przymusowy zakup lub naturalne procesy, takie jak Migracja ptaków lub przepływ rzeki, mogą nie być zgodne z tymi samymi zasadami i dlatego może być potrzebny inny model.
-
modele grawitacyjne mogą być wykorzystywane do przewidywania zachowań populacji, ale nie osób, a zatem próby modelowania danych powinny obejmować dużą liczbę ruchów w celu zapewnienia istotności statystycznej.
jest wiele innych pułapek, ale także ogromne możliwości. Mam nadzieję, że ten przegląd modelu grawitacji i towarzyszące mu opublikowane badania uczynią to potężne narzędzie bardziej dostępnym dla historyków. Jeśli planujesz użyć modelu grawitacji w swoich badaniach naukowych, autor zdecydowanie zaleca następujące artykuły:
podziękowania
z podziękowaniami dla Angeli Kedgley, Sarah Lloyd, Tima Hitchcocka, Joe Cozensa, Katriny Navickas i Leanne Calvert za przeczytanie i skomentowanie wcześniejszych wersji tego artykułu. Również podziękowania dla British Academy za sfinansowanie warsztatów pisarskich w Bogocie, w Kolumbii, na których powstał ten artykuł. A na koniec Adam Dennett za zapoznanie mnie z tymi wspaniałymi formułami i uwolnienie ich potencjału dla historyków.