As a data scientist in consumer industry, what I usually feel is, boosting algorithms are quite enough for most of the predictive learning tasks, at least by now. Eles são poderosos, flexíveis e podem ser interpretados de forma agradável com alguns truques. Assim, eu acho que é necessário ler através de alguns materiais e escrever algo sobre os algoritmos impulsionadores.
A maior parte do conteúdo deste actículo baseia-se no papel: reforço de árvores com XGBoost: por que é que o XGBoost ganha “cada” concurso de aprendizagem à máquina?. É um artigo muito informativo. Quase tudo a respeito de impulsionar algoritmos é explicado muito claramente no papel. Assim, o artigo contém 110 páginas: (
para mim, eu basicamente me focarei nos três algoritmos impulsionadores mais populares: AdaBoost, GBM e XGBoost. Dividi o conteúdo em duas partes. O primeiro artigo (este) vai se concentrar no algoritmo AdaBoost, e o segundo vai se virar para a comparação entre GBM e XGBoost.
AdaBoost, abreviatura de” Adaptative Boosting”, é o primeiro algoritmo de estímulo prático proposto por Freund e Schapire em 1996. Centra-se em problemas de classificação e Visa converter um conjunto de classificadores fracos em um forte. A equação final para a classificação pode ser representada como
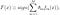
onde f_m representa o m_th fraco classificador e theta_m é o peso correspondente. É exatamente a combinação ponderada de classificadores m fracos. Todo o procedimento do algoritmo AdaBoost pode ser resumido como segue.Algoritmo AdaBoost
dado um conjunto de dados contendo n pontos, em que

aqui -1 denota a classe negativa enquanto 1 representa a positiva.
Inicializar o peso para cada ponto de dados como:

Para a iteração m=1,…,M:
(1) Ajuste fraco classificadores para o conjunto de dados e selecione aquele com o menor erro de classificação ponderada:

(2) Calcular o peso para a m_th classificador fraco:

Para qualquer classificador com precisão superior a 50%, o peso é positivo. Quanto mais preciso o classificador, maior o peso. Enquanto para o classificador com menos de 50% de precisão, o peso é negativo. Significa que combinamos a sua previsão, invertendo o sinal. Por exemplo, podemos transformar um classificador com 40% de precisão em 60% de precisão, invertendo o sinal da previsão. Assim, mesmo o classificador executa pior do que adivinhação Aleatória, ele ainda contribui para a previsão final. Nós só não queremos nenhum classificador com precisão de 50%, o que não adiciona nenhuma informação e, portanto, não contribui com nada para a previsão final.
(3) Actualizar o peso para cada ponto de dados como:

onde Z_m é um fator de normalização que garante a soma de todos os instância pesos é igual a 1.
se um caso mal Classificado for de um classificador ponderado positivo, o termo ” exp ” no numerador seria sempre maior que 1 (y*f é sempre -1, theta_m é positivo). Assim, casos mal classificados seriam atualizados com pesos maiores após uma iteração. A mesma lógica se aplica aos classificadores ponderados negativos. A única diferença é que as classificações originais corretas se tornariam erros de classificação depois de virar o sinal.
após a iteração podemos obter a previsão final somando a previsão ponderada de cada classificador.
AdaBoost as a Forward Stagewise Additive Model
This part is based on paper: Additive logistic regression: a statistical view of boosting. Para informações mais detalhadas, consulte o documento original.
em 2000, Friedman et al. desenvolveu uma visão estatística do algoritmo AdaBoost. They interpreted AdaBoost as stagewise estimation procedures for fitting an additive logistic regression model. Eles mostraram que adaboost de aprendizagem de máquina foi, na verdade, minimizando a perda exponencial função

Ele é minimizado em

Uma vez que para adaboost de aprendizagem de máquina, y só pode ser -1 ou 1, a perda de função pode ser reescrito como

Continuar para resolver F(x), obtemos

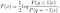
podemos ainda obter o normal modelo logístico da melhor solução de F(x):

Ele é quase idêntico ao modelo de regressão logística, apesar de um fator de 2.
suponha que temos uma estimativa atual de F (x) e tentar buscar uma estimativa melhorada F(x)+cf(x). Fixas, c e x, podemos expandir L(y, F(x)+fq(x)) para a segunda ordem de f(x)=0,

Assim,,

onde E_w(.|x) indica uma média ponderada condicional expectativa e o peso para cada ponto de dados é calculado como

Se c > 0, minimizando ponderada condicional expectativa é de igual para maximizar

Desde que y só pode ser 1 ou -1, ponderada expectativa pode ser reescrito como

A solução ideal vem como

após a determinação de f (x), o peso c pode ser calculado minimizando diretamente L (y, F (x)+cf (x))):

a Solução para c, temos


Deixe epsilon é igual à soma ponderada dos classificadas incorretamente casos, em seguida,

Note que c pode ser negativo, se o fraco aluno faz pior do que a escolha aleatória (50%), em que caso reverte automaticamente a polaridade.
Em termos de instância pesos, depois de melhorado disso, o peso de um único exemplo, torna-se,

Assim, a instância de peso é atualizada conforme o

em Comparação com os utilizados no algoritmo adaboost de aprendizagem de máquina,

podemos ver que eles são de forma idêntica. Portanto, é razoável interpretar adaboost de aprendizagem de máquina como uma stagewise aditivo modelo exponencial com perda de função, que, iterativamente, adapta-se um fraco classificador para melhorar a estimativa, em cada iteração m:
