existem também várias maneiras erradas de incluir variáveis. Um modelo gravitacional não funcionará a menos que cada variável cumpre os seguintes critérios de:
- Numérico
- Completo
- Confiável
Dados Numéricos Apenas
Como o modelo gravitacional é uma equação matemática, todas as variáveis de entrada devem ser numéricos. Pode ser uma contagem (população), medida espacial (área, distância, etc), Tempo (horas a pé de Londres), percentagem (aumento/diminuição salarial), valor monetário (salários em xelins), ou alguma outra medida dos locais envolvidos no modelo.
os números devem ser significativos e não podem ser variáveis categóricas nominais que atuam como um stand-in para um atributo qualitativo. Por exemplo, você não pode atribuir arbitrariamente um número e usá-lo no modelo se o número não tem significado (eg, road quality = bom, ou road quality = 4). Embora este último seja numérico, não é uma medida da qualidade da estrada. Em vez disso, você pode usar a velocidade média de viagem em milhas por hora como um proxy para a qualidade da estrada. Se a velocidade média é uma medida significativa da qualidade da estrada depende de você para determinar e defender como o autor do estudo.De um modo geral, se você pode medi-lo ou contá-lo, você pode modelá-lo.
dados completos apenas
todas as categorias de dados devem existir para cada ponto de interesse. Isso significa que todos os 32 condados em análise devem ter dados confiáveis para cada fator de push e pull. Você não pode ter quaisquer lacunas ou lacunas, como um condado onde você não tem o salário médio.
dados confiáveis apenas
o adágio de ciência da computação “lixo dentro, lixo fora” também se aplica aos modelos de gravidade, que são apenas tão confiáveis quanto os dados usados para construí-los. Além de escolher dados históricos robustos e confiáveis a partir de fontes que você pode confiar, existem muitas maneiras de cometer erros que irão tornar as saídas do seu modelo sem sentido. Por exemplo, vale a pena certificar-se de que os dados que você tem correspondem exatamente aos territórios (eg, dados do condado para representar condados, não dados da cidade para representar um condado).Dependendo do tempo e do local do seu estudo, poderá ter dificuldade em obter um conjunto fiável de dados sobre os quais basear o seu modelo. Quanto mais para trás no estudo do passado, mais difícil pode ser. Da mesma forma, pode ser mais fácil conduzir este tipo de análises em sociedades que eram fortemente burocráticas e deixaram um bom rasto de papel, como na Europa ou na América do Norte.
para garantir a qualidade dos dados neste estudo de caso, cada variável foi calculada de forma fiável ou derivada de dados históricos revistos por pares publicados (ver Quadro 1). Exatamente como esses dados foram compilados pode ser lido no artigo original onde foi explicado em profundidade.11
nossas cinco variáveis modelo
com os princípios acima em mente, nós poderíamos ter escolhido qualquer número de variáveis, dado o que nós sabíamos sobre os fatores de impulso de migração e pull. Fixámo-nos em cinco (5), escolhidos com base no que pensávamos ser mais importante, e que sabíamos que poderiam ser apoiados com dados fiáveis.
| Variável | Fonte |
|---|---|
| população na origem | 1771 valores, Wrigley, “condado inglês populações”, pp. 54-5.12 |
| distância de Londres | calculados com o software |
| preço do trigo | Canhão e Grosso, “Semanário Britânico Preços de Grãos”13 |
| os salários médios na origem | Hunt, “a Industrialização e Desigualdade Regional”, pp. 965-6.14 |
| trajetória dos salários | Hunt, “a Industrialização e Desigualdade Regional”, pp. 965-6.15 |
Tabela 1: As cinco variáveis utilizadas no modelo, e a origem de cada um na literatura especializada
Tendo decidido sobre estas variáveis, o co-autor do estudo original, Adão Dennett, decidiu reescrever a fórmula para torná-lo auto-documentar, de modo que era fácil dizer que os bits pertencia a cada uma dessas cinco variáveis. É por isso que a fórmula mostrada acima parece diferente da do trabalho de pesquisa original. Os novos símbolos podem ser vistos na Tabela 2:
duas variáveis adicionais $I$ E $j$, A média “no ponto de origem” e “em Londres”, respectivamente. $Wa_{i}$ significa “níveis salariais no ponto de origem”, enquanto que $Wa_{j}$ significaria “níveis salariais em Londres”. Estes sete novos símbolos podem substituir os mais genéricos na fórmula:
\
esta é agora mais descritiva e uma versão ligeiramente auto-documentada da equação anterior. Ambos resolvem matematicamente exatamente da mesma maneira, pois as mudanças são puramente superficiais e em benefício de um usuário humano.
the Completed Variable Dataset
To make the tutorial faster to complete, the data for each of the 5 variables and each of the 32 counties have already been compiled and cleaned, and can be seen in Table 3 or downloaded as a csv file. Este quadro também inclui o número conhecido de vagabundos desse Condado, como observado no registo de fontes primárias.:
| Condado | Vagabundos | $d$ km de Londres | $P$ População (pessoas) | $Wa$ Salário Médio (shillings) | $WaT$ Salário Trajetória 1767-95 (variação em%) | $Wh$ Preço do Trigo (shillings) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornualha | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| O Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
A diferença final entre esta fórmula e o artigo original, é que as duas variáveis possuem um relacionamento mais forte com a vadiagem quando plotados, naturalmente, de forma logarítmica. Eles são a população de origem ($p$) e distância da origem para Londres ($d$). O que isso significa é que para os dados deste estudo, a linha de regressão (às vezes chamada de linha de melhor ajuste) é um ajuste melhor quando os dados foram registrados do que quando não foi. Você pode ver isso na Figura 7, com os números da população não registrada à esquerda, e a versão registrada à direita. Mais dos pontos estão mais perto da linha de melhor ajuste no grafo logado do que no não-logado.
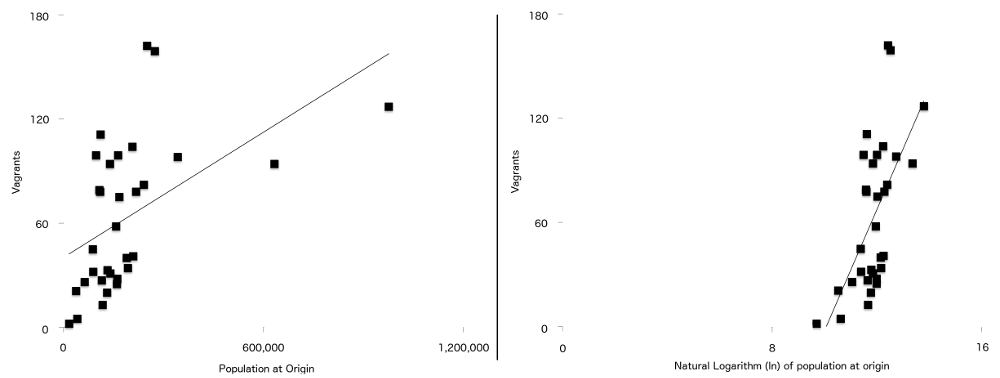
Figura 7: Número de vagabundos traçados em relação à população de origem (esquerda), e logótipo natural da população de origem (direita) com uma simples linha de regressão sobreposta em ambos. Observe a relação mais forte entre as duas variáveis visíveis no segundo grafo.
como este é o caso com esses dados particulares (seus próprios dados em um tipo similar de estudo podem não seguir este padrão), a fórmula foi ajustada para usar as versões naturalmente registradas dessas duas variáveis, resultando na fórmula final usada no modelo de gravidade (Figura 8). Nós não poderíamos saber sobre a necessidade deste ajuste até que nós tivéssemos coletado nossos dados variáveis:
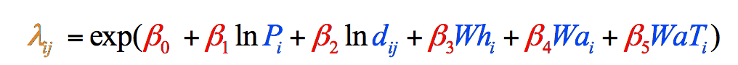
Figura 8: a fórmula do modelo de gravidade final, discriminada por etapas e por cores. Elementos em Preto São operações matemáticas. Elementos em azul representam nossas variáveis, que acabamos de reunir (Passo 1). Elementos em vermelho representam as ponderações de cada variável, que devemos calcular (Passo 2), e o elemento em laranja é a estimativa final de vagabundos daquele condado, que podemos calcular uma vez que tenhamos a outra informação (Passo 3).
os valores da Tabela 3 nos dão tudo o que precisamos para preencher as partes azuis de cada equação na Figura 8. Podemos agora voltar nossa atenção para as partes vermelhas, que nos dizem o quão importante cada variável é no modelo em geral, e nos dá os números que precisamos para completar a equação.
Step 2: determinando as ponderações
as ponderações para cada variável nos dizem o quão importante esse fator de push / pull é em relação às outras variáveis ao tentar estimar o número de vagabundos que deveriam ter vindo de um determinado Condado. Os parâmetros $ β$ devem ser determinados em todo o conjunto de dados a partir dos dados conhecidos. Com estes à mão, poderemos comparar observações específicas de origem individual com o modelo geral. Podemos então examiná-los e identificar os fluxos previstos entre as várias origens e o destino.
nesta fase não sabemos a importância de cada um. Talvez o preço do trigo seja um melhor preditor da migração do que a distância? Não saberemos até que calculemos os valores de $ β1$ a $ β5$ (as ponderações) resolvendo a equação acima. A interceptação em y ($β0$) só é possível calcular uma vez que você conheça todos os outros ($β1-β5$). Estes são os valores de vermelho na Figura 8 acima. As ponderações podem ser vistas no quadro 4 e no quadro A1 do papel original.16 vamos agora demonstrar como chegámos a estes valores.
para calcular estes valores de mão longa requer uma quantidade incrível de trabalho. Usaremos uma solução rápida na linguagem de Programação R que se aproveita de William Venables e do pacote de massa de Brian Ripley que pode resolver equações de regressão binomial negativas como o nosso modelo de gravidade com uma única linha de código. No entanto, é importante entender os princípios por trás do que se está fazendo a fim de apreciar o que o código faz (note que as seguintes seções não fazem o cálculo, mas explicar seus passos para você; vamos fazer o cálculo com o código mais adiante na página).
Calcular os pesos Individuais (em Princípio)
$β_{1}$, $β_{2}$, etc., são o mesmo que $b$ a Simples modelo de Regressão Linear acima, que é a inclinação da linha de regressão (a ascensão durante uma corrida, ou o quanto de $y$ aumenta quando $x$ aumenta em 1). A única diferença aqui entre uma regressão Linear simples e nosso modelo de gravidade é que temos que calcular 5 inclinações em vez de 1.
uma regressão Linear simples\(y = α + ßx\)
teremos de resolver para cada uma destas cinco encostas antes de podermos calcular a interceptação em y no próximo passo. Isso é porque as inclinações dos vários valores $ β$ São parte da equação para calcular a interceptação Y.
a fórmula para calcular$ β $ numa análise de regressão é:
\
coeficiente de correlação de Pearson
coeficiente de correlação de Pearson pode ser calculado em mão longa, mas é um cálculo bastante longo neste caso, exigindo 64 números. Existem alguns grandes tutoriais de vídeo em inglês disponível online Se você gostaria de ver um passeio de como fazer os cálculos de mão longa.17 Há também um número de calculadoras on-line que irá calcular $R$ para você se você fornecer os dados. Dado o grande número de dígitos para computar, eu recomendaria um site com uma ferramenta construída em projetada para fazer este cálculo. Certifique-se de escolher um site respeitável, como um oferecido por uma universidade.
calculando $s_{y}$& $s_{x}$ (desvio padrão)
desvio padrão é uma forma de expressar quanta variação da média (média) existe nos dados. Em outras palavras, os dados estão bastante agrupados em torno da média, ou a propagação é muito maior?
novamente, existem calculadoras online e pacotes de software estatístico que podem fazer este cálculo para você se você fornecer os dados.
calculando $β_{0}$ (a ordenada em y)
a seguir, temos de calcular a ordenada em y. A fórmula para calcular a intercepção de y em uma Regressão Linear Simples é:
\
no Entanto, o cálculo torna-se muito mais complicado em uma análise de regressão múltipla, como cada variável influencia o cálculo. Isso torna muito difícil fazê-lo à mão, e é uma das razões pelas quais optamos por uma solução programática.
o código para calcular as ponderações
o pacote estatístico de massa, escrito para a linguagem de Programação R, tem uma função que pode resolver equações de regressão binomial negativas, tornando muito fácil calcular o que de outra forma seria uma fórmula de mão longa muito difícil.
esta secção assume que você instalou R e instalou o pacote de massa. Se não o fez, terá de o fazer antes de prosseguir. O tutorial de Taryn Dewar sobre R Basics com dados tabulares inclui instruções de instalação R.
para usar este código, você precisará baixar uma cópia do conjunto de dados das cinco variáveis mais o número de vagabundos observados de cada um dos 32 condados. Isto está disponível na Tabela 3, ou pode ser baixado como a .ficheiro csv. Qualquer modo que você escolher, Salve o arquivo como VagrantsExampleData.csv. Se você está usando um Mac certifique-se de salvá-lo como um formato Windows .ficheiro csv. Open VagrantsExampleData.csv e familiarizar-se com o seu conteúdo. Você deve notar cada um dos 32 condados, juntamente com cada uma das variáveis que discutimos ao longo deste tutorial. Vamos usar os cabeçalhos das colunas para aceder a estes dados com o nosso Programa de computador. Eu poderia ter chamado qualquer coisa, mas nesse arquivo são:
vagrantspopulationdistancewheatwageswageTrajectory
No mesmo diretório que você salvou o arquivo csv, criar e salvar um novo arquivo de script (você pode fazer isso com qualquer editor de texto ou com o RStudio, mas não use um processador de texto como o MS Word). Guarda-o como cálculo de peso.R.
vamos agora escrever um pequeno programa que:
- instala o pacote de massa
- chama o pacote de massa para que possamos usá-lo em nosso código
- armazena o conteúdo do .csv file to a variable that we can use programmatically
- Solves the gravity model equation using the dataset
- Outputs the results of the calculation.
Cada uma destas tarefas será alcançado com uma única linha de código
Copie o código acima no seu weightingsCalculations.R file and save. Você pode agora executar o código usando o seu ambiente R favorito (eu uso RStudio) e os resultados do cálculo devem aparecer na janela da consola (o que este aspecto vai depender do seu ambiente). Você pode precisar definir o diretório de trabalho do seu ambiente R para o diretório que contém o seu .csv e …ficheiros R. Se estiver a usar o RStudio, poderá fazê-lo através dos menus (Session- > defina a pasta de trabalho – > escolha a pasta). Você também pode alcançar o mesmo com o comando:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundObserve que a linha 4 é a linha que resolve a equação para nós, utilizando glm.nb function, which is short for “generalized linear model-negative binomial”. Esta linha requer uma série de entradas:
- nossas variáveis usando os cabeçalhos das colunas como escrito no .arquivo csv, juntamente com qualquer registro que deve ser feito a eles (
vagrants, log (population), log(distance),wheat,wages,wageTrajectory). Se você estivesse executando um modelo com seus próprios dados, você ajustaria estes para refletir seus cabeçalhos de colunas em seu conjunto de dados. - onde o código pode encontrar os dados-neste caso uma variável que definimos na linha 3 chamada
gravityModelData.
Os resultados do cálculo pode ser visto na Figura 9:
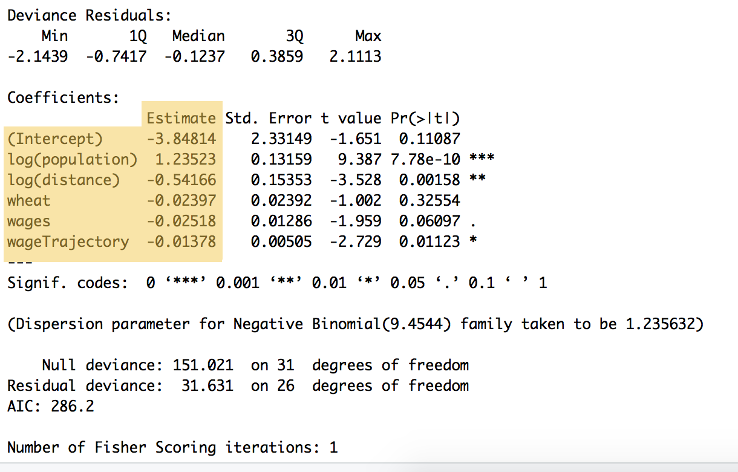
Figura 9: O resumo do código acima, mostrando os coeficientes de ponderação para cada variável e a intercepção de y, listados em ‘Estimar’ título ($\beta_{0}$ e $\beta_{5}$. Este resumo também mostra uma série de outros cálculos, incluindo significância estatística.
Passo 3: Calculando as estimativas para cada Condado
temos de fazer isto uma vez para cada um dos 32 condados.
você poderia fazer isso com uma calculadora científica, criando uma fórmula de planilha, ou escrevendo um programa de computador. Para fazer isso automaticamente em R, você pode adicionar o seguinte ao seu código e Executar novamente o programa. Este loop for calcula o número esperado de vagabundos de cada um dos 32 condados no exemplo e imprime os resultados para você ver:
para construir entendimento, eu sugiro fazer uma mão longa do Condado. Este tutorial irá usar Hertfordshire como exemplo de mão longa (mas o processo é exatamente o mesmo para os outros 31 condados).
Usando os dados de Hertfordshire, na Tabela 3, e os coeficientes de ponderação para cada variável na Tabela 4, podemos agora completar a nossa fórmula, que vai dar o resultado de 95:
Primeiro, vamos trocar os símbolos para os números, tomados a partir das tabelas acima mencionadas.
então, comece a calcular os valores para chegar à estimativa. Lembrando a ordem matemática das operações, multiplique os valores antes de adicionar. Então comece por calcular cada variável (você pode usar uma calculadora científica para este):
O próximo passo é adicionar os números juntos:
estimated vagrants = exp(4.56232408897)E, finalmente, para calcular a função exponencial (usar uma calculadora científica):
estimated vagrants = 95.8059926832Temos caiu o restante e declarou que o número estimado de vagabundos de Hertfordshire, neste modelo é 95. Você tem que realizar os mesmos cálculos para cada um dos outros condados, que você poderia acelerar usando um programa de planilha. Só para ter a certeza de que pode fazê-lo novamente, também incluí os números para Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
recomendo escolher um outro condado e calculá-lo de mãos longas antes de seguir em frente, para ter a certeza de que pode fazer os cálculos sozinho. A resposta correta está disponível na Tabela 5, que compara os valores observados (como visto no registro de fonte primária) com os valores estimados (como calculado pelo nosso modelo de gravidade). O “Residual” é a diferença entre os dois, com uma grande diferença sugerindo um número inesperado de vagabundos que pode valer a pena olhar mais de perto com o chapéu do historiador.
| Condado | Valor Observado | Valor Estimado | Residual |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornualha | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| O Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Warwickshire | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Passo 4 – Interpretação Histórica
nesta fase, o processo de modelagem é concluída e a fase final é a interpretação histórica.
o artigo original publicado no qual este estudo de caso foi baseado, é dedicado principalmente à interpretação do que os resultados da modelização significam para a nossa compreensão da migração de classe inferior no século XVIII. Como se vê no mapa da Figura 5, havia partes do país que o modelo fortemente sugerido eram migrantes de classe baixa em excesso ou em sub – envio para Londres.
os co-autores ofereceram suas interpretações sobre por que esses padrões podem ter aparecido. Estas interpretações variavam por lugar. Em áreas do Norte de Inglaterra que se industrializavam rapidamente, como Yorkshire ou Manchester, as oportunidades localmente pareciam dar às pessoas menos razões para sair, resultando em uma migração menor do que o esperado para Londres. Em áreas em declínio para o oeste, como Bristol, a atração de Londres era mais forte à medida que mais pessoas deixadas em busca de trabalho na capital.
nem todos os padrões foram esperados. Northumberland no extremo nordeste provou ser uma anomalia regional, enviando muito mais migrantes (mulheres) para Londres do que seria de esperar. Sem as saídas do modelo, é pouco provável que tivéssemos pensado em considerar Northumberland em tudo, particularmente porque estava tão longe da metrópole e presumimos que teria laços fracos com Londres. O modelo assim forneceu novas evidências para que nós considerássemos como historiadores e mudássemos nossa compreensão da relação Londres-Northumberland. Uma discussão completa de nossas descobertas pode ser lida no artigo original.18
Tomar o Seu Conhecimento para a Frente
Depois de ter experimentado este problema de exemplo, você deve ter uma compreensão clara de como usar essa fórmula de exemplo, bem como se é ou não um modelo gravitacional pode ser uma solução adequada para o seu problema de pesquisa. Você tem a experiência e o vocabulário para abordar e discutir modelos de gravidade com um colaborador adequadamente alfabetizado se precisar, que pode ajudá-lo a adaptá-lo ao seu próprio estudo de caso.Se você tiver a sorte de também ter dados sobre migrantes que se deslocam para o final do século XVIII em Londres e quiser modelá-los usando as mesmas cinco variáveis listadas acima, esta fórmula funcionaria como – está-há um estudo fácil aqui para alguém com os dados certos. No entanto, este modelo não trabalha apenas para estudos sobre migrantes que se deslocam para Londres. As variáveis podem mudar, e o destino não precisa ser Londres. Seria possível usar um modelo de gravidade para estudar a migração para a Roma antiga, ou Banguecoque do século XXI, se você tiver os dados e a questão da pesquisa. Nem sequer precisa de ser um modelo de migração. Para usar o estudo de caso do café colombiano da introdução, que se concentra no comércio e não na migração, a Tabela 6 mostra um uso viável da mesma fórmula, inalterado.
| Critérios de | Café Exportação de Exemplo |
|---|---|
| de UM ponto de origem | exportações de café para o porto de Barranquilla, Colômbia |
| VÁRIOS finito destinos | 21 países do Hemisfério Ocidental, no 1950 |
| CINCO variáveis explicativas | (1) número do Oceano Atlântico portas no país receptor (2) quilômetros da Colômbia, (3) o Produto Interno Bruto do país receptor, (4) Interno de Café cultivada em toneladas, (5) lojas de café por 10.000 pessoas |
há uma longa história de modelos de gravidade na erudição acadêmica. Para usar um eficazmente para a pesquisa, você precisa entender a teoria básica e matemática por trás deles e as razões que eles desenvolveram como eles têm. É igualmente importante compreender os seus limites e condições para os utilizar correctamente, alguns dos quais foram discutidos acima. Também pode ajudar saber:
-
um modelo de gravidade como o usado neste exemplo só pode funcionar em um sistema fechado. O modelo acima tinha apenas 32 pontos de origem possíveis, tornando possível executar o modelo 32 vezes. Um número desconhecido ou infinitamente grande de pontos de origem (ou destinos dependendo do seu modelo), exigiria uma equação diferente.
-
o conceito de modelo de gravidade também se baseia na premissa de que os movimentos (migração, comércio, etc.) são baseados em uma coleção de decisões individuais voluntárias que podem ser influenciadas por fatores externos, mas não são totalmente controlados por eles. Por exemplo, as migrações voluntárias ou as compras feitas de livre arbítrio poderiam ser modeladas utilizando esta técnica, mas a migração forçada, a compra obrigatória ou processos naturais como a migração de aves ou o fluxo fluvial podem não seguir os mesmos princípios e, portanto, pode ser necessário um tipo diferente de modelo.
-
modelos de gravidade podem ser usados para prever o comportamento das populações, mas não dos indivíduos, e, portanto, as tentativas de modelar dados devem incluir um grande número de movimentos para garantir a significância estatística.
há muitas mais armadilhas, mas também enormes possibilidades. É minha esperança que esta passagem de um modelo de gravidade, e sua pesquisa publicada que acompanha, torne esta poderosa ferramenta mais acessível para os historiadores. Se você estiver planejando usar um modelo gravitacional em sua pesquisa acadêmica, o autor recomenda os seguintes artigos:
Agradecimentos
Com os nossos agradecimentos Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas, e Leanne Calvert para ler e comentar sobre versões preliminares deste artigo. Também graças à Academia Britânica por financiar o workshop de escrita em Bogotá, Colômbia, no qual este artigo foi redigido. E finalmente a Adam Dennett por me apresentar a estas fórmulas maravilhosas e libertar o seu potencial para os historiadores.