Atualizada por Último sobre 7 de agosto de 2019
Word incorporações são um tipo de representação de palavra que permite que palavras com significado semelhante para ter uma representação similar.
eles são uma representação distribuída para o texto que é talvez um dos principais avanços para o desempenho impressionante de métodos de aprendizagem profunda em desafiar problemas de processamento de linguagem natural.
neste post, você irá descobrir a abordagem de incorporação de palavras para representar dados de texto.
depois de completar este post, você saberá:
- Qual é a abordagem de incorporação de palavras para representar o texto e como ele difere de outros métodos de extração de recursos.
- existem 3 algoritmos principais para aprender uma incorporação de palavras a partir de dados de texto.
- pode treinar uma nova incorporação ou utilizar uma incorporação pré-treinada na sua tarefa de processamento da linguagem natural.
kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.Vamos começar.

What Are Word Embeddings for Text?Foto de Heather, alguns direitos reservados.
- visão geral
- precisa de ajuda com a aprendizagem profunda para dados de texto?Tome agora o meu curso gratuito de 7 dias de acidente por e-mail (com código).
- quais são as incorporações de palavras?
- algoritmos de incorporação de palavras
- camada de incorporação
- Word2Vec
- GloVe
- usando incorporações de palavras
- Aprenda uma incorporação
- reutilizar uma incorporação
- Que Opção Deve Utilizar?
- tutoriais com incorporação de palavras
- Leitura Adicional
- Articles
- Papers
- Projects
- Books
- resumo
- desenvolver modelos de aprendizagem profunda para dados de texto hoje!
- desenvolver os seus próprios modelos de texto em minutos
- finalmente trazer a aprendizagem profunda para os seus projectos de processamento de línguas naturais
visão geral
este post está dividido em 3 partes; eles são:
- o que são incorporações de palavras?
- algoritmos de incorporação de palavras
- usando incorporações de palavras
precisa de ajuda com a aprendizagem profunda para dados de texto?Tome agora o meu curso gratuito de 7 dias de acidente por e-mail (com código).
Clique para se inscrever e também obter uma versão em PDF do curso.
iniciar o seu curso livre de colisão agora
quais são as incorporações de palavras?
uma incorporação de palavras é uma representação aprendida para o texto onde as palavras que têm o mesmo significado têm uma representação semelhante.É esta abordagem à representação de palavras e documentos que pode ser considerada um dos principais avanços da aprendizagem profunda de problemas de processamento de línguas naturais.
um dos benefícios do uso de vetores densos e de dimensões baixas é computacional.: a maioria das ferramentas de rede neural não funcionam bem com vetores muito dimensionais e esparsos. … O principal benefício das representações densas é o poder de generalização: se acreditamos que algumas características podem fornecer pistas semelhantes, vale a pena fornecer uma representação que é capaz de capturar essas semelhanças.
— Page 92, Neural Network Methods in Natural Language Processing, 2017.
as incorporações de palavras são, de facto, uma classe de técnicas em que as palavras individuais são representadas como vectores de valor real num espaço vetorial predefinido. Cada palavra é mapeada para um vetor e os valores vetoriais são aprendidos de uma forma que se assemelha a uma rede neural, e, portanto, a técnica é muitas vezes amontoada no campo da aprendizagem profunda.
a chave para a abordagem é a ideia de usar uma representação distribuída densa para cada palavra.Cada palavra é representada por um vetor de valor real, muitas vezes dezenas ou centenas de dimensões. Isto é contrastado com os milhares ou milhões de dimensões necessárias para representações de palavras esparsas, como uma codificação de uma só palavra.
associe com cada palavra no vocabulário um vector de palavra distribuída … o vector de característica representa diferentes aspectos da palavra: cada palavra está associada a um ponto num espaço vetorial. O número de características … é muito menor do que o tamanho do vocabulário
— a Neural Probabilistic Language Model, 2003.
a representação distribuída é aprendida com base no uso de palavras. Isso permite que palavras que são usadas de formas semelhantes resultem em ter representações semelhantes, naturalmente capturando seu significado. Isto pode ser contrastado com a representação crisp mas frágil em um modelo de saco de palavras onde, a menos que explicitamente gerenciado, palavras diferentes têm representações diferentes, independentemente de como eles são usados.
há uma teoria linguística mais profunda por trás da abordagem, a saber, a “hipótese de distribuição” de Zellig Harris que poderia ser resumida como: palavras que têm um contexto semelhante terão significados semelhantes. For more depth see Harris ‘1956 paper ” Distributional structure”.
esta noção de deixar o uso da palavra definir o seu significado pode ser resumida por um Quip muitas vezes repetido por John Firth:
sabereis uma palavra da companhia que guarda!
— Page 11,” a synopsis of linguistic theory 1930-1955″, in Studies in Linguistic Analysis 1930-1955, 1962.
algoritmos de incorporação de palavras
métodos de incorporação de palavras aprendem uma representação vectorial de valor real para um vocabulário de tamanho fixo predefinido a partir de um corpo de texto.
o processo de aprendizagem é ou conjunto com o modelo de rede neural em alguma tarefa, como classificação de documentos, ou é um processo não supervisionado, usando estatísticas de documentos.
esta secção analisa três técnicas que podem ser usadas para aprender uma palavra a partir de dados de texto.
camada de incorporação
uma camada de incorporação, por falta de um nome melhor, é uma incorporação de palavras que é aprendida em conjunto com um modelo de rede neural em uma tarefa específica de processamento de linguagem natural, como modelagem de linguagem ou classificação de documentos.Exige que o texto do documento seja limpo e preparado de modo a que cada palavra seja codificada a quente. O tamanho do espaço vetorial é especificado como parte do modelo, tais como 50, 100 ou 300 dimensões. Os vetores são inicializados com pequenos números aleatórios. A camada de incorporação é usada na extremidade dianteira de uma rede neural e é adequada de uma forma supervisionada usando o algoritmo de Backpropagação.
… quando a entrada para uma rede neural contém características categóricas simbólicas (ex. características que fazem um de k símbolos distintos, tais como palavras de um fechado de vocabulário), é comum associar a cada possível valor do recurso (i.é., cada palavra no vocabulário) com um d-dimensional vetor para alguns d. Esses vetores são então considerados os parâmetros do modelo, e são treinados em conjunto com outros parâmetros.
— Página 49, Neural Network Methods in Natural Language Processing, 2017.
as palavras codificadas a quente são mapeadas para os vetores de palavra. Se um modelo Perceptron multi-camadas é usado, então os vetores Palavra são concatenados antes de serem alimentados como entrada para o modelo. Se uma rede neural recorrente é usada, então cada palavra pode ser tomada como uma entrada em uma sequência.
esta abordagem de aprender uma camada incorporada requer um monte de dados de treinamento e pode ser lento, mas vai aprender uma incorporação tanto direcionada para os dados de texto específico e a tarefa NLP.
Word2Vec
Word2Vec é um método estatístico para a aprendizagem eficiente de uma palavra independente a partir de um corpo de texto.Foi desenvolvido por Tomas Mikolov, et al. no Google, em 2013, como uma resposta para tornar o treinamento baseado em rede neural da incorporação mais eficiente e, desde então, tornou-se o padrão de fato para o desenvolvimento de incorporação de palavras pré-treinadas.
adicionalmente, o trabalho envolveu a análise dos vetores aprendidos e a exploração da matemática vetorial sobre as representações das palavras. Por exemplo, que subtrair o “homem-ness” de “Rei” e adicionar “mulher-ness” resulta na palavra “Rainha”, capturando a analogia “Rei é a rainha como o homem é a mulher”.
achamos que estas representações são surpreendentemente boas a capturar regularidades sintáticas e semânticas na linguagem, e que cada relação é caracterizada por um deslocamento vetorial específico de relação. Isto permite um raciocínio orientado a Vetores baseado nas compensações entre palavras. Por exemplo, a relação homem/mulher é automaticamente aprendida, e com as representações vetoriais induzidas, “King – Man + Woman” resulta em um vetor muito próximo de “Queen”.”
— Linguistic Regularities in Continuous Space Word Representations, 2013.Foram introduzidos dois modelos de aprendizagem diferentes que podem ser utilizados como parte da abordagem word2vec para aprender a palavra incorporação; :
- um saco de palavras contínuo,ou um modelo de arco.
- Modelo Skip-Gram Contínuo.
o modelo CBOW aprende a incorporação prevendo a palavra atual com base em seu contexto. O modelo skip-gram contínuo aprende prevendo as palavras circundantes dadas uma palavra atual.
o modelo skip-gram contínuo aprende prevendo as palavras circundantes dadas uma palavra atual.
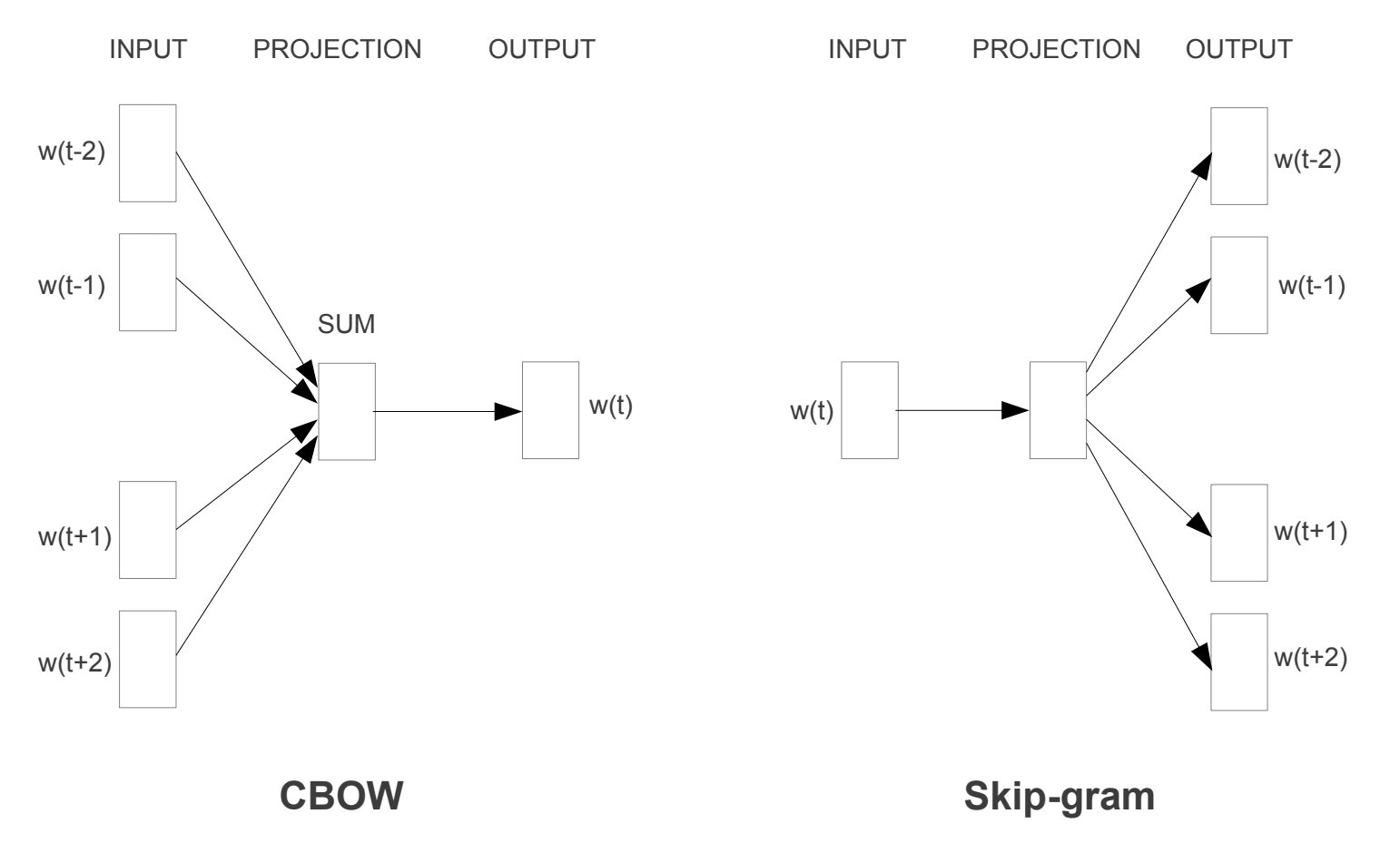
Word2Vec Modelos de Formação
retirado de “Eficiente Estimativa da Palavra Representações no Espaço Vetorial”, 2013
Ambos os modelos são voltados para a aprendizagem de palavras, dado o seu local de uso de contexto, onde o contexto é definido por uma janela da vizinha palavras. Esta janela é um parâmetro configurável do modelo.
o tamanho da janela deslizante tem um forte efeito sobre as semelhanças vetoriais resultantes. As janelas grandes tendem a produzir semelhanças mais tópicas , enquanto as janelas menores tendem a produzir semelhanças mais funcionais e sintáticas.
— página 128, Neural Network Methods in Natural Language Processing, 2017.
o principal benefício da abordagem é que incorporações de palavras de alta qualidade podem ser aprendidas eficientemente (baixo espaço e complexidade de tempo), permitindo que incorporações maiores sejam aprendidas (mais dimensões) de corpora de texto muito maior (bilhões de palavras).
GloVe
the Global Vectors for Word Representation, or GloVe, algorithm is an extension to the word2vec method for eficientemente learning word vectors, developed by Pennington, et al. em Stanford.
modelo de espaço vetorial Clássico representações de palavras foram desenvolvidas usando técnicas de factorização de matriz, tais como a análise semântica latente (LSA) que fazem um bom trabalho de usar estatísticas de texto global, mas não são tão bons quanto os métodos aprendidos como word2vec na captura de significado e demonstrá-lo em Tarefas como o cálculo de analogias (e.g. o exemplo do rei e da Rainha acima).GloVe é uma abordagem para casar tanto as estatísticas globais de técnicas de factorização de matrizes como LSA com o aprendizado local baseado no contexto no word2vec.
ao invés de usar uma janela para definir o contexto local, a luva constrói uma matriz explícita de co-ocorrência de palavras ou palavras usando estatísticas em todo o corpo de texto. O resultado é um modelo de aprendizagem que pode resultar em incorporações de palavras geralmente melhores.
luva, é um novo modelo global de regressão log-bilinear para a aprendizagem não supervisionada de representações de palavras que supera outros modelos em analogia de palavras, similaridade de palavras, e nomeado tarefas de reconhecimento de entidades.
— GloVe: Global Vectors for Word Representation, 2014.
usando incorporações de palavras
tem algumas opções quando chegar a altura de usar incorporações de palavras no seu projecto de processamento da linguagem natural.
esta secção descreve essas opções.
Aprenda uma incorporação
pode optar por aprender uma incorporação de palavras para o seu problema.
isto exigirá uma grande quantidade de dados de texto para garantir que as incorporações úteis são aprendidas, tais como milhões ou bilhões de palavras.
tem duas opções principais ao treinar a incorporação de palavras:
- aprenda Standalone, onde um modelo é treinado para aprender a incorporação, que é salvo e usado como parte de outro modelo para sua tarefa mais tarde. Esta é uma boa abordagem se você gostaria de usar a mesma incorporação em vários modelos.
- Aprenda em conjunto, onde a incorporação é aprendida como parte de um grande modelo específico de tarefa. Esta é uma boa abordagem se você só pretende usar a incorporação em uma tarefa.
reutilizar uma incorporação
é comum que os investigadores disponibilizem de forma gratuita as incorporações de palavras pré-treinadas, muitas vezes sob uma licença permissiva para que possa usá-las nos seus próprios projectos académicos ou comerciais.
por exemplo, tanto a incorporação de palavras word2vec e luvas estão disponíveis para download gratuito.
estes podem ser usados no seu projecto em vez de treinar as suas próprias incorporações a partir do zero.
tem duas opções principais quando se trata de usar incorporações pré-treinadas:
- estática, onde a incorporação é mantida estática e é usada como um componente do seu modelo. Esta é uma abordagem adequada se a incorporação é um bom ajuste para o seu problema e dá bons resultados.
- Updated, where the pre-trained embedding is used to seed the model, but the embedding is updated jointly during the training of the model. Esta pode ser uma boa opção se você está olhando para tirar o máximo proveito do modelo e incorporar em sua tarefa.
Que Opção Deve Utilizar?
Explore as diferentes opções, e se possível, teste para ver qual dá os melhores resultados sobre o seu problema.
talvez começar com métodos rápidos, como usar uma incorporação pré-treinada, e só usar uma nova incorporação se resultar em melhor desempenho no seu problema.
tutoriais com incorporação de palavras
esta secção lista alguns tutoriais passo-a-passo que poderá seguir para usar a incorporação de palavras e trazer a incorporação de palavras ao seu projecto.
- Como Desenvolver Palavra Incorporações em Python com Gensim
- Como Usar o Word Incorporação de Camadas para uma Aprendizagem mais Profunda com Keras
- Como Desenvolver um Profundo CNN para Análise de Sentimento (Classificação de Texto)
Leitura Adicional
Esta seção fornece mais recursos sobre o tema, se você estiver procurando ir mais fundo.
Articles
- Word embedding on Wikipedia
- Word2vec on Wikipedia
- GloVe on Wikipedia
- An overview of word embeddings and their connection to distributional semantic models, 2016.
- Deep Learning, NLP, and Representations, 2014.
Papers
- Distributional structure, 1956.
- A Neural Probabilistic Language Model, 2003.
- a Unified Architecture for Natural Language Processing: Deep Neural Networks with multitarefa Learning, 2008.
- Continuous space language models, 2007.
- Efficient Estimation of Word Representations in Vector Space, 2013
- Distributed Representations of Words and Phrases and their Compositionality, 2013.GloVe: Global Vectors for Word Representation, 2014.
Projects
- word2vec on Google Code
- GloVe: Global Vectors for Word Representation
Books
- Neural Network Methods in Natural Language Processing, 2017.
resumo
neste post, descobriu a incorporação de palavras como um método de representação para o texto em aplicações de aprendizagem profunda.Especificamente, aprendeu:
- Qual é a abordagem de incorporação de palavras para o texto de representação e como ele difere de outros métodos de extração de recursos.
- existem 3 algoritmos principais para aprender uma incorporação de palavras a partir de dados de texto.
- pode treinar uma nova incorporação ou utilizar uma incorporação pré-treinada na sua tarefa de processamento da linguagem natural.Tem alguma pergunta?Faça suas perguntas nos comentários abaixo e farei o meu melhor para responder.
desenvolver modelos de aprendizagem profunda para dados de texto hoje!

desenvolver os seus próprios modelos de texto em minutos
…com apenas algumas linhas do código python
descubra como no meu novo Ebook:
Deep Learning for Natural Language Processingele fornece tutoriais de auto-estudo sobre tópicos como:
Bag-of-Words, incorporação de palavras, modelos de linguagem, geração de Legendas, tradução de texto e muito mais…finalmente trazer a aprendizagem profunda para os seus projectos de processamento de línguas naturais
Skip the Academics. Apenas Resultados.Veja o que tem dentro
percentagem de Tweet