o introducere blând la auto-Encoder și unele dintre cazurile sale comune de utilizare cu cod Python
fundal:
Autoencoder este o rețea neuronală artificială nesupravegheată, care învață cum să comprima eficient și codifica date, apoi învață cum să reconstruiască datele înapoi de la reprezentarea codificată redusă la o reprezentare care este cât mai aproape de intrarea originală posibil.
Autoencoder, prin design, reduce dimensiunile datelor învățând cum să ignore zgomotul din date.
Iată un exemplu de imagine de intrare/ieșire din setul de date MNIST la un autoencoder.
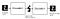
componente Autoencoder:
Autoencoders este format din 4 părți principale:
1 – Encoder: în care modelul învață cum să reducă dimensiunile de intrare și comprima datele de intrare într-o reprezentare codificată.
2-strangulare: care este stratul care conține reprezentarea comprimată a datelor de intrare. Acestea sunt cele mai mici dimensiuni posibile ale datelor de intrare.
3 – decodor: în care modelul învață cum să reconstruiască datele din reprezentarea codificată pentru a fi cât mai aproape de intrarea originală.
4 – pierderea reconstrucției: aceasta este metoda care măsoară cât de bine funcționează decodorul și cât de aproape este ieșirea de intrarea originală.
instruirea implică apoi utilizarea propagării înapoi pentru a minimiza pierderea reconstrucției rețelei.
trebuie să vă întrebați De ce aș antrena o rețea neuronală doar pentru a afișa o imagine sau date Exact la fel ca intrarea! Acest articol va acoperi cele mai frecvente cazuri de utilizare pentru Autoencoder. Să începem:
arhitectura Autoencoder:
arhitectura de rețea pentru autoencodere poate varia între o rețea simplă FeedForward, rețea LSTM sau rețea neuronală convoluțională, în funcție de cazul de utilizare. Vom explora unele dintre aceste arhitecturi în noile linii următoare.
există multe modalități și tehnici de detectare a anomaliilor și a valorilor aberante. Am acoperit acest subiect într-o altă postare de mai jos:
cu toate acestea, dacă aveți date de intrare corelate, metoda autoencoder va funcționa foarte bine, deoarece operația de codificare se bazează pe caracteristicile corelate pentru a comprima datele.
să presupunem că am instruit un autoencoder pe setul de date MNIST. Folosind o rețea neuronală simplă FeedForward, putem realiza acest lucru construind o rețea simplă de 6 straturi, după cum urmează:
ieșirea codului de mai sus este:
după cum puteți vedea în ieșire, ultima pierdere/eroare de reconstrucție pentru setul de validare este 0.0193, ceea ce este minunat. Acum, dacă trec orice imagine normală din setul de date MNIST, pierderea de reconstrucție va fi foarte scăzută (< 0.02), dar dacă am încercat să trec orice altă imagine diferită (outlier sau anomalie), vom obține o valoare ridicată a pierderii de reconstrucție, deoarece rețeaua nu a reușit să reconstruiască imaginea/intrarea care este considerată o anomalie.
observație în codul de mai sus, puteți utiliza numai partea codificatorului pentru a comprima unele date sau imagini și puteți utiliza, de asemenea, numai partea decodificatorului pentru a decomprima datele încărcând straturile decodificatorului.
acum, să facem o detectare a anomaliilor. Codul de mai jos folosește două imagini diferite pentru a prezice scorul anomaliei (eroare de reconstrucție) folosind rețeaua autoencoder pe care am antrenat-o mai sus. prima imagine este de la MNIST și rezultatul este 5.43209. Aceasta înseamnă că imaginea nu este o anomalie. A doua imagine pe care am folosit-o, este o imagine complet aleatorie, care nu aparține setului de date de antrenament și rezultatele au fost: 6789.4907. Această eroare mare înseamnă că imaginea este o anomalie. Același concept se aplică oricărui tip de set de date.