Ultima actualizare la 7 August 2019
încorporările de cuvinte sunt un tip de reprezentare a cuvintelor care permite cuvintelor cu semnificație similară să aibă o reprezentare similară.
sunt o reprezentare distribuită pentru text, care este probabil una dintre descoperirile cheie pentru performanța impresionantă a metodelor de învățare profundă asupra problemelor provocatoare de procesare a limbajului natural.
în această postare, veți descoperi abordarea de încorporare a cuvintelor pentru reprezentarea datelor text.
după finalizarea acestui post, veți ști:
- care este abordarea de încorporare a cuvintelor pentru reprezentarea textului și cum diferă de alte metode de extragere a caracteristicilor.
- că există 3 algoritmi principali pentru învățarea unui cuvânt încorporat din date text.
- că puteți fie să instruiți o nouă încorporare, fie să utilizați o încorporare pre-instruită în sarcina dvs. de procesare a limbajului natural.
începeți proiectul cu noua mea carte Deep Learning pentru procesarea limbajului Natural, inclusiv tutoriale pas cu pas și fișierele de cod sursă Python pentru toate exemplele.
să începem.

ce sunt încorporările de cuvinte pentru Text?
fotografie de Heather, unele drepturi rezervate.
- Prezentare generală
- aveți nevoie de ajutor cu învățarea profundă pentru date Text?
- ce sunt încorporările de cuvinte?
- algoritmi de încorporare a cuvintelor
- strat de încorporare
- Word2Vec
- GloVe
- utilizarea încorporărilor Word
- aflați o încorporare
- reutilizați o încorporare
- Ce Opțiune Ar Trebui Să Utilizați?
- tutoriale de încorporare a cuvintelor
- Lectură suplimentară
- articole
- lucrări
- proiecte
- Cărți
- rezumat
- dezvoltați modele de învățare profundă pentru datele Text astăzi!
- dezvoltați propriile modele de Text în câteva minute
- în cele din urmă aduceți învățarea profundă proiectelor dvs. de procesare a limbajului natural
Prezentare generală
acest post este împărțit în 3 părți; acestea sunt:
- ce sunt încorporările de cuvinte?
- algoritmi de încorporare a cuvintelor
- folosind încorporări de cuvinte
aveți nevoie de ajutor cu învățarea profundă pentru date Text?
Ia-Mi gratuit 7 zile de e-mail crash course acum (cu cod).
Faceți clic pentru a vă înscrie și pentru a obține, de asemenea, o versiune gratuită PDF Ebook a cursului.
începeți cursul gratuit acum
ce sunt încorporările de cuvinte?
un cuvânt embedding este o reprezentare învățat pentru text în cazul în care cuvintele care au același sens au o reprezentare similară.
această abordare a reprezentării cuvintelor și documentelor poate fi considerată una dintre descoperirile cheie ale învățării profunde asupra problemelor provocatoare de procesare a limbajului natural.
unul dintre avantajele utilizării vectorilor densi și cu dimensiuni reduse este calculul: majoritatea seturilor de instrumente de rețea neuronală nu se joacă bine cu vectori foarte dimensionali, rari. … Principalul beneficiu al reprezentărilor dense este puterea de generalizare: dacă credem că unele caracteristici pot oferi indicii similare, merită să oferim o reprezentare capabilă să surprindă aceste asemănări.
— pagina 92, metode de rețea neuronală în procesarea limbajului Natural, 2017.
încorporările de cuvinte sunt de fapt o clasă de tehnici în care cuvintele individuale sunt reprezentate ca vectori cu valoare reală într-un spațiu vectorial predefinit. Fiecare cuvânt este mapat la un vector și valorile vectoriale sunt învățate într-un mod care seamănă cu o rețea neuronală și, prin urmare, tehnica este adesea introdusă în domeniul învățării profunde.
cheia abordării este ideea de a folosi o reprezentare densă distribuită pentru fiecare cuvânt.
fiecare cuvânt este reprezentat de un vector cu valoare reală, adesea zeci sau sute de dimensiuni. Acest lucru este în contrast cu mii sau milioane de dimensiuni necesare pentru reprezentări de cuvinte rare, cum ar fi o codificare one-hot.
asociați cu fiecare cuvânt din vocabular un vector de cuvânt distribuit … vectorul de caracteristică reprezintă diferite aspecte ale cuvântului: fiecare cuvânt este asociat cu un punct dintr-un spațiu vectorial. Numărul de caracteristici … este mult mai mic decât dimensiunea vocabularului
— un model de limbaj Neural Probabilistic, 2003.
reprezentarea distribuită se învață pe baza utilizării cuvintelor. Acest lucru permite cuvintelor care sunt folosite în moduri similare să aibă ca rezultat reprezentări similare, surprinzând în mod natural semnificația lor. Acest lucru poate fi contrastat cu reprezentarea clară, dar fragilă, într-un model de sac de cuvinte în care, cu excepția cazului în care sunt gestionate în mod explicit, cuvinte diferite au reprezentări diferite, indiferent de modul în care sunt utilizate.
există o teorie lingvistică mai profundă în spatele abordării, și anume „ipoteza distributivă” de Zellig Harris care ar putea fi rezumată astfel: cuvintele care au un context similar vor avea semnificații similare. Pentru mai multă profunzime, a se vedea lucrarea lui Harris din 1956 „structura distributivă”.
această noțiune de a lăsa utilizarea cuvântului să-i definească semnificația poate fi rezumată printr-o glumă repetată de John Firth:
veți ști un cuvânt al companiei pe care o păstrează!
— pagina 11,” un sinopsis al teoriei lingvistice 1930-1955″, în studii de analiză lingvistică 1930-1955, 1962.
algoritmi de încorporare a cuvintelor
metode de încorporare a cuvintelor aflați o reprezentare vectorială cu valoare reală pentru un vocabular predefinit de dimensiuni fixe dintr-un corpus de text.
procesul de învățare este fie comun cu modelul rețelei neuronale pe o anumită sarcină, cum ar fi clasificarea documentelor, fie este un proces nesupravegheat, folosind statistici ale documentelor.
această secțiune trece în revistă trei tehnici care pot fi folosite pentru a învăța un cuvânt încorporat din date text.
strat de încorporare
un strat de încorporare, din lipsa unui nume mai bun, este un cuvânt de încorporare Care este învățat împreună cu un model de rețea neuronală pe o sarcină specifică de procesare a limbajului natural, cum ar fi modelarea limbajului sau clasificarea documentelor.
este necesar ca textul documentului să fie curățat și pregătit astfel încât fiecare cuvânt să fie codificat la cald. Dimensiunea spațiului vectorial este specificată ca parte a modelului, cum ar fi Dimensiunile 50, 100 sau 300. Vectorii sunt inițializați cu numere aleatorii mici. Stratul de încorporare este utilizat pe capătul frontal al unei rețele neuronale și se potrivește într-un mod supravegheat folosind algoritmul Backpropagation.
… când intrarea într-o rețea neuronală conține caracteristici categorice simbolice (de ex. caracteristici care iau unul dintre k simboluri distincte, cum ar fi cuvinte dintr-un vocabular închis), este obișnuit să asociați fiecare valoare posibilă a caracteristicii (adică fiecare cuvânt din vocabular) cu un vector d-dimensional pentru unii d. acești vectori sunt apoi considerați parametri ai modelului și sunt instruiți împreună cu ceilalți parametri.
— pagina 49, metode de rețea neuronală în procesarea limbajului Natural, 2017.
cuvintele codificate la cald sunt mapate la vectorii de cuvinte. Dacă se folosește un model Perceptron multistrat, atunci cuvântul vectori sunt concatenați înainte de a fi alimentați ca intrare la model. Dacă se folosește o rețea neuronală recurentă, atunci fiecare cuvânt poate fi luat ca o intrare într-o secvență.
această abordare a învățării unui strat de încorporare necesită o mulțime de date de instruire și poate fi lentă, dar va învăța o încorporare atât orientată către datele text specifice, cât și către sarcina NLP.
Word2Vec
Word2Vec este o metodă statistică pentru învățarea eficientă a unui cuvânt independent încorporarea dintr-un corpus de text.
a fost dezvoltat de Tomas Mikolov și colab. la Google în 2013, ca răspuns pentru a face formarea bazată pe rețele neuronale a încorporării mai eficientă și de atunci a devenit standardul de facto pentru dezvoltarea încorporării cuvintelor pre-instruite.
în plus, lucrarea a implicat analiza vectorilor învățați și explorarea matematicii vectoriale asupra reprezentărilor cuvintelor. De exemplu, că scăderea „bărbatului” din „Rege” și adăugarea „femeilor” are ca rezultat cuvântul „regină”, surprinzând analogia „regele este pentru regină așa cum bărbatul este pentru femeie”.
constatăm că aceste reprezentări sunt surprinzător de bune la captarea regularităților sintactice și semantice în limbaj și că fiecare relație este caracterizată de o compensare vectorială specifică relației. Acest lucru permite raționamentul orientat pe vectori bazat pe compensările dintre cuvinte. De exemplu, relația bărbat/femeie este învățată automat, iar cu reprezentările vectoriale induse, „rege – bărbat + femeie” are ca rezultat un vector foarte apropiat de „regină.”
— regularități lingvistice în reprezentări de cuvinte spațiale continue, 2013.
au fost introduse două modele diferite de învățare care pot fi utilizate ca parte a abordării word2vec pentru a învăța cuvântul încorporare; acestea sunt:
- sac-de-cuvinte continuă, sau modelul CCOW.
- Modelul Continuă Skip-Gram.
modelul CCOW învață încorporarea prin prezicerea cuvântului curent pe baza contextului său. Modelul continuă skip-gram învață prin prezicerea cuvintele din jur dat un cuvânt curent.
modelul continuă skip-gram învață prin prezicerea cuvintele din jur dat un cuvânt curent.
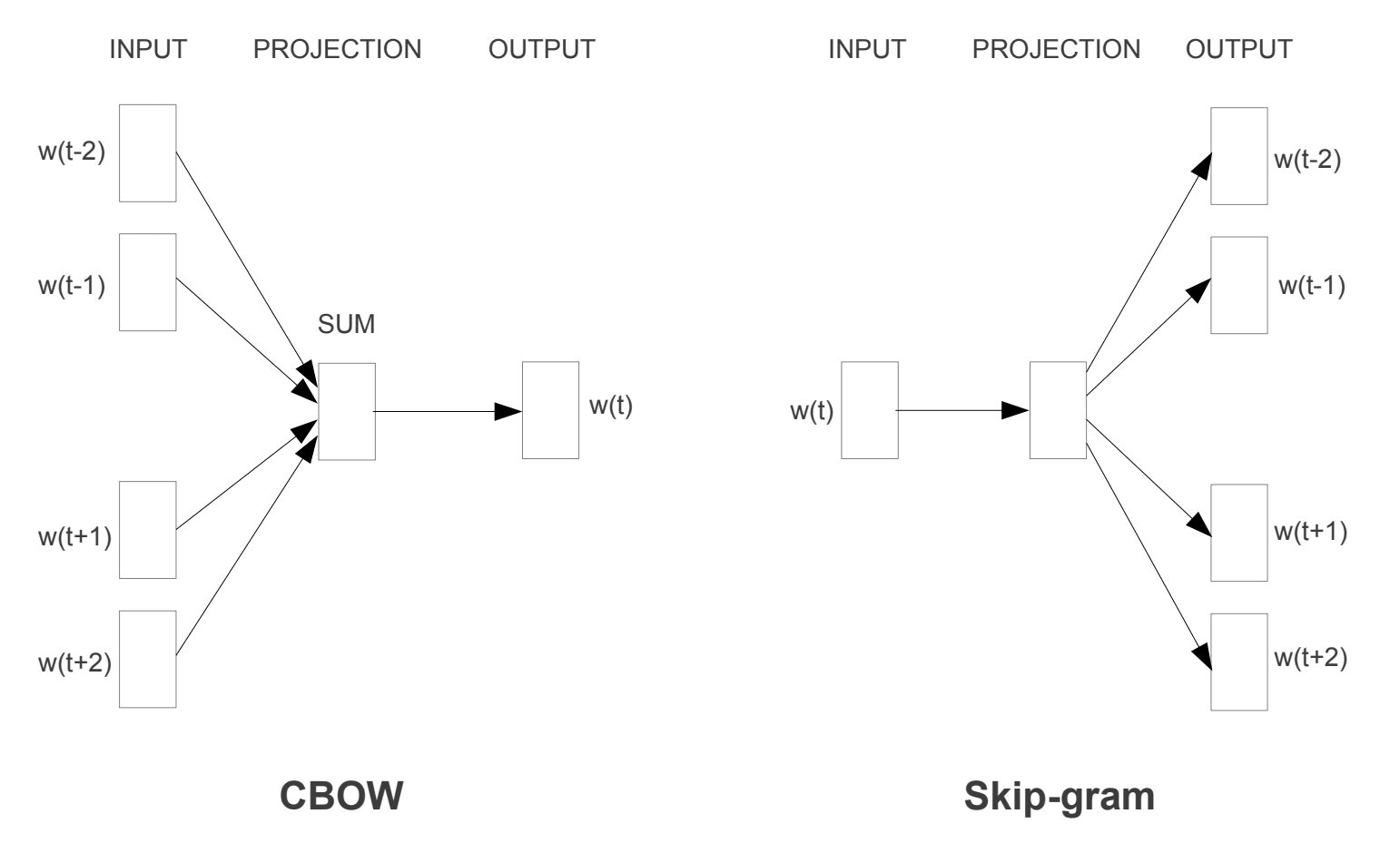
modele de antrenament Word2Vec
preluate din „estimarea eficientă a reprezentărilor cuvintelor în spațiul vectorial”, 2013
ambele modele sunt axate pe învățarea despre cuvinte având în vedere contextul lor de utilizare locală, unde contextul este definit de o fereastră de cuvinte vecine. Această fereastră este un parametru configurabil al modelului.
dimensiunea ferestrei glisante are un efect puternic asupra asemănărilor vectoriale rezultate. Ferestrele mari tind să producă asemănări mai actuale , în timp ce ferestrele mai mici tind să producă asemănări mai funcționale și sintactice.
— pagina 128, metode de rețea neuronală în procesarea limbajului Natural, 2017.
beneficiul cheie al abordării este că încorporările de cuvinte de înaltă calitate pot fi învățate eficient (complexitate redusă a spațiului și timpului), permițând învățarea încorporărilor mai mari (mai multe dimensiuni) din corpuri mult mai mari de text (miliarde de cuvinte).
GloVe
vectorii globali pentru reprezentarea cuvintelor sau algoritmul GloVe este o extensie a metodei word2vec pentru învățarea eficientă a vectorilor de cuvinte, dezvoltată de Pennington și colab. la Stanford.
reprezentările clasice ale modelului de spațiu vectorial ale cuvintelor au fost dezvoltate folosind tehnici de factorizare a matricei, cum ar fi analiza semantică latentă (lsa), care fac o treabă bună în utilizarea statisticilor globale de text, dar nu sunt la fel de bune ca metodele învățate precum word2vec la captarea sensului și demonstrarea acestuia pe sarcini precum calcularea analogiilor (de ex. exemplul regelui și reginei de mai sus).
GloVe este o abordare pentru a combina atât statisticile globale ale tehnicilor de factorizare a matricei, cum ar fi LSA, cu învățarea locală bazată pe context în word2vec.
în loc să folosească o fereastră pentru a defini contextul local, GloVe construiește un cuvânt-context explicit sau o matrice de co-apariție a cuvintelor folosind statistici în întregul corpus de text. Rezultatul este un model de învățare care poate duce la încorporări de cuvinte în general mai bune.
GloVe, este un nou model global de regresie log-biliniară pentru învățarea nesupravegheată a reprezentărilor de cuvinte care depășește alte modele privind analogia cuvintelor, similitudinea cuvintelor și sarcinile de recunoaștere a entității numite.
— mănușă: vectori globali pentru reprezentarea cuvintelor, 2014.
utilizarea încorporărilor Word
aveți câteva opțiuni atunci când vine vorba de utilizarea încorporărilor word în proiectul dvs. de procesare a limbajului natural.
această secțiune prezintă aceste opțiuni.
aflați o încorporare
puteți alege să învățați un cuvânt de încorporare pentru problema dvs.
acest lucru va necesita o cantitate mare de date text pentru a se asigura că încorporările utile sunt învățate, cum ar fi milioane sau miliarde de cuvinte.
aveți două opțiuni principale atunci când vă antrenați încorporarea cuvântului:
- Learn it Standalone, unde un model este instruit să învețe încorporarea, care este salvată și utilizată ca parte a unui alt model pentru sarcina dvs. ulterioară. Aceasta este o abordare bună dacă doriți să utilizați aceeași încorporare în mai multe modele.
- aflați în comun, unde Încorporarea este învățată ca parte a unui model specific pentru sarcini mari. Aceasta este o abordare bună dacă intenționați să utilizați încorporarea pe o singură sarcină.
reutilizați o încorporare
este obișnuit ca cercetătorii să pună la dispoziție gratuit încorporări de cuvinte pre-instruite, adesea sub o licență permisivă, astfel încât să le puteți utiliza în propriile proiecte academice sau comerciale.
de exemplu, ambele încorporări word2vec și Glove word sunt disponibile pentru descărcare gratuită.
acestea pot fi utilizate în proiectul dvs. în loc să vă antrenați propriile încorporări de la zero.
aveți două opțiuni principale atunci când vine vorba de utilizarea încorporărilor pre-instruite:
- Static, unde Încorporarea este păstrată statică și este utilizată ca o componentă a modelului dvs. Aceasta este o abordare adecvată dacă Încorporarea este potrivită pentru problema dvs. și dă rezultate bune.
- actualizat, unde încorporarea pre-instruită este utilizată pentru însămânțarea modelului, dar Încorporarea este actualizată împreună în timpul instruirii modelului. Aceasta poate fi o opțiune bună dacă doriți să profitați la maximum de model și să vă încorporați sarcina.
Ce Opțiune Ar Trebui Să Utilizați?
Explorați diferitele opțiuni și, dacă este posibil, testați pentru a vedea care oferă cele mai bune rezultate asupra problemei dvs.
poate începeți cu metode rapide, cum ar fi utilizarea unei încorporări pre-instruite și utilizați o nouă încorporare numai dacă rezultă o performanță mai bună asupra problemei dvs.
tutoriale de încorporare a cuvintelor
această secțiune enumeră câteva tutoriale pas cu pas pe care le puteți urmări pentru utilizarea încorporărilor de cuvinte și pentru a aduce încorporarea cuvintelor în proiectul dvs.
- cum să dezvolți încorporări de cuvinte în Python cu Gensim
- cum să folosești straturi de încorporare de cuvinte pentru învățarea profundă cu Keras
- cum să dezvolți un CNN profund pentru analiza sentimentului (Clasificarea textului)
Lectură suplimentară
această secțiune oferă mai multe resurse pe această temă dacă căutați mai adânc.
articole
- încorporarea cuvintelor pe Wikipedia
- Word2vec pe Wikipedia
- mănușă pe Wikipedia
- o prezentare generală a încorporărilor cuvintelor și a conexiunii lor la modelele semantice distributive, 2016.
- învățare profundă, NLP și reprezentări, 2014.
lucrări
- structura distributivă, 1956.
- Un Model De Limbaj Probabilistic Neural, 2003.
- o arhitectură unificată pentru procesarea limbajului Natural: rețele neuronale profunde cu învățare Multitask, 2008.
- modele de limbaj spațial continuu, 2007.
- estimarea eficientă a reprezentărilor cuvintelor în spațiul vectorial, 2013
- reprezentări distribuite ale cuvintelor și frazelor și Compoziționalitatea acestora, 2013.
- mănușă: vectori globali pentru reprezentarea cuvintelor, 2014.
proiecte
- word2vec pe codul Google
- mănușă: vectori globali pentru reprezentarea cuvintelor
Cărți
- metode de rețea neuronală în procesarea limbajului Natural, 2017.
rezumat
în această postare, ați descoperit încorporările de cuvinte ca metodă de reprezentare a textului în aplicațiile de învățare profundă.
mai exact, ai învățat:
- care este abordarea de încorporare a cuvintelor pentru textul de reprezentare și cum diferă de alte metode de extragere a caracteristicilor.
- că există 3 algoritmi principali pentru învățarea unui cuvânt încorporat din date text.
- că puteți fie să instruiți o nouă încorporare, fie să utilizați o încorporare pre-instruită în sarcina dvs. de procesare a limbajului natural.
aveți întrebări?
puneți-vă întrebările în comentariile de mai jos și voi face tot posibilul să răspund.
dezvoltați modele de învățare profundă pentru datele Text astăzi!

dezvoltați propriile modele de Text în câteva minute
…cu doar câteva linii de cod python
Descoperiți cum în noua mea carte electronică:
Deep Learning pentru procesarea limbajului Natural
oferă tutoriale de auto-studiu pe teme precum:
Bag-of-Words, încorporarea cuvintelor, modele lingvistice, generarea de subtitrări, traducerea textului și multe altele…
în cele din urmă aduceți învățarea profundă proiectelor dvs. de procesare a limbajului natural
săriți academicienii. Doar Rezultate.
vezi ce e înăuntru