există, de asemenea, o serie de moduri greșite în care puteți include variabile. Un model de gravitație nu va funcționa decât dacă fiecare variabilă îndeplinește următoarele criterii:
- numeric
- complet
- fiabil
numai date numerice
deoarece modelul gravitațional este o ecuație matematică, toate variabilele de intrare trebuie să fie numerice. Aceasta ar putea fi un număr (populație), măsură spațială (suprafață, distanță etc.), timp (ore de la Londra pe jos), procent (creștere/scădere a salariilor), valoare valutară (salarii în șilingi) sau o altă măsură a locurilor implicate în model.
numerele trebuie să fie semnificative și nu pot fi variabile nominale categorice care acționează ca un stand-in pentru un atribut calitativ. De exemplu, nu puteți atribui în mod arbitrar un număr și îl puteți utiliza în model dacă numărul nu are sens (de exemplu, road quality = bun sau road quality = 4). Deși acesta din urmă este numeric, nu este o măsură a calității drumului. În schimb, puteți utiliza viteza medie de deplasare în mile pe oră ca proxy pentru calitatea drumului. Dacă viteza medie este o măsură semnificativă a calității drumului, depinde de dvs. să determinați și să apărați ca autor al studiului.
în general, dacă îl puteți măsura sau număra, îl puteți modela.
date Complete numai
toate categoriile de date trebuie să existe pentru fiecare punct de interes. Asta înseamnă că toate cele 32 de județe analizate trebuie să aibă date fiabile pentru fiecare factor de împingere și tragere. Nu puteți avea lacune sau spații libere, cum ar fi un județ în care nu aveți Salariul mediu.
numai date fiabile
zicala informatică „gunoi în, gunoi afară” se aplică și modelelor gravitaționale, care sunt la fel de fiabile ca datele utilizate pentru a le construi. Dincolo de alegerea datelor istorice robuste și fiabile din surse în care puteți avea încredere, există o mulțime de modalități de a face greșeli care vor face ca rezultatele modelului dvs. să nu aibă sens. De exemplu, merită să vă asigurați că datele pe care le aveți Se potrivesc exact teritoriilor (de exemplu, datele județului pentru a reprezenta județele, nu datele orașului pentru a reprezenta un județ).
în funcție de ora și locul studiului, s-ar putea să vă fie dificil să obțineți un set fiabil de date pe care să vă bazați modelul. Cu cât mai mult înapoi în studiul trecut, cu atât mai dificil poate fi. De asemenea, poate fi mai ușor să se efectueze aceste tipuri de analize în societăți care au fost puternic birocratice și au lăsat o bună urmă de hârtie supraviețuitoare, cum ar fi în Europa sau America de Nord.
pentru a asigura calitatea datelor în acest studiu de caz, fiecare variabilă a fost fie calculată în mod fiabil, fie derivată din datele istorice publicate evaluate inter pares (a se vedea tabelul 1). Exact modul în care au fost compilate aceste date poate fi citit în articolul original, unde a fost explicat în profunzime.11
cele cinci variabile Model
având în vedere principiile de mai sus, am fi putut alege orice număr de variabile, având în vedere ceea ce știam despre factorii de împingere și tragere a migrației. Ne-am stabilit pe cinci (5), alese pe baza a ceea ce am crezut că ar fi cel mai important și despre care știam că ar putea fi susținute cu date fiabile.
| variabilă | sursă |
|---|---|
| populația la origine | 1771 valori, Wrigley, „populații județene engleze”, PP.54-5.12 |
| distanța de la Londra | calculată cu software |
| prețul de grâu | tun și greul, „prețurile săptămânale de cereale Britanice”13 |
| salariile medii la origine | Hunt, „industrializarea și inegalitatea Regională”, PP. 965-6.14 |
| traiectoria salariilor | Hunt, „industrializarea și inegalitatea Regională”, PP. 965-6.15 |
Tabelul 1: Cele cinci variabile utilizate în model și sursa fiecăreia din literatura de specialitate
după ce a decis asupra acestor variabile, coautorul studiului original, Adam Dennett, a decis să rescrie formula pentru a o face să se auto-documenteze, astfel încât să fie ușor de spus care biți se referă la fiecare dintre aceste cinci variabile. Acesta este motivul pentru care formula prezentată mai sus arată diferită de cea din lucrarea de cercetare originală. Noile simboluri pot fi văzute în tabelul 2:
două variabile suplimentare $I$ și $j$, înseamnă „la punctul de origine” și, respectiv, „la Londra”. $ Wa_{i} $ înseamnă „niveluri salariale la punctul de origine”, în timp ce $Wa_{j}$ ar însemna „niveluri salariale în Londra”. Aceste șapte simboluri noi le pot înlocui pe cele mai generice din formula:
\
aceasta este acum mai detaliată și o versiune ușor auto-documentată a ecuației anterioare. Ambele rezolvă matematic exact în același mod, deoarece schimbările sunt pur superficiale și în beneficiul unui utilizator uman.
setul de date variabile completat
pentru a face tutorialul mai ușor de completat, datele pentru fiecare dintre cele 5 variabile și fiecare dintre cele 32 de județe au fost deja compilate și curățate și pot fi văzute în tabelul 3 sau descărcate ca fișier csv. Acest tabel include, de asemenea, numărul cunoscut de vagabonzi din județul respectiv, așa cum se observă în înregistrarea sursei primare:
| Județul | vagabonzi | $ d $ km la Londra | $P$ populație (persoane) | $ Wa $ Salariul mediu (șilingi) | $ Wat $ traiectoria salariului 1767-95 (modificare%) | $WH $ prețul grâului (șilingi) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornwall | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
diferența finală dintre această formulă și cea utilizată în articolul original este că două dintre variabile se întâmplă să aibă o relație mai puternică cu vagabondajul atunci când sunt reprezentate natural logaritmic. Acestea sunt populația la origine ($P$) și distanța de la origine la Londra ($d$). Ceea ce înseamnă acest lucru este că pentru datele din acest studiu, linia de regresie (uneori numită linie de cea mai bună potrivire) este o potrivire mai bună atunci când datele au fost înregistrate decât atunci când nu au fost. Puteți vedea acest lucru în Figura 7, cu cifrele populației neînregistrate în stânga și versiunea autentificată în dreapta. Mai multe puncte sunt mai aproape de linia de potrivire optimă pe graficul înregistrat decât pe cel neînregistrat.
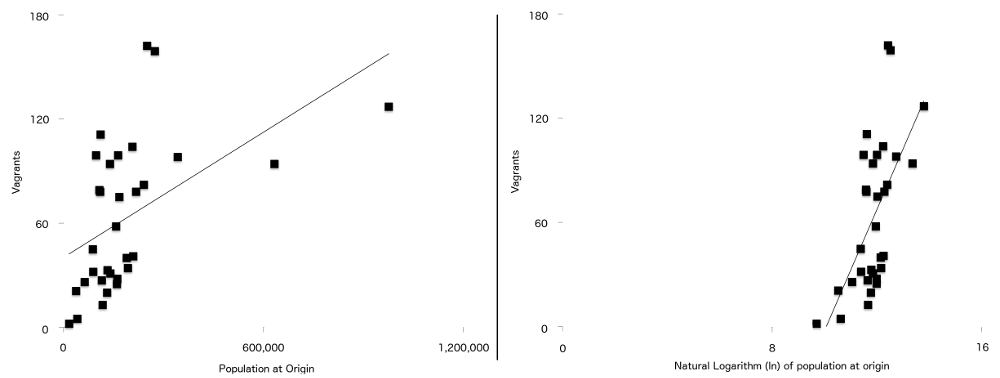
Figura 7: Numărul de vagabonzi complotat împotriva populației la origine (stânga) și jurnalul natural al populației de origine (dreapta) cu o linie de regresie simplă suprapusă pe ambele. Rețineți relația mai puternică dintre cele două variabile vizibile pe al doilea grafic.
deoarece acesta este cazul acestor date particulare (este posibil ca datele dvs. într-un tip similar de studiu să nu urmeze acest model), formula a fost ajustată pentru a utiliza versiunile înregistrate în mod natural ale acestor două variabile, rezultând formula finală utilizată în modelul gravitațional (figura 8). Nu am fi putut ști despre necesitatea acestei ajustări decât după ce am colectat datele noastre variabile:
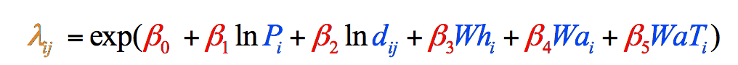
figura 8: formula finală a modelului gravitațional defalcată pe trepte și codificată prin culori. Elementele în negru sunt operații matematice. Elementele în albastru reprezintă variabilele noastre, pe care tocmai le-am adunat (Pasul 1). Elementele în roșu reprezintă ponderile fiecărei variabile, pe care trebuie să le calculăm (Pasul 2), iar elementul în portocaliu este estimarea finală a vagabonzilor din acel Județ, pe care o putem calcula odată ce avem celelalte informații (Pasul 3).
valorile din tabelul 3 ne oferă tot ce avem nevoie pentru a completa părțile albastre ale fiecărei ecuații din Figura 8. Acum ne putem îndrepta atenția asupra părților roșii, care ne spun cât de importantă este fiecare variabilă în modelul general și ne oferă numerele de care avem nevoie pentru a finaliza ecuația.
Pasul 2: Determinarea ponderilor
ponderile pentru fiecare variabilă ne spun cât de important este acel factor de împingere/tragere în raport cu celelalte variabile atunci când încercăm să estimăm numărul de vagabonzi care ar fi trebuit să provină dintr-un anumit județ. Parametrii $ XQX$ trebuie să fie determinați în întregul set de date din datele cunoscute. Cu acestea la îndemână vom putea compara observațiile individuale specifice originii cu modelul general. Putem apoi să le examinăm și să identificăm fluxurile peste și sub prezise între diferitele origini și destinație.
în acest stadiu nu știm cât de important este fiecare. Poate că prețul grâului este un predictor mai bun al migrației decât distanța? Nu vom ști până când nu vom calcula valorile de la $ 01 $ până la $ 5 $ (ponderile) prin rezolvarea ecuației de mai sus. Y-intercepta ($0$) este posibilă numai pentru a calcula o dată ce știi toate celelalte ($1-5$). Acestea sunt valorile roșii din Figura 8 de mai sus. Ponderile pot fi văzute în tabelul 4 și în tabelul A1 al lucrării originale.16 acum vom demonstra cum am ajuns la aceste valori.
pentru a calcula aceste valori mâna lungă necesită o cantitate incredibilă de muncă. Vom folosi o soluție rapidă în limbajul de programare R care profită de pachetul de masă al lui William Venables și Brian Ripley care poate rezolva ecuații de regresie binomială negativă, cum ar fi modelul nostru gravitațional, cu o singură linie de cod. Cu toate acestea, este important să înțelegeți principiile din spatele a ceea ce faceți pentru a aprecia ceea ce face codul (rețineți următoarele secțiuni nu fac calculul, ci explicați pașii acestuia pentru dvs.; vom face calculul cu codul mai jos pe pagină).
calculul ponderilor individuale (în principiu)
$0_{1}$, $x_{2}$, etc, sunt aceleași ca $X$ în modelul de regresie liniară simplă de mai sus, care este panta liniei de regresie (creșterea pe termen, sau cât de mult $y$ crește atunci când $x$ crește cu 1). Singura diferență aici între o regresie liniară simplă și modelul nostru gravitațional este că trebuie să calculăm 5 pante în loc de 1.
o regresie liniară simplă\(y = 0727>
va trebui să rezolvăm pentru fiecare dintre aceste cinci pante înainte de a putea calcula interceptarea y în pasul următor. Acest lucru se datorează faptului că pantele diferitelor valori de $inqus$ fac parte din ecuația pentru calcularea interceptării Y.
formula de calcul a $inxqua$ într-o analiză de regresie este:
\
coeficientul de corelație al lui Pearson
coeficientul de corelație al lui Pearson poate fi calculat cu mâna lungă, dar este un calcul destul de lung în acest caz, necesitând 64 de numere. Există câteva tutoriale video excelente în limba engleză disponibile online dacă doriți să vedeți o prezentare a modului de a face calculele cu mâna lungă.17 Există, de asemenea, o serie de calculatoare online care vor calcula $r$ pentru dvs. dacă furnizați datele. Având în vedere numărul mare de cifre de calculat, aș recomanda un site web cu un instrument încorporat conceput pentru a face acest calcul. Asigurați-vă că alegeți un site de renume, cum ar fi unul oferit de o universitate.
calculând $s_{y}$& $s_{x}$ (deviație Standard)
deviația Standard este o modalitate de a exprima cât de multă variație față de medie (medie) există în date. Cu alte cuvinte, datele sunt destul de grupate în jurul mediei sau răspândirea este mult mai largă?
din nou, există calculatoare online și pachete software statistice care pot face acest calcul pentru dvs. dacă furnizați datele.
calculând $xv_{0}$ (interceptarea y)
apoi, trebuie să calculăm interceptarea y. Formula de calcul a interceptării y într-o regresie liniară simplă este:
\
cu toate acestea, calculul devine mult mai complicat într-o analiză de regresie multiplă, deoarece fiecare variabilă influențează calculul. Acest lucru face ca acest lucru să fie foarte dificil și este unul dintre motivele pentru care optăm pentru o soluție programatică.
codul pentru calcularea ponderilor
pachetul statistic de masă, scris pentru limbajul de programare R, are o funcție care poate rezolva ecuațiile de regresie binomială negativă, ceea ce face foarte ușor să se calculeze ceea ce altfel ar fi o formulă foarte dificilă cu mâna lungă.
această secțiune presupune că ați instalat R și ați instalat pachetul de masă. Dacă nu ați făcut acest lucru, va trebui să înainte de a continua. Tutorialul lui Taryn Dewar despre elementele de bază R cu date tabulare include instrucțiuni de instalare R.
pentru a utiliza acest cod, va trebui să descărcați o copie a setului de date al celor cinci variabile plus numărul de vagabonzi observați din fiecare dintre cele 32 de județe. Acest lucru este disponibil mai sus ca tabelul 3, sau poate fi descărcat ca .fișier csv. Indiferent de modul pe care îl alegeți, salvați fișierul ca VagrantsExampleData.csv. Dacă utilizați un Mac, asigurați-vă că îl salvați ca format Windows .fișier csv. Deschideți VagrantsExampleData.csv și familiarizați-vă cu conținutul său. Ar trebui să observați fiecare dintre cele 32 de județe, împreună cu fiecare dintre variabilele pe care le-am discutat pe parcursul acestui tutorial. Vom folosi anteturile coloanelor pentru a accesa aceste date cu programul nostru de calculator. Aș fi putut să le numesc orice, dar în acest fișier sunt:
vagrantspopulationdistancewheatwageswageTrajectory
în același director în care ați salvat fișierul csv, creați și salvați un nou fișier script R (puteți face acest lucru cu orice editor de text sau cu RStudio, dar nu utilizați un procesor de text precum MS Word). Salvați-l ca ponderarecalcule.r.
vom scrie acum un scurt program care:
- instalează pachetul de masă
- solicită pachetul de masă, astfel încât să putem folosi în codul nostru
- stochează conținutul .fișierul csv la o variabilă pe care o putem folosi programatic
- rezolvă ecuația modelului gravitațional folosind setul de date
- scoate rezultatele calculului.
fiecare dintre aceste sarcini va fi realizată la rândul său, cu o singură linie de cod
copiați codul de mai sus în ponderareacalcule.fișier r și salvați. Acum Puteți rula codul folosind mediul dvs. preferat r (eu folosesc RStudio) și rezultatele calculului ar trebui să apară în fereastra consolei (cum arată acest lucru va depinde de mediul dvs.). Poate fi necesar să setați directorul de lucru al mediului dvs.csv și .fișiere R. Dacă utilizați RStudio puteți face acest lucru prin meniuri (sesiune -> Set director de lucru -> alege Director). De asemenea, puteți obține același lucru cu comanda:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundobservați că linia 4 este linia care rezolvă ecuația pentru noi, folosind glm.funcția nb, care este prescurtarea de la „model liniar generalizat – binom negativ”. Această linie necesită un număr de intrări:
- variabilele noastre folosind anteturile de coloană așa cum este scris în .fișier csv, împreună cu orice înregistrare care trebuie făcută acestora (
vagrants, jurnal (population), jurnal(distance),wheat,wages,wageTrajectory). Dacă executați un model cu propriile date, le-ați ajusta pentru a reflecta anteturile coloanelor din setul de date. - unde codul poate găsi datele – în acest caz o variabilă pe care am definit-o în linia 3 numită
gravityModelData.
rezultatele calculului pot fi văzute în Figura 9:
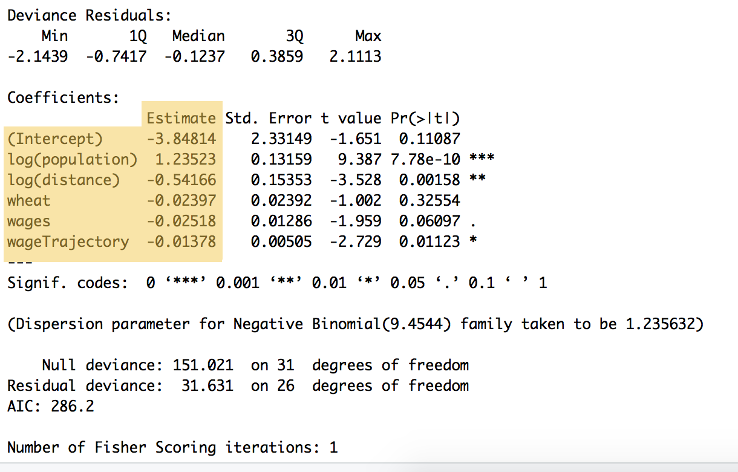
Figura 9: rezumatul codului de mai sus, care arată ponderile pentru fiecare variabilă și interceptarea y, enumerate la rubrica ‘estimare’ ($\beta_{0}$ la $\beta_{5}$. Acest rezumat arată, de asemenea, o serie de alte calcule, inclusiv semnificația statistică.
Pasul 3: Calculând estimările pentru fiecare județ
trebuie să facem acest lucru o dată pentru fiecare dintre cele 32 de județe.
puteți face acest lucru cu un calculator științific, creând o formulă de calcul tabelar sau scriind un program de calculator. Pentru a face acest lucru automat în R, puteți adăuga următoarele la codul dvs. și puteți rula din nou programul. Această buclă for calculează numărul așteptat de vagabonzi din fiecare dintre cele 32 de județe din exemplu și imprimă rezultatele pentru a le vedea:
pentru a construi înțelegerea, vă sugerez să faceți un județ cu mâna lungă. Acest tutorial va folosi Hertfordshire ca exemplu de mână lungă (dar procesul este exact același pentru celelalte 31 de județe).
folosind datele pentru Hertfordshire din tabelul 3 și ponderile pentru fiecare variabilă din tabelul 4, putem completa acum formula noastră, care va da rezultatul 95:
în primul rând, să schimbăm simbolurile pentru numere, preluate din tabelele menționate mai sus.
apoi, începeți să calculați valorile pentru a ajunge la estimare. Amintiți – vă ordinea matematică a operațiilor, înmulțiți valorile înainte de a adăuga. Deci, începeți prin calcularea fiecărei variabile (puteți utiliza un calculator științific pentru aceasta):
următorul pas este să adăugați numerele împreună:
estimated vagrants = exp(4.56232408897)și, în sfârșit, pentru a calcula funcția exponențială (utilizați un calculator științific):
estimated vagrants = 95.8059926832am renunțat la restul și am declarat că numărul estimat de vagabonzi din Hertfordshire în acest model este de 95. Trebuie să efectuați aceleași calcule pentru fiecare dintre celelalte județe, pe care le-ați putea accelera utilizând un program de foi de calcul. Doar pentru a vă asigura că o puteți face din nou, am inclus și numerele pentru Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
vă recomand să alegeți un alt județ și să îl calculați cu mâna lungă înainte de a merge mai departe, pentru a vă asigura că puteți face calculele pe cont propriu. Răspunsul corect este disponibil în tabelul 5, care compară valorile observate (așa cum se vede în înregistrarea sursei primare) cu valorile estimate (așa cum sunt calculate de modelul nostru de gravitație). „Rezidual” este diferența dintre cele două, cu o diferență mare sugerând un număr neașteptat de vagabonzi care ar putea merita o privire mai atentă cu pălăria istoricului.
| Județul | Valoarea Observată | Valoarea Estimată | Rezidual |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornwall | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Bucuresti | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Pasul 4-interpretarea istorică
în această etapă, procesul de modelare este complet, iar etapa finală este interpretarea istorică.
articolul original publicat pe care s-a bazat acest studiu de caz este dedicat în primul rând interpretării a ceea ce înseamnă rezultatele modelării pentru înțelegerea noastră a migrației de clasă inferioară în secolul al XVIII-lea. După cum se vede în harta din Figura 5, au existat părți ale țării pe care modelul le – a sugerat cu tărie fie că trimiteau prea mult, fie că nu trimiteau migranți de clasă inferioară la Londra.
coautorii și-au oferit interpretările cu privire la motivul pentru care aceste tipare ar fi putut apărea. Aceste interpretări au variat în funcție de loc. În zonele din nordul Angliei care se industrializau rapid, cum ar fi Yorkshire sau Manchester, oportunitățile locale păreau să ofere oamenilor mai puține motive să plece, rezultând o migrație mai mică decât se aștepta la Londra. În zonele în declin spre vest, cum ar fi Bristol, nada Londrei a fost mai puternică pe măsură ce mai mulți oameni au plecat în căutarea unui loc de muncă în capitală.
nu toate tiparele erau așteptate. Northumberland din nord-estul îndepărtat s-a dovedit a fi o anomalie regională, trimițând mult mai mulți migranți (femei) la Londra decât ne-am aștepta să vedem. Fără rezultatele modelului, este puțin probabil să ne fi gândit să luăm în considerare deloc Northumberland, mai ales pentru că era atât de departe de metropolă și am presupus că ar avea legături slabe cu Londra. Modelul a furnizat astfel noi dovezi pe care să le considerăm istorici și ne-a schimbat înțelegerea relației Londra-Northumberland. O discuție completă a constatărilor noastre poate fi citită în articolul original.18
ducându-vă cunoștințele înainte
după ce ați încercat această problemă de exemplu, ar trebui să aveți o înțelegere clară a modului de utilizare a acestei formule de exemplu, precum și dacă un model gravitațional ar putea fi sau nu o soluție adecvată pentru problema dvs. de cercetare. Aveți experiența și vocabularul pentru a aborda și discuta modelele gravitaționale cu un colaborator competent din punct de vedere matematic, dacă aveți nevoie, care vă poate ajuta să îl adaptați la propriul studiu de caz.
dacă sunteți suficient de norocoși să aveți și date despre migranții care se mută la sfârșitul secolului al XVIII-lea Londra și doriți să o modelați folosind aceleași cinci variabile enumerate mai sus, această formulă ar funcționa așa cum este – există un studiu ușor aici pentru cineva cu datele corecte. Cu toate acestea, acest model nu funcționează doar pentru studii despre migranții care se mută la Londra. Variabilele se pot schimba, iar destinația nu trebuie să fie Londra. Ar fi posibil să folosiți un model gravitațional pentru a studia migrația către Roma antică sau Bangkok din secolul XXI, dacă aveți datele și întrebarea de cercetare. Nici măcar nu trebuie să fie un model de migrație. Pentru a utiliza studiul de caz al cafelei columbiene din introducere, care se concentrează mai degrabă pe comerț decât pe migrație, Tabelul 6 arată o utilizare viabilă a aceleiași formule, nealterată.
| criterii | exemplu de export de cafea |
|---|---|
| un punct de origine | exporturile de cafea din portul Barranquilla, Columbia |
| destinații finite multiple | cele 21 de țări din emisfera vestică din 1950 |
| cinci variabile explicative | (1) Numărul de porturi din Oceanul Atlantic în țara primitoare (2) mile de Columbia, (3) Produsul Intern Brut al țării primitoare, (4) cafea domestică cultivată în tone, (5) cafenele la 10.000 de persoane |
există o lungă istorie a modelelor gravitaționale în Bursa academică. Pentru a utiliza unul eficient pentru cercetare, trebuie să înțelegeți teoria de bază și matematica din spatele lor și motivele pe care le-au dezvoltat așa cum au. De asemenea, este important să le înțelegem limitele și condițiile de utilizare corectă, dintre care unele au fost discutate mai sus. Ar putea ajuta, de asemenea, să știe:
-
un model gravitațional precum cel folosit în acest exemplu poate funcționa numai într-un sistem închis. Modelul de mai sus avea doar 32 de puncte de origine posibile, ceea ce face posibilă rularea modelului de 32 de ori. Un număr necunoscut sau infinit de mare de puncte de origine (sau destinații în funcție de modelul dvs.), ar necesita o ecuație diferită.
-
conceptul modelului gravitațional este, de asemenea, construit pe premisa că mișcările (migrație, comerț etc.) se bazează pe o colecție de decizii individuale voluntare care ar putea fi influențate de factori externi, dar nu sunt controlate în totalitate de aceștia. De exemplu, migrațiile voluntare sau achizițiile făcute din liberul arbitru ar putea fi modelate folosind această tehnică, dar migrația forțată, achiziția obligatorie sau procesele naturale, cum ar fi migrația păsărilor sau curgerea râurilor, pot să nu urmeze aceleași principii și, prin urmare, poate fi necesar un tip diferit de model.
-
modelele gravitaționale pot fi utilizate pentru a prezice comportamentul populațiilor, dar nu și al indivizilor și, prin urmare, încercările de modelare a datelor ar trebui să includă un număr mare de mișcări pentru a asigura semnificația statistică.
există multe alte capcane, dar și posibilități extraordinare. Sper că acest model de gravitație și cercetările sale publicate vor face acest instrument puternic mai accesibil pentru istorici. Dacă intenționați să utilizați un model gravitațional în cercetarea Dvs. științifică, autorul recomandă cu tărie următoarele articole:
mulțumiri
cu mulțumiri Angelei Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas și Leanne Calvert pentru citirea și comentarea proiectelor anterioare ale acestui articol. De asemenea, mulțumim Academiei Britanice pentru finanțarea atelierului de scriere din Bogot, Columbia, La care a fost elaborat acest articol. Și în cele din urmă lui Adam Dennett pentru că mi-a prezentat aceste formule minunate și le-a dezlănțuit potențialul pentru istorici.