ca un om de știință de date în industria de consum, ceea ce mă simt de obicei este, stimularea algoritmi sunt destul de suficient pentru cele mai multe dintre sarcinile de învățare predictive, cel puțin până acum. Sunt puternice, flexibile și pot fi interpretate frumos cu câteva trucuri. Astfel, cred că este necesar să citiți câteva materiale și să scrieți ceva despre algoritmii de stimulare.
cea mai mare parte a conținutului din acest acticle se bazează pe lucrarea: creșterea copacilor cu XGBoost: de ce câștigă XGBoost „fiecare” competiție de învățare automată?. Este o lucrare cu adevărat informativă. Aproape tot ceea ce privește algoritmii de stimulare este explicat foarte clar în lucrare. Deci, lucrarea conține 110 pagini: (
pentru mine, Mă voi concentra practic pe cei mai populari trei algoritmi de stimulare: AdaBoost, GBM și XGBoost. Am împărțit conținutul în două părți. Primul articol (acesta) se va concentra pe algoritmul AdaBoost, iar al doilea se va referi la comparația dintre GBM și XGBoost.
AdaBoost, prescurtarea de la „Adaptive Boosting”, este primul algoritm practic de stimulare propus de Freund și Schapire în 1996. Se concentrează pe problemele de clasificare și își propune să transforme un set de clasificatori slabi într-unul puternic. Ecuația finală pentru clasificare poate fi reprezentată ca
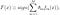
unde f_m reprezintă clasificatorul slab m_th și theta_m este greutatea corespunzătoare. Este exact combinația ponderată a clasificatorilor slabi M. Întreaga procedură a algoritmului AdaBoost poate fi rezumată după cum urmează.
algoritmul AdaBoost
dat unui set de date care conține N puncte, unde

aici -1 denotă clasa negativă, în timp ce 1 reprezintă cea pozitivă.
inițializați greutatea pentru fiecare punct de date ca:

pentru iterație m = 1,…, M:
(1) încadrați clasificatorii slabi la setul de date și selectați-l pe cel cu cea mai mică eroare de clasificare ponderată:

(2) calculați greutatea pentru clasificatorul slab m_th:

pentru orice clasificator cu o precizie mai mare de 50%, greutatea este pozitivă. Cu cât clasificatorul este mai precis, cu atât greutatea este mai mare. În timp ce pentru clasificator cu o precizie mai mică de 50%, greutatea este negativă. Înseamnă că îi combinăm predicția prin răsturnarea semnului. De exemplu, putem transforma un clasificator cu o precizie de 40% în precizie de 60% prin răsturnarea semnului predicției. Astfel, chiar clasificatorul se comportă mai rău decât ghicitul aleatoriu, contribuie în continuare la predicția finală. Nu dorim Niciun clasificator cu o precizie exactă de 50%, care nu adaugă nicio informație și, prin urmare, nu contribuie cu nimic la predicția finală.
(3) Actualizați greutatea pentru fiecare punct de date ca:

unde Z_m este un factor de normalizare care asigură că suma tuturor greutăților instanței este egală cu 1.
dacă un caz clasificat greșit provine dintr-un clasificator ponderat pozitiv, termenul „exp” din numărător ar fi întotdeauna mai mare de 1 (y*f este întotdeauna -1, theta_m este pozitiv). Astfel, cazurile clasificate greșit ar fi actualizate cu greutăți mai mari după o iterație. Aceeași logică se aplică clasificatorilor ponderați negativi. Singura diferență este că clasificările corecte originale ar deveni clasificări greșite după răsturnarea semnului.
după iterația M putem obține predicția finală prin însumarea predicției ponderate a fiecărui clasificator.
AdaBoost ca model de aditiv înainte în etape
această parte se bazează pe hârtie: regresie logistică aditivă: o viziune statistică a stimulării. Pentru informații mai detaliate, vă rugăm să consultați hârtia originală.
în 2000, Friedman și colab. a dezvoltat o viziune statistică a algoritmului AdaBoost. Ei au interpretat AdaBoost ca proceduri de estimare etapizată pentru montarea unui model de regresie logistică aditivă. Ei au arătat că AdaBoost minimizează de fapt funcția de pierdere exponențială

este minimizat la

deoarece pentru AdaBoost, y poate fi doar -1 sau 1, Funcția de pierdere poate fi rescrisă ca

continuați să rezolvați pentru F (x), obținem

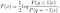
putem deduce în continuare modelul logistic normal din soluția optimă a F (x):

este aproape identic cu modelul de regresie logistică, în ciuda unui factor 2.
să presupunem că avem o estimare curentă a lui F(x) și să încercăm să căutăm o estimare îmbunătățită F(x)+cf(x). Pentru fix c și x, putem extinde L (y, F (x) + cf (x)) la a doua comandă despre f (x)=0,

astfel,

unde E_w(./ x) indică o așteptare condiționată ponderată și greutatea pentru fiecare punct de date este calculată ca

Dacă c > 0, minimizarea așteptărilor condiționale ponderate este egală cu maximizarea

deoarece y poate fi doar 1 sau -1, așteptarea ponderată poate fi rescrisă ca

soluția optimă vine ca

după determinarea f (x), greutatea c poate fi calculată prin minimizarea directă L (y, F(x) + cf (x)):

rezolvarea pentru c, obținem


fie epsilon egal cu suma ponderată a cazurilor clasificate greșit, atunci

rețineți că c poate fi negativ dacă elevul slab face mai rău decât presupunerea aleatorie (50%), în caz în care inversează automat polaritatea.
în ceea ce privește greutățile instanței, după adăugarea îmbunătățită, greutatea pentru o singură instanță devine,

astfel, greutatea instanței este actualizată ca

comparativ cu cele utilizate în algoritmul AdaBoost,

putem vedea că sunt în formă identică. Prin urmare, este rezonabil să interpretăm AdaBoost ca un model aditiv înainte în etape cu funcție de pierdere exponențială, care se potrivește iterativ unui clasificator slab pentru a îmbunătăți estimarea curentă la fiecare iterație m:
