Come scienziato dei dati nell’industria dei consumatori, quello che di solito sento è che gli algoritmi di potenziamento sono abbastanza per la maggior parte delle attività di apprendimento predittivo, almeno per ora. Sono potenti, flessibili e possono essere interpretati bene con alcuni trucchi. Quindi, penso che sia necessario leggere alcuni materiali e scrivere qualcosa sugli algoritmi di potenziamento.
La maggior parte del contenuto di questo articolo si basa sul documento: Tree Boosting With XGBoost: Perché XGBoost vince “ogni” competizione di apprendimento automatico?. Si tratta di un documento davvero informativo. Quasi tutto ciò che riguarda gli algoritmi di potenziamento è spiegato molto chiaramente nel documento. Quindi il documento contiene 110 pagine: (
Per me, mi concentrerò fondamentalmente sui tre algoritmi di potenziamento più popolari: AdaBoost, GBM e XGBoost. Ho diviso il contenuto in due parti. Il primo articolo (questo) si concentrerà sull’algoritmo AdaBoost e il secondo si rivolgerà al confronto tra GBM e XGBoost.
AdaBoost, abbreviazione di “Adaptive Boosting”, è il primo algoritmo di amplificazione pratico proposto da Freund e Schapire nel 1996. Si concentra sui problemi di classificazione e mira a convertire un insieme di classificatori deboli in uno forte. L’equazione finale per la classificazione può essere rappresentata come
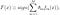
dove f_m sta per il classificatore debole m_th e theta_m è il peso corrispondente. È esattamente la combinazione ponderata di M classificatori deboli. L’intera procedura dell’algoritmo AdaBoost può essere riassunta come segue.
algoritmo AdaBoost
Dato un insieme di dati contenente n punti, dove

Qui -1 indica la classe negativa, mentre 1 rappresenta il positivo.
Inizializza il peso per ogni punto dati come:

Per l’iterazione m=1,…, M:
(1) Adatta i classificatori deboli al set di dati e seleziona quello con l’errore di classificazione ponderato più basso:

(2) Calcolare il peso per il m_th debole di classificazione:

Per qualsiasi classificatore con precisione superiore al 50%, il peso è di positivo. Più accurato è il classificatore, maggiore è il peso. Mentre per il classificatore con precisione inferiore al 50%, il peso è negativo. Significa che combiniamo la sua previsione lanciando il segno. Ad esempio, possiamo trasformare un classificatore con una precisione del 40% in una precisione del 60% lanciando il segno della previsione. Così anche il classificatore esegue peggio di indovinare casuale, contribuisce ancora alla previsione finale. Non vogliamo solo alcun classificatore con una precisione esatta del 50%, che non aggiunge alcuna informazione e quindi non contribuisce nulla alla previsione finale.
(3) Aggiornare il peso per ogni punto dati come:

dove Z_m è un fattore di normalizzazione che garantisce che la somma di tutti i pesi di istanza sia uguale a 1.
Se un caso classificato erroneamente proviene da un classificatore ponderato positivo, il termine “exp” nel numeratore sarebbe sempre maggiore di 1 (y*f è sempre -1, theta_m è positivo). Quindi i casi classificati erroneamente verrebbero aggiornati con pesi maggiori dopo un’iterazione. La stessa logica si applica ai classificatori ponderati negativi. L’unica differenza è che le classificazioni corrette originali diventerebbero errate dopo aver capovolto il segno.
Dopo M iterazione possiamo ottenere la previsione finale riassumendo la previsione ponderata di ciascun classificatore.
AdaBoost as a Forward Stagewise Additive Model
Questa parte è basata su paper: Additive logistic regression: a statistical view of boosting. Per informazioni più dettagliate, si prega di fare riferimento alla carta originale.
Nel 2000, Friedman et al. sviluppato una visione statistica dell’algoritmo AdaBoost. Hanno interpretato AdaBoost come procedure di stima a tappe per il montaggio di un modello di regressione logistica additiva. Essi hanno dimostrato che la AdaBoost era in realtà riducendo al minimo la perdita di funzione esponenziale

ridotta a

Dal momento che per AdaBoost, y può essere solo -1 o 1, la perdita di funzione può essere riscritta come

Continuare a risolvere per F(x), otteniamo

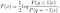
Possiamo inoltre derivare il normale modello logistico dalla soluzione ottimale di F (x):

È quasi identico al modello di regressione logistica nonostante un fattore 2.
Supponiamo di avere una stima corrente di F(x) e provare a cercare una stima migliorata F(x)+cf (x). Per fisso c e x, si può espandere L(y, F(x)+cf(x)) al secondo ordine di f(x)=0,

Così,

dove E_w(.|x) indica una ponderata condizionato e il peso di ciascun punto di dati è calcolato come

Se c > 0, riducendo al minimo ponderato di aspettativa condizionale è uguale per massimizzare

Dal momento che y può essere solo 1 o -1, ponderato di aspettativa può essere riscritta come

La soluzione ottimale si presenta come

Dopo aver determinato f (x), il peso c può essere calcolato minimizzando direttamente L(y, F(x) + cf(x)):

la Risoluzione per c, si ottiene


Lasciate epsilon, pari alla somma ponderata di classificazione di casi, quindi

Nota che c può essere negativo se l’debole studente non peggiore ipotesi casuale (50%), in nel qual caso inverte automaticamente la polarità.
In termini di istanza di pesi, dopo il miglioramento, inoltre, il peso di una singola istanza diventa,

Pertanto, l’istanza di peso è aggiornato

Rispetto a quelli utilizzati nell’algoritmo AdaBoost,

si può vedere che sono nella identica forma. Pertanto, è ragionevole interpretare AdaBoost come un modello additivo a stadi avanzati con funzione di perdita esponenziale, che si adatta iterativamente a un classificatore debole per migliorare la stima corrente ad ogni iterazione m:
