Ultimo aggiornamento il 7 agosto 2019
Gli incorporamenti di parole sono un tipo di rappresentazione di parole che consente a parole con significato simile di avere una rappresentazione simile.
Sono una rappresentazione distribuita per il testo che è forse una delle innovazioni chiave per le impressionanti prestazioni dei metodi di apprendimento profondo su impegnativi problemi di elaborazione del linguaggio naturale.
In questo post, scoprirai l’approccio di incorporamento di parole per rappresentare i dati di testo.
Dopo aver completato questo post, saprai:
- Qual è l’approccio di incorporamento della parola per rappresentare il testo e come si differenzia dagli altri metodi di estrazione delle funzionalità.
- Che ci sono 3 algoritmi principali per imparare un embedding di parole da dati di testo.
- Che è possibile addestrare un nuovo embedding o utilizzare un embedding pre-addestrato sull’attività di elaborazione del linguaggio naturale.
Avvia il tuo progetto con il mio nuovo libro Deep Learning per l’elaborazione del linguaggio naturale, inclusi tutorial passo-passo e file di codice sorgente Python per tutti gli esempi.
Iniziamo.

Cosa sono gli embedding di parole per il testo?
Foto di Heather, alcuni diritti riservati.
- Panoramica
- Hai bisogno di aiuto con Deep Learning per i dati di testo?
- Cosa sono gli embeddings di parole?
- Algoritmi di incorporamento di parole
- Livello di incorporamento
- Word2Vec
- Guanto
- Utilizzo di Word Embeddings
- Impara un Embedding
- Riutilizzare un Embedding
- Quale opzione si dovrebbe usare?
- Word Embedding Tutorials
- Ulteriori letture
- Articoli
- Papers
- Progetti
- Libri
- Riepilogo
- Sviluppare modelli di apprendimento profondo per i dati di testo oggi!
- Sviluppa i tuoi modelli di testo in pochi minuti
- Finalmente porta l’apprendimento profondo ai tuoi progetti di elaborazione del linguaggio naturale
Panoramica
Questo post è diviso in 3 parti; sono:
- Cosa sono gli embeddings di parole?
- Algoritmi di incorporamento di parole
- Utilizzo di incorporamenti di parole
Hai bisogno di aiuto con Deep Learning per i dati di testo?
Prendi il mio corso accelerato gratuito di 7 giorni (con codice).
Fare clic per iscriversi e ottenere anche una versione PDF Ebook gratuita del corso.
Inizia il tuo Crash-course GRATUITO ora
Cosa sono gli embeddings di parole?
Un embedding di parole è una rappresentazione appresa per il testo in cui le parole che hanno lo stesso significato hanno una rappresentazione simile.
È questo approccio alla rappresentazione di parole e documenti che può essere considerato una delle scoperte chiave dell’apprendimento profondo sui problemi di elaborazione del linguaggio naturale.
Uno dei vantaggi dell’utilizzo di vettori densi e a bassa dimensione è computazionale: la maggior parte dei toolkit di rete neurale non gioca bene con vettori radi di dimensioni molto elevate. … Il vantaggio principale delle rappresentazioni dense è il potere di generalizzazione: se crediamo che alcune caratteristiche possano fornire indizi simili, vale la pena fornire una rappresentazione che sia in grado di catturare queste somiglianze.
— Pagina 92, Metodi di rete neurale nell’elaborazione del linguaggio naturale, 2017.
Gli incorporamenti di parole sono infatti una classe di tecniche in cui le singole parole sono rappresentate come vettori a valore reale in uno spazio vettoriale predefinito. Ogni parola è mappata su un vettore e i valori del vettore vengono appresi in un modo simile a una rete neurale, e quindi la tecnica è spesso concentrata nel campo dell’apprendimento profondo.
La chiave dell’approccio è l’idea di utilizzare una rappresentazione distribuita densa per ogni parola.
Ogni parola è rappresentata da un vettore a valori reali, spesso decine o centinaia di dimensioni. Questo è in contrasto con le migliaia o milioni di dimensioni richieste per rappresentazioni di parole sparse, come una codifica one-hot.
associa a ogni parola nel vocabolario un vettore di funzionalità di parola distribuito-Il vettore di funzionalità rappresenta diversi aspetti della parola: ogni parola è associata a un punto in uno spazio vettoriale. Il numero di funzioni … è molto più piccolo della dimensione del vocabolario
— A Neural Probabilistic Language Model, 2003.
La rappresentazione distribuita viene appresa in base all’uso delle parole. Ciò consente alle parole che vengono utilizzate in modi simili di ottenere rappresentazioni simili, catturando naturalmente il loro significato. Questo può essere contrastato con la rappresentazione nitida ma fragile in un modello bag of words in cui, a meno che non venga gestito esplicitamente, parole diverse hanno rappresentazioni diverse, indipendentemente da come vengono utilizzate.
C’è una teoria linguistica più profonda dietro l’approccio, vale a dire l ‘ “ipotesi distributiva” di Zellig Harris che potrebbe essere riassunta come: parole che hanno un contesto simile avranno significati simili. Per una maggiore profondità vedere Harris ‘1956 carta ” Distributional structure”.
Questa nozione di lasciare che l’uso della parola definisca il suo significato può essere riassunta da una battuta ripetuta spesso da John Firth:
Saprete una parola dalla società che mantiene!
— Pagina 11, “A synopsis of linguistic theory 1930-1955”, in Studies in Linguistic Analysis 1930-1955, 1962.
Algoritmi di incorporamento di parole
Metodi di incorporamento di parole impara una rappresentazione vettoriale a valore reale per un vocabolario di dimensioni fisse predefinito da un corpus di testo.
Il processo di apprendimento è congiunto con il modello di rete neurale su alcune attività, come la classificazione dei documenti, o è un processo non supervisionato, utilizzando le statistiche dei documenti.
Questa sezione esamina tre tecniche che possono essere utilizzate per imparare l’incorporamento di una parola dai dati di testo.
Livello di incorporamento
Un livello di incorporamento, per mancanza di un nome migliore, è un embedding di parole che viene appreso congiuntamente a un modello di rete neurale su una specifica attività di elaborazione del linguaggio naturale, come la modellazione del linguaggio o la classificazione dei documenti.
Richiede che il testo del documento sia pulito e preparato in modo tale che ogni parola sia codificata a caldo. La dimensione dello spazio vettoriale viene specificata come parte del modello, ad esempio 50, 100 o 300 dimensioni. I vettori sono inizializzati con piccoli numeri casuali. Il livello di incorporamento viene utilizzato sul front-end di una rete neurale e si adatta in modo supervisionato utilizzando l’algoritmo Backpropagation.
… quando l’input di una rete neurale contiene caratteristiche categoriali simboliche (ad es. caratteristiche che prendono uno dei simboli k distinti, come le parole da un vocabolario chiuso), è comune associare ogni possibile valore di caratteristica (cioè ogni parola nel vocabolario) con un vettore d-dimensionale per alcuni d. Questi vettori sono quindi considerati parametri del modello e sono addestrati congiuntamente agli altri parametri.
— Pagina 49, Metodi di rete neurale nell’elaborazione del linguaggio naturale, 2017.
Le parole codificate a caldo vengono mappate ai vettori di parole. Se viene utilizzato un modello Perceptron multistrato, i vettori di parole vengono concatenati prima di essere alimentati come input al modello. Se viene utilizzata una rete neurale ricorrente, ogni parola può essere presa come un input in una sequenza.
Questo approccio di apprendimento di un livello di incorporamento richiede molti dati di allenamento e può essere lento, ma imparerà un incorporamento mirato sia ai dati di testo specifici che all’attività NLP.
Word2Vec
Word2Vec è un metodo statistico per imparare in modo efficiente un embedding di parole standalone da un corpus di testo.
È stato sviluppato da Tomas Mikolov, et al. a Google nel 2013 come risposta per rendere la formazione neurale-network-based del embedding più efficiente e da allora è diventato lo standard de facto per lo sviluppo di pre-addestrati parola embedding.
Inoltre, il lavoro ha coinvolto l’analisi dei vettori appresi e l’esplorazione della matematica vettoriale sulle rappresentazioni delle parole. Per esempio, che sottraendo il “uomo-ness” da ” Re “e aggiungendo” donne-ness “risultati nella parola” Regina”, catturando l’analogia”re è alla regina come l’uomo è alla donna”.
Troviamo che queste rappresentazioni sono sorprendentemente buone nel catturare le regolarità sintattiche e semantiche nel linguaggio e che ogni relazione è caratterizzata da un offset vettoriale specifico della relazione. Ciò consente un ragionamento orientato al vettore basato sugli offset tra le parole. Ad esempio, la relazione maschio/femmina viene appresa automaticamente e, con le rappresentazioni vettoriali indotte, “King – Man + Woman” si traduce in un vettore molto vicino a “Queen.”
— Regolarità linguistiche in Continuous Space Word Representations, 2013.
Sono stati introdotti due diversi modelli di apprendimento che possono essere utilizzati come parte dell’approccio word2vec per imparare l’incorporamento della parola; sono:
- Borsa continua di parole, o modello CBOW.
- Continuo Skip-Gram Modello.
Il modello CBOW apprende l’incorporamento prevedendo la parola corrente in base al suo contesto. Il modello skip-gram continuo impara prevedendo le parole circostanti date una parola corrente.
Il modello skip-gram continuo impara prevedendo le parole circostanti date una parola corrente.
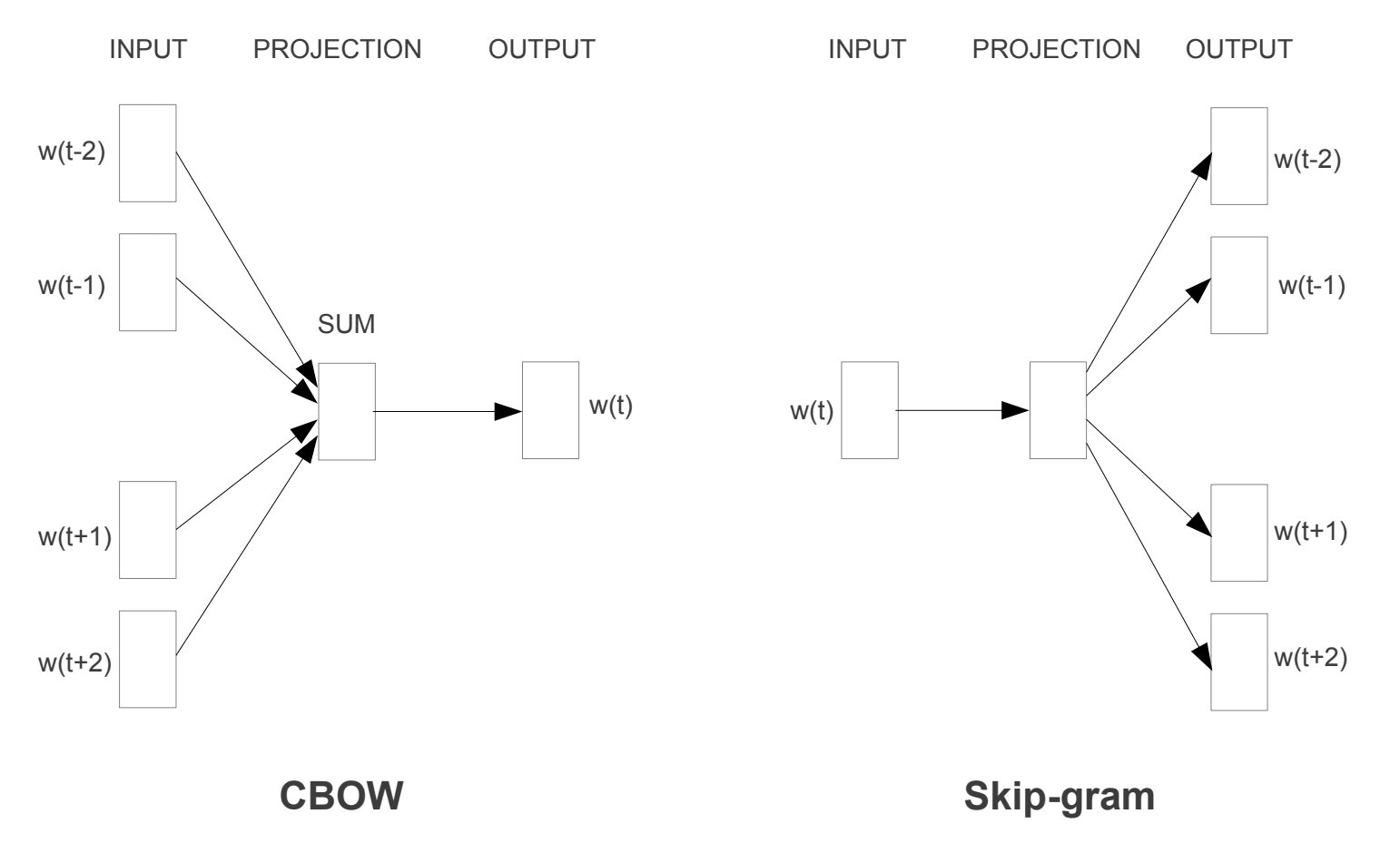
Word2Vec Training Models
Tratto da “Efficient Estimation of Word Representations in Vector Space”, 2013
Entrambi i modelli sono focalizzati sull’apprendimento delle parole dato il loro contesto di utilizzo locale, in cui il contesto è definito da una finestra di parole vicine. Questa finestra è un parametro configurabile del modello.
La dimensione della finestra scorrevole ha un forte effetto sulle somiglianze vettoriali risultanti. Le grandi finestre tendono a produrre somiglianze più attuali, mentre le finestre più piccole tendono a produrre somiglianze più funzionali e sintattiche.
— Pagina 128, Metodi di rete neurale nell’elaborazione del linguaggio naturale, 2017.
Il vantaggio chiave dell’approccio è che gli embeddings di parole di alta qualità possono essere appresi in modo efficiente (bassa complessità di spazio e tempo), consentendo di apprendere embeddings più grandi (più dimensioni) da corpora di testo molto più grandi (miliardi di parole).
Guanto
I vettori globali per la rappresentazione delle parole, o guanto, l’algoritmo è un’estensione del metodo word2vec per l’apprendimento efficiente dei vettori di parole, sviluppato da Pennington, et al. a Stanford.
Le rappresentazioni classiche del modello di spazio vettoriale delle parole sono state sviluppate utilizzando tecniche di fattorizzazione della matrice come l’analisi semantica latente (LSA) che fanno un buon lavoro nell’utilizzare statistiche di testo globali ma non sono buone come i metodi appresi come word2vec per catturare il significato e dimostrarlo su compiti come il calcolo delle analogie il re e la regina esempio sopra).
GloVe è un approccio per sposare sia le statistiche globali delle tecniche di fattorizzazione della matrice come LSA con l’apprendimento locale basato sul contesto in word2vec.
Invece di utilizzare una finestra per definire il contesto locale, GloVe costruisce una matrice esplicita di parole-contesto o di co-occorrenza di parole utilizzando le statistiche sull’intero corpus di testo. Il risultato è un modello di apprendimento che può portare a incorporamenti di parole generalmente migliori.
GloVe, è un nuovo modello di regressione log-bilineare globale per l’apprendimento non supervisionato delle rappresentazioni di parole che supera altri modelli sull’analogia di parole, sulla somiglianza di parole e sulle attività di riconoscimento di entità denominate.
— Guanto: vettori globali per la rappresentazione delle parole, 2014.
Utilizzo di Word Embeddings
Hai alcune opzioni quando arriva il momento di utilizzare word embeddings sul tuo progetto di elaborazione del linguaggio naturale.
Questa sezione descrive queste opzioni.
Impara un Embedding
Puoi scegliere di imparare un embedding di parole per il tuo problema.
Ciò richiederà una grande quantità di dati di testo per garantire che vengano appresi utili embeddings, come milioni o miliardi di parole.
Hai due opzioni principali quando alleni il tuo embedding di parole:
- Learn it Standalone, dove un modello viene addestrato per imparare l’incorporamento, che viene salvato e utilizzato come parte di un altro modello per l’attività successiva. Questo è un buon approccio se si desidera utilizzare lo stesso incorporamento in più modelli.
- Impara congiuntamente, dove l’incorporamento viene appreso come parte di un modello specifico per attività di grandi dimensioni. Questo è un buon approccio se si intende utilizzare l’incorporamento solo su un’attività.
Riutilizzare un Embedding
È comune per i ricercatori rendere disponibili gratuitamente embeddings di parole pre-addestrati, spesso sotto una licenza permissiva in modo da poterli utilizzare sui propri progetti accademici o commerciali.
Ad esempio, sia word2vec che Glove word embeddings sono disponibili per il download gratuito.
Questi possono essere utilizzati sul tuo progetto invece di addestrare i tuoi embeddings da zero.
Hai due opzioni principali quando si tratta di utilizzare incorporamenti pre-addestrati:
- Statico, dove l’incorporamento è mantenuto statico e viene utilizzato come componente del modello. Questo è un approccio adatto se l’incorporamento è adatto al tuo problema e dà buoni risultati.
- Aggiornato, in cui l’incorporamento pre-addestrato viene utilizzato per seminare il modello, ma l’incorporamento viene aggiornato congiuntamente durante l’addestramento del modello. Questa potrebbe essere una buona opzione se stai cercando di ottenere il massimo dal modello e incorporare il tuo compito.
Quale opzione si dovrebbe usare?
Esplora le diverse opzioni e, se possibile, prova per vedere quale dà i migliori risultati sul tuo problema.
Forse iniziare con metodi veloci, come l’utilizzo di un embedding pre-addestrato, e utilizzare solo un nuovo embedding se si traduce in prestazioni migliori sul problema.
Word Embedding Tutorials
Questa sezione elenca alcuni tutorial passo-passo che puoi seguire per utilizzare word embeddings e portare word embedding al tuo progetto.
- Come sviluppare Word Embeddings in Python con Gensim
- Come utilizzare Word Embedding Layers per Deep Learning con Keras
- Come sviluppare una CNN profonda per Sentiment Analysis (Classificazione del testo)
Ulteriori letture
Questa sezione fornisce più risorse sull’argomento se stai cercando di approfondire.
Articoli
- Incorporamento di parole su Wikipedia
- Word2vec su Wikipedia
- Guanto su Wikipedia
- Una panoramica degli incorporamenti di parole e della loro connessione ai modelli semantici distributivi, 2016.
- Apprendimento profondo, PNL e rappresentazioni, 2014.
Papers
- Struttura distributiva, 1956.
- Un modello di linguaggio probabilistico neurale, 2003.
- Un’architettura unificata per l’elaborazione del linguaggio naturale: reti neurali profonde con apprendimento multitask, 2008.
- Continuous space language models, 2007.
- Stima efficiente delle rappresentazioni di parole nello spazio vettoriale, 2013
- Rappresentazioni distribuite di parole e frasi e loro composizionalità, 2013.
- Guanto: vettori globali per la rappresentazione delle parole, 2014.
Progetti
- word2vec su Google Code
- Guanto: vettori globali per la rappresentazione delle parole
Libri
- Metodi di rete neurale nell’elaborazione del linguaggio naturale, 2017.
Riepilogo
In questo post, hai scoperto gli incorporamenti di parole come metodo di rappresentazione per il testo nelle applicazioni di deep learning.
In particolare, hai imparato:
- Qual è l’approccio di incorporamento della parola per il testo di rappresentazione e come si differenzia dagli altri metodi di estrazione delle funzionalità.
- Che ci sono 3 algoritmi principali per imparare un embedding di parole da dati di testo.
- Che puoi addestrare un nuovo embedding o utilizzare un embedding pre-addestrato nella tua attività di elaborazione del linguaggio naturale.
Avete domande?
Fai le tue domande nei commenti qui sotto e farò del mio meglio per rispondere.
Sviluppare modelli di apprendimento profondo per i dati di testo oggi!

Sviluppa i tuoi modelli di testo in pochi minuti
…con poche righe di codice python
Scopri come nel mio nuovo Ebook:
Deep Learning per l’elaborazione del linguaggio naturale
Fornisce tutorial di autoapprendimento su argomenti come:
Bag-of-Words, Word Embedding, Modelli linguistici, Generazione di didascalie, traduzione del testo e molto altro…
Finalmente porta l’apprendimento profondo ai tuoi progetti di elaborazione del linguaggio naturale
Salta gli accademici. Solo risultati.
Vedere cosa c’è dentro