en blid introduktion til Auto-Encoder og nogle af dens almindelige brugssager med Python-kode
baggrund:
Autoencoder er et ikke-overvåget kunstigt neuralt netværk, der lærer, hvordan man effektivt komprimerer og koder data, lærer derefter, hvordan man rekonstruerer dataene tilbage fra den reducerede kodede repræsentation til en repræsentation, der er så tæt på den originale indgang som muligt.
Autoencoder reducerer ved design datadimensioner ved at lære at ignorere støj i dataene.
her er et eksempel på input/output-billedet fra MNIST-datasættet til en autoencoder.
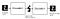
Autoencoder komponenter:
Autoencoders består af 4 hoveddele:
1 – Encoder: hvor modellen lærer at reducere input dimensioner og komprimere input data til en kodet repræsentation.
2-flaskehals: hvilket er det lag, der indeholder den komprimerede repræsentation af inputdataene. Dette er de lavest mulige dimensioner af inputdataene.
3 – dekoder: hvor modellen lærer at rekonstruere dataene fra den kodede repræsentation for at være så tæt på den oprindelige input som muligt.
4 – Rekonstruktionstab: dette er den metode, der måler, hvor godt dekoderen fungerer, og hvor tæt output er på den originale indgang.
træningen involverer derefter brug af bagudbredelse for at minimere netværkets genopbygningstab.
du skal undre dig over, hvorfor skulle jeg træne et neuralt netværk bare for at udsende et billede eller data, der er nøjagtigt det samme som input! Denne artikel dækker de mest almindelige brugssager til Autoencoder. Lad os komme i gang:
Autoencoder-arkitektur:
netværksarkitekturen for autoencodere kan variere mellem et simpelt fremadgående netværk, LSTM-netværk eller indviklet neuralt netværk afhængigt af brugssagen. Vi vil udforske nogle af disse arkitekturer i de nye næste par linjer.
der er mange måder og teknikker til at opdage anomalier og outliers. Jeg har dækket dette emne i et andet indlæg nedenfor:
men hvis du har korreleret inputdata, vil autoencoder-metoden fungere meget godt, fordi kodningsoperationen er afhængig af de korrelerede funktioner til at komprimere dataene.
lad os sige, at vi har trænet en autoencoder på MNIST-datasættet. Ved hjælp af et simpelt fremadgående neuralt netværk kan vi opnå dette ved at opbygge et simpelt 6 lag netværk som nedenfor:
udgangen af koden ovenfor er:
som du kan se i output, er det sidste rekonstruktionstab/fejl for valideringssættet 0.0193, hvilket er fantastisk. Hvis jeg nu sender et normalt billede fra MNIST-datasættet, vil genopbygningstabet være meget lavt (< 0.02), men hvis jeg forsøgte at videregive et andet andet billede (outlier eller anomali), får vi en høj genopbygningstabsværdi, fordi netværket ikke kunne rekonstruere det billede/input, der betragtes som en anomali.
Bemærk I koden ovenfor kan du kun bruge koderdelen til at komprimere nogle data eller billeder, og du kan også kun bruge dekoderdelen til at dekomprimere dataene ved at indlæse dekoderlagene.
nu, lad os gøre nogle anomali afsløring. Koden nedenfor bruger to forskellige billeder til at forudsige anomali score (rekonstruktionsfejl) ved hjælp af autoencoder-netværket, vi trænede ovenfor. det første billede er fra MNIST og resultatet er 5.43209. Det betyder, at billedet ikke er en anomali. Det andet billede, jeg brugte, er et helt tilfældigt billede, der ikke hører til træningsdatasættet, og resultaterne var: 6789.4907. Denne høje fejl betyder, at billedet er en anomali. Det samme koncept gælder for enhver type datasæt.