som dataforsker i forbrugerindustrien er det, jeg normalt føler, at boosting af algoritmer er helt nok til de fleste af de forudsigelige læringsopgaver, i det mindste nu. De er kraftfulde, fleksible og kan fortolkes pænt med nogle tricks. Dermed, Jeg synes, det er nødvendigt at læse igennem nogle materialer og skrive noget om de boostende algoritmer.
det meste af indholdet i denne acticle er baseret på papiret: Træforstærkning med Hgboost: hvorfor vinder Hgboost “hver” Maskinlæringskonkurrence?. Det er et virkelig informativt papir. Næsten alt hvad angår boosting af algoritmer forklares meget tydeligt i papiret. Så papiret indeholder 110 sider: (
for mig vil jeg dybest set fokusere på de tre mest populære boostingalgoritmer: AdaBoost, GBM og Hgboost. Jeg har delt indholdet i to dele. Den første artikel (denne) vil fokusere på AdaBoost-algoritmen, og den anden vil henvende sig til sammenligningen mellem GBM og Hgboost.
AdaBoost, forkortelse for “Adaptive Boosting”, er den første praktiske boostingsalgoritme foreslået af Freund og Schapire i 1996. Det fokuserer på klassificeringsproblemer og sigter mod at konvertere et sæt svage klassifikatorer til et stærkt. Den endelige ligning for klassificering kan repræsenteres som
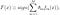
hvor f_m står for m_th svag klassifikator og theta_m er den tilsvarende vægt. Det er nøjagtigt den vægtede kombination af M svage klassifikatorer. Hele proceduren i AdaBoost-algoritmen kan opsummeres som følger.
AdaBoost algoritme
givet et datasæt indeholdende n-punkter, hvor

her betegner -1 den negative klasse, mens 1 repræsenterer den positive.
Initialiser vægten for hvert datapunkt som:

til iteration m=1,…, M:
(1) Tilpas svage klassifikatorer til datasættet, og vælg den med den lavest vægtede klassificeringsfejl:

(2) Beregn vægten for m_th svag klassifikator:

for enhver klassifikator med nøjagtighed højere end 50% er vægten positiv. Jo mere præcis klassifikatoren er, desto større er vægten. Mens for klassiferen med mindre end 50% nøjagtighed er vægten negativ. Det betyder, at vi kombinerer dens forudsigelse ved at vende tegnet. For eksempel kan vi omdanne en klassifikator med 40% nøjagtighed til 60% nøjagtighed ved at vende tegn på forudsigelsen. Selv klassifikatoren klarer sig således dårligere end tilfældig gætte, det bidrager stadig til den endelige forudsigelse. Vi ønsker kun ikke nogen klassifikator med nøjagtig 50% nøjagtighed, som ikke tilføjer nogen information og dermed ikke bidrager til den endelige forudsigelse.
(3) Opdater vægten for hvert datapunkt som:

hvor S_m er en normaliseringsfaktor, der sikrer, at summen af alle instansvægte er lig med 1.
hvis en forkert klassificeret sag er fra en positiv vægtet klassifikator, vil udtrykket” eksp ” i tælleren altid være større end 1 (y*f er altid -1, theta_m er positiv). Således ville misklassificerede sager blive opdateret med større vægte efter en iteration. Den samme logik gælder for de negative vægtede klassifikatorer. Den eneste forskel er, at de oprindelige korrekte klassifikationer ville blive fejlklassifikationer efter at have vendt tegnet.
efter M iteration kan vi få den endelige Forudsigelse ved at opsummere den vægtede forudsigelse af hver klassifikator.
AdaBoost som en fremadrettet trinvis Additivmodel
denne del er baseret på papir: additiv logistisk regression: et statistisk billede af boosting. For mere detaljerede oplysninger henvises til det originale papir.
i 2000 Friedman et al. udviklet et statistisk billede af AdaBoost-algoritmen. De fortolkede AdaBoost som trinvis estimeringsprocedurer til montering af en additiv logistisk regressionsmodel. De viste, at AdaBoost faktisk minimerede den eksponentielle tabsfunktion

det minimeres ved

siden for AdaBoost kan y kun være -1 eller 1, tabsfunktionen kan omskrives som

fortsæt med at løse for F (H), vi får

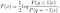
vi kan yderligere udlede den normale logistiske model fra den optimale løsning af F):

det er næsten identisk med den logistiske regressionsmodel på trods af en faktor 2.
Antag, at vi har et aktuelt estimat på F(H) og forsøger at søge et forbedret estimat F(H)+cf(h). For fast c og H kan vi udvide L (y, F(H)+cf (h)) til anden rækkefølge om f (H)=0,

således,

hvor E_v(.angiver en vægtet betinget forventning, og vægten for hvert datapunkt beregnes som

Hvis c > 0, er minimering af den vægtede betingede forventning lig med maksimering

da y kun kan være 1 eller -1, kan den vægtede forventning omskrives som

den optimale løsning kommer som

efter bestemmelse af F(H) kan vægten C beregnes ved direkte at minimere L(y, F(H)+cf(h)):

løsning for c, vi får


lad epsilon være lig med den vægtede sum af misklassificerede sager, derefter

Bemærk, at c kan være negativ, hvis den svage elev gør værre end tilfældigt gæt (50%), i hvilket tilfælde det automatisk vender polariteten.
med hensyn til instansvægte bliver vægten for en enkelt instans efter den forbedrede tilføjelse,

således opdateres instansvægten som

sammenlignet med dem, der anvendes i AdaBoost algoritme,

vi kan se, at de er i identisk form. Derfor, det er rimeligt at fortolke AdaBoost som en fremadrettet trinvis additivmodel med eksponentielt tabsfunktion, som iterativt passer til en svag klassifikator for at forbedre det aktuelle skøn ved hver iteration m:
