ordindlejringer er en type ordrepræsentation, der gør det muligt for ord med lignende betydning at have en lignende repræsentation.
de er en distribueret repræsentation for tekst, der måske er et af de vigtigste gennembrud for den imponerende udførelse af dybe læringsmetoder på udfordrende naturlige sprogbehandlingsproblemer.
i dette indlæg vil du opdage ordet indlejring tilgang til at repræsentere tekstdata.
efter at have afsluttet dette indlæg, vil du vide:
- hvad ordet indlejring tilgang til at repræsentere tekst er, og hvordan det adskiller sig fra andre funktion udvinding metoder.
- at der er 3 hovedalgoritmer til at lære et ordindlejring fra tekstdata.
- at du enten kan træne en ny indlejring eller bruge en forududdannet indlejring på din naturlige sprogbehandlingsopgave.
kickstarte dit projekt med min nye bog Deep Learning For Natural Language Processing, herunder trin-for-trin tutorials og Python kildekode filer for alle eksempler.
lad os komme i gang.

Hvad er Ordindlejringer til tekst?
foto af Heather, nogle rettigheder forbeholdes.
- oversigt
- brug for hjælp til dyb læring til tekstdata?
- Hvad er Ordindlejringer?
- ord indlejring algoritmer
- Indlejringslag
- Ord2vec
- handske
- brug af Ordindlejringer
- Lær en indlejring
- Genbrug en indlejring
- Hvilken Mulighed Skal Du Bruge?
- Tutorials til Ordindlejring
- yderligere læsning
- artikler
- papirer
- projekter
- bøger
- Resume
- udvikle dybe læringsmodeller til tekstdata i dag!
- udvikle dine egne Tekstmodeller på få minutter
- endelig bringe dyb læring til dine naturlige Sprogbehandlingsprojekter
oversigt
dette indlæg er opdelt i 3 dele; de er:
- Hvad er ord Embeddings?
- Ordindlejringsalgoritmer
- brug af Ordindlejringer
brug for hjælp til dyb læring til tekstdata?
Tag mit gratis 7-dages e-mail-crashkursus nu (med kode).
Klik for at tilmelde dig og få også en gratis PDF Ebook version af kurset.
Start dit gratis Crash-kursus nu
Hvad er Ordindlejringer?
en ordindlejring er en lært repræsentation for tekst, hvor ord, der har samme betydning, har en lignende repræsentation.
det er denne tilgang til at repræsentere ord og dokumenter, der kan betragtes som et af de vigtigste gennembrud i dyb læring om udfordrende problemer med naturlig sprogbehandling.
en af fordelene ved at bruge tætte og lavdimensionelle vektorer er beregningsmæssige: størstedelen af neurale netværks værktøjssæt spiller ikke godt med meget højdimensionelle, sparsomme vektorer. … Den største fordel ved de tætte repræsentationer er generaliseringskraft: hvis vi mener, at nogle funktioner kan give lignende spor, er det værd at give en repræsentation, der er i stand til at fange disse ligheder.
— side 92, neurale Netværksmetoder i naturlig sprogbehandling, 2017.
ordindlejringer er faktisk en klasse af teknikker, hvor individuelle ord er repræsenteret som reelle vektorer i et foruddefineret vektorrum. Hvert ord er kortlagt til en vektor, og vektorværdierne læres på en måde, der ligner et neuralt netværk, og derfor er teknikken ofte klumpet ind i området for dyb læring.
nøglen til tilgangen er ideen om at bruge en tæt distribueret repræsentation for hvert ord.
hvert ord er repræsenteret af en reel værdi vektor, ofte tiere eller hundredvis af dimensioner. Dette står i modsætning til de tusinder eller millioner af dimensioner, der kræves til sparsomme ordrepræsentationer, såsom en one-hot-kodning.
associer med hvert ord i ordforrådet en distribueret ordfunktionsvektor … funktionsvektoren repræsenterer forskellige aspekter af ordet: hvert ord er forbundet med et punkt i et vektorrum. Antallet af funktioner … er meget mindre end ordforrådets størrelse
— en Neural probabilistisk sprogmodel, 2003.
den distribuerede repræsentation læres ud fra brugen af ord. Dette gør det muligt for ord, der bruges på lignende måder, at resultere i at have lignende repræsentationer, der naturligt fanger deres betydning. Dette kan stå i kontrast til den sprøde, men skrøbelige repræsentation i en pose med ordmodel, hvor forskellige ord, medmindre det udtrykkeligt styres, har forskellige repræsentationer, uanset hvordan de bruges.
der er dybere Sproglig teori bag tilgangen, nemlig” fordelingshypotesen ” af Sellig Harris, der kunne opsummeres som: ord, der har lignende kontekst, vil have lignende betydninger. For mere dybde se Harris ‘1956 papir”distributionsstruktur”.
denne forestilling om at lade brugen af ordet definere dets betydning kan opsummeres ved en ofte gentaget spydighed af John Firth:
du skal kende et ord af det firma, det holder!
— side 11,” en synopsis af sproglig teori 1930-1955″, i studier i sproglig analyse 1930-1955, 1962.
ord indlejring algoritmer
ord indlejring metoder lær en real-værdsat vektor repræsentation for en foruddefineret fast størrelse ordforråd fra et korpus af tekst.
læringsprocessen er enten fælles med den neurale netværksmodel på en eller anden opgave, såsom dokumentklassificering, eller er en proces uden tilsyn ved hjælp af dokumentstatistikker.
dette afsnit gennemgår tre teknikker, der kan bruges til at lære et ord indlejring fra tekstdata.
Indlejringslag
et indlejringslag, i mangel af et bedre navn, er en ordindlejring, der læres sammen med en neuralt netværksmodel på en bestemt naturlig sprogbehandlingsopgave, såsom sprogmodellering eller dokumentklassificering.
det kræver, at dokumentteksten renses og fremstilles således, at hvert ord er one-hot kodet. Størrelsen af vektorrummet er angivet som en del af modellen, såsom 50, 100 eller 300 dimensioner. Vektorerne initialiseres med små tilfældige tal. Indlejringslaget bruges i forenden af et neuralt netværk og passer på en overvåget måde ved hjælp af Backpropagationsalgoritmen.
… når input til et neuralt netværk indeholder symbolske kategoriske funktioner (f. eks. funktioner, der tager et af k forskellige symboler, såsom ord fra et lukket ordforråd), er det almindeligt at knytte hver mulig funktionsværdi (dvs. hvert ord i ordforrådet) til en D-dimensionel vektor for nogle d.disse vektorer betragtes derefter som parametre for modellen og trænes sammen med de andre parametre.
— side 49, neurale Netværksmetoder i naturlig sprogbehandling, 2017.
de en-hot kodede ord er kortlagt til ordet vektorer. Hvis der anvendes en flerlags Perceptronmodel, sammenkædes ordvektorerne, før de føres som input til modellen. Hvis der anvendes et tilbagevendende neuralt netværk, kan hvert ord tages som et input i en sekvens.
denne tilgang til at lære et indlejringslag kræver en masse træningsdata og kan være langsom, men vil lære en indlejring både målrettet mod de specifikke tekstdata og NLP-opgaven.
Ord2vec
Ord2vec er en statistisk metode til effektivt at lære en standalone ord indlejring fra en tekst corpus.
det blev udviklet af Tomas Mikolov, et al. på Google i 2013 som et svar på at gøre den neurale netværksbaserede træning af indlejringen mere effektiv og siden da er blevet de facto-standarden for udvikling af forududdannet ordindlejring.
derudover involverede arbejdet analyse af de lærte vektorer og udforskning af vektormatematik på repræsentationer af ord. For eksempel, at trække “mand-ness” fra “Konge” og tilføje “kvinder-ness” resulterer i ordet “Dronning”, fange analogien “konge er til dronning som mand er til kvinde”.
vi finder ud af, at disse repræsentationer er overraskende gode til at fange syntaktiske og semantiske regelmæssigheder i sprog, og at hvert forhold er kendetegnet ved en relationsspecifik vektorforskydning. Dette tillader vektororienteret ræsonnement baseret på forskydninger mellem ord. For eksempel læres det mandlige/kvindelige forhold automatisk, og med de inducerede vektorrepræsentationer resulterer “Konge – mand + kvinde” i en vektor meget tæt på “Dronning.”
— sproglige regelmæssigheder i kontinuerlige Rumordrepræsentationer, 2013.
to forskellige læringsmodeller blev introduceret, der kan bruges som en del af ordet2vec tilgang til at lære ordet indlejring; de er:
- kontinuerlig Pose-of-ord, eller cbo model.
- Kontinuerlig Spring-Gram Model.
CBO-modellen lærer indlejringen ved at forudsige det aktuelle ord baseret på dets kontekst. Den kontinuerlige skip-gram-model lærer ved at forudsige de omgivende ord, der er givet et aktuelt ord.
den kontinuerlige skip-gram-model lærer ved at forudsige de omgivende ord, der er givet et aktuelt ord.
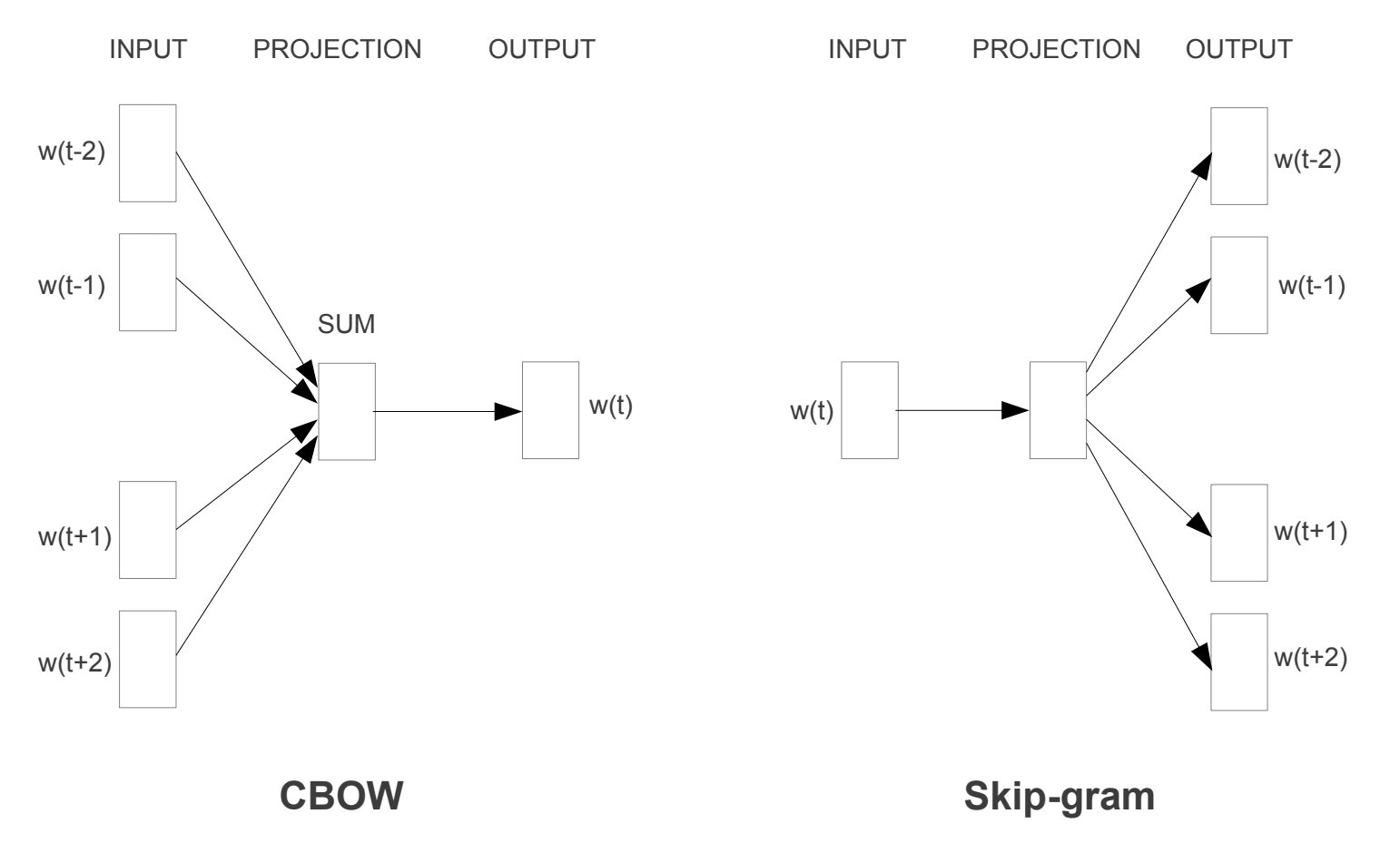
Ord2vec træningsmodeller
taget fra “effektiv estimering af Ordrepræsentationer i vektorrum”, 2013
begge modeller er fokuseret på at lære om ord i betragtning af deres lokale brugskontekst, hvor konteksten er defineret af et vindue med naboord. Dette vindue er en konfigurerbar parameter for modellen.
glidevinduets størrelse har en stærk effekt på de resulterende vektorligheder. Store vinduer har tendens til at producere mere aktuelle ligheder , mens mindre vinduer har tendens til at producere mere funktionelle og syntaktiske ligheder.
— side 128, neurale Netværksmetoder i naturlig sprogbehandling, 2017.
den vigtigste fordel ved fremgangsmåden er, at ordindlejringer af høj kvalitet kan læres effektivt (lav plads og tidskompleksitet), hvilket gør det muligt at lære større indlejringer (flere dimensioner) fra meget større tekstkorpora (milliarder af ord).
handske
de globale vektorer til Ordrepræsentation eller handske, algoritme er en udvidelse til ord2vec-metoden til effektiv læring af ordvektorer, udviklet af Pennington, et al. på Stanford.
klassiske vektorrumsmodelrepræsentationer af ord blev udviklet ved hjælp af matriksfaktoriseringsteknikker såsom Latent semantisk analyse (LSA), der gør et godt stykke arbejde med at bruge global tekststatistik, men ikke er så gode som de lærte metoder som ord2vec til at fange mening og demonstrere den på opgaver som beregning af analogier (f. eks. Kongen og dronningen eksempel ovenfor).
handske er en tilgang til at gifte sig med både den globale statistik over matriksfaktoriseringsteknikker som LSA med den lokale kontekstbaserede læring i ord2vec.
i stedet for at bruge et vindue til at definere lokal kontekst, konstruerer GloVe en eksplicit ord-kontekst eller ord-Co-forekomst matrice ved hjælp af statistik på tværs af hele tekstkorpuset. Resultatet er en læringsmodel, der kan resultere i generelt bedre ordindlejringer.
handske, er en ny global log-bilinær regressionsmodel til uovervåget indlæring af ordrepræsentationer, der overgår andre modeller på ordanalogi, ordlighed og navngivne enhedsgenkendelsesopgaver.
— handske: globale vektorer til Ordrepræsentation, 2014.
brug af Ordindlejringer
du har nogle muligheder, når det er tid til at bruge ordindlejringer på dit naturlige sprogbehandlingsprojekt.
dette afsnit beskriver disse muligheder.
Lær en indlejring
du kan vælge at lære et ord indlejring til dit problem.
dette kræver en stor mængde tekstdata for at sikre, at nyttige indlejringer læres, såsom millioner eller milliarder ord.
du har to hovedmuligheder, når du træner din ordindlejring:
- Lær det enkeltstående, hvor en model er uddannet til at lære indlejring, som gemmes og bruges som en del af en anden model til din opgave senere. Dette er en god tilgang, hvis du gerne vil bruge den samme indlejring i flere modeller.
- Lær i fællesskab, hvor indlejringen læres som en del af en stor opgavespecifik model. Dette er en god tilgang, hvis du kun har til hensigt at bruge indlejring på en opgave.
Genbrug en indlejring
det er almindeligt, at forskere stiller præuddannede ordindlejringer til rådighed gratis, ofte under en tilladelig licens, så du kan bruge dem på dine egne akademiske eller kommercielle projekter.
for eksempel er både ord2vec og handske ord indlejringer tilgængelige gratis.
disse kan bruges på dit projekt i stedet for at træne dine egne indlejringer fra bunden.
du har to hovedmuligheder, når det kommer til at bruge præuddannede indlejringer:
- statisk, hvor indlejringen holdes statisk og bruges som en komponent i din model. Dette er en passende tilgang, hvis indlejringen passer godt til dit problem og giver gode resultater.
- Opdateret, hvor den forududdannede indlejring bruges til at frø modellen, men indlejringen opdateres i fællesskab under træningen af modellen. Dette kan være en god mulighed, hvis du ønsker at få mest muligt ud af modellen og indlejre på din opgave.
Hvilken Mulighed Skal Du Bruge?
Udforsk de forskellige muligheder, og test om muligt for at se, hvilke der giver de bedste resultater på dit problem.
start måske med hurtige metoder, som at bruge en forududdannet indlejring, og brug kun en ny indlejring, hvis det resulterer i bedre ydeevne på dit problem.
Tutorials til Ordindlejring
dette afsnit viser nogle trinvise vejledninger, som du kan følge for at bruge ordindlejringer og bringe ordindlejring til dit projekt.
- Sådan udvikler du Ordindlejringer i Python med Gensim
- Sådan bruges Ordindlejringslag til dyb læring med Keras
- Sådan udvikler du en dyb CNN til sentimentanalyse (Tekstklassificering)
yderligere læsning
dette afsnit giver flere ressourcer om emnet, hvis du søger gå dybere.
artikler
- ordindlejring på Facebook
- Ord2vec på Facebook
- handske på Facebook
- en oversigt over ordindlejringer og deres forbindelse til distributionelle semantiske modeller, 2016.
- dyb læring, NLP og repræsentationer, 2014.
papirer
- Fordelingsstruktur, 1956.
- En Neural Probabilistisk Sprogmodel, 2003.
- en samlet arkitektur til naturlig sprogbehandling: dybe neurale netværk med Multitask-læring, 2008.
- kontinuerlige rumsprogmodeller, 2007.
- effektiv estimering af Ordrepræsentationer i vektorrum, 2013
- distribuerede repræsentationer af ord og sætninger og deres Kompositionalitet, 2013.
- handske: globale vektorer til Ordrepræsentation, 2014.
projekter
- ord2vec på Google-kode
- handske: globale vektorer til Ordrepræsentation
bøger
- neurale Netværksmetoder i naturlig sprogbehandling, 2017.
Resume
i dette indlæg opdagede du Ordindlejringer som en repræsentationsmetode til tekst i deep learning-applikationer.
specifikt lærte du:
- hvad ordet indlejring tilgang til repræsentation tekst er, og hvordan det adskiller sig fra andre funktion udvinding metoder.
- at der er 3 hovedalgoritmer til at lære et ordindlejring fra tekstdata.
- at du du kan enten træne en ny indlejring eller bruge en forududdannet indlejring på din naturlige sprogbehandlingsopgave.
har du nogen spørgsmål?
stil dine spørgsmål i kommentarerne nedenfor, og jeg vil gøre mit bedste for at svare.
udvikle dybe læringsmodeller til tekstdata i dag!

udvikle dine egne Tekstmodeller på få minutter
…med blot et par linjer python kode
Opdag hvordan i min nye Ebook:
Deep Learning For Natural Language Processing
det giver selvstudie tutorials om emner som:
Bag-of-ord, Ord indlejring, sprogmodeller, billedtekst Generation, tekst Oversættelse og meget mere…
endelig bringe dyb læring til dine naturlige Sprogbehandlingsprojekter
spring over akademikerne. Bare Resultater.
se hvad der er indeni