der er også en række forkerte måder, du kan inkludere variabler på. En tyngdekraftsmodel fungerer ikke, medmindre hver variabel opfylder følgende kriterier:
- numerisk
- komplet
- pålidelig
kun numeriske Data
da tyngdekraftsmodellen er en matematisk ligning, skal alle inputvariabler være numeriske. Det kan være en optælling (befolkning), rumlig foranstaltning (område, afstand osv.), tid (timer fra London til fods), procentdel (lønstigning/fald), valutaværdi (løn i shilling) eller et andet mål for de steder, der er involveret i modellen.
tal skal være meningsfulde og kan ikke være nominelle kategoriske variabler, der fungerer som en stand-in for en kvalitativ attribut. For eksempel kan du ikke vilkårligt tildele et nummer og bruge det i modellen, hvis nummeret ikke har betydning (f.eks. road quality = god eller road quality = 4). Selvom sidstnævnte er numerisk, er det ikke et mål for vejkvalitet. I stedet kan du bruge den gennemsnitlige kørehastighed i miles i timen som en fuldmagt til vejkvalitet. Hvorvidt gennemsnitshastighed er et meningsfuldt mål for vejkvalitet er op til dig at bestemme og forsvare som forfatter til undersøgelsen.
generelt set, hvis du kan måle det eller tælle det, kan du modellere det.
kun komplette Data
alle kategorier af data skal eksistere for hvert interessepunkt. Det betyder, at alle de 32 amter, der er under analyse, skal have pålidelige data for hver push and pull-faktor. Du kan ikke have huller eller emner, såsom et amt, hvor du ikke har gennemsnitslønnen.
kun pålidelige Data
computervidenskabens ordsprog “garbage in, garbage out” gælder også for tyngdekraftsmodeller, som kun er så pålidelige som de data, der bruges til at bygge dem. Ud over at vælge robuste og pålidelige Historiske data fra kilder, du kan stole på, er der mange måder at lave fejl på, der vil gøre output fra din model meningsløs. For eksempel er det værd at sørge for, at de data, du har, nøjagtigt matcher territorierne (f.eks.
afhængigt af tid og sted for dit studie kan du have svært ved at få et pålideligt sæt data, som du kan basere din model på. Jo længere tilbage i fortiden ens undersøgelse, jo vanskeligere kan det være. Ligeledes kan det være lettere at gennemføre disse typer analyser i samfund, der var stærkt bureaukratiske og efterlod et godt overlevende papirspor, såsom i Europa eller Nordamerika.
for at sikre datakvaliteten i dette casestudie blev hver variabel enten pålideligt beregnet eller afledt af offentliggjorte fagfællebedømte Historiske data (Se tabel 1). Præcis hvordan disse data blev samlet kan læses i den oprindelige artikel, hvor det blev forklaret i dybden.11
vores fem Modelvariabler
med ovenstående principper i tankerne kunne vi have valgt et hvilket som helst antal variabler i betragtning af det, vi vidste om migration push and pull faktorer. Vi besluttede os for fem (5), valgt ud fra, hvad vi troede ville være vigtigst, og som vi vidste kunne sikkerhedskopieres med pålidelige data.
| variabel | kilde |
|---|---|
| befolkning ved oprindelse | 1771 værdier, “engelsk amtspopulationer”, s.54-5.12 |
| afstand fra London | beregnet med programmel |
| pris for hvede | kanon og Brunt, “ugentlige Britiske kornpriser”13 |
| gennemsnitsløn ved oprindelse | Hunt, “industrialisering og Regional ulighed”, s. 965-6.14 |
| bane af løn | Hunt, “industrialisering og Regional ulighed”, s. 965-6.15 |
tabel 1: De fem variabler, der blev brugt i modellen, og kilden til hver i den fagfællebedømte litteratur
efter at have besluttet disse variabler, besluttede medforfatteren af den oprindelige undersøgelse, Adam Dennett, at omskrive formlen for at gøre den selvdokumenterende, så det var let at fortælle, hvilke bits der vedrørte hver af disse fem variabler. Dette er grunden til, at formlen vist ovenfor ser anderledes ud end den i det originale forskningspapir. De nye symboler kan ses i tabel 2:
to yderligere variabler $i$ og $j$, betyder henholdsvis “ved oprindelsessted” og “ved London”. $V_{i}$ betyder “lønniveauer på oprindelsesstedet”, mens $V_{j}$ ville betyde”lønniveauer i London”. Disse syv nye symboler kan erstatte de mere generiske i formlen:
\
dette er nu mere detaljeret og en lidt selvdokumenteret version af den forrige ligning. Begge løser matematisk på nøjagtig samme måde, da ændringerne er rent overfladiske og til gavn for en menneskelig bruger.
det udfyldte Variable datasæt
for at gøre vejledningen hurtigere lettere at gennemføre, er dataene for hver af de 5 variabler og hvert af de 32 amter allerede blevet samlet og renset og kan ses i tabel 3 eller hentet som en csv-fil. Denne tabel inkluderer også det kendte antal omstrejfende fra dette amt, som observeret i den primære kilderegistrering:
| Amt | Vagrants | $ d $ km til London | $ P $ befolkning (personer) | $ V $ gennemsnitsløn (Shilling) | $ V $ Lønbane 1767-95 (%ændring) | $ V $ hvede pris (Shilling)) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Madsen | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Danmark | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Frederikshavn | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Vestmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Viltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Vesterbro | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
den endelige forskel mellem denne formel og den, der blev brugt i den originale artikel, er, at to af variablerne tilfældigvis har et stærkere forhold til vagrancy, når de afbildes naturligt logaritmisk. De er befolkning ved oprindelse ($P$) og afstand fra oprindelse til London ($d$). Hvad dette betyder er, at for dataene i denne undersøgelse er regressionslinjen (undertiden kaldet line of best fit) en bedre pasform, når dataene er logget, end når de ikke har været. Du kan se dette i Figur 7 med de ikke-loggede befolkningstal til venstre og den loggede version til højre. Flere af punkterne er tættere på den linje, der passer bedst på den loggede graf end på den ikke-loggede.
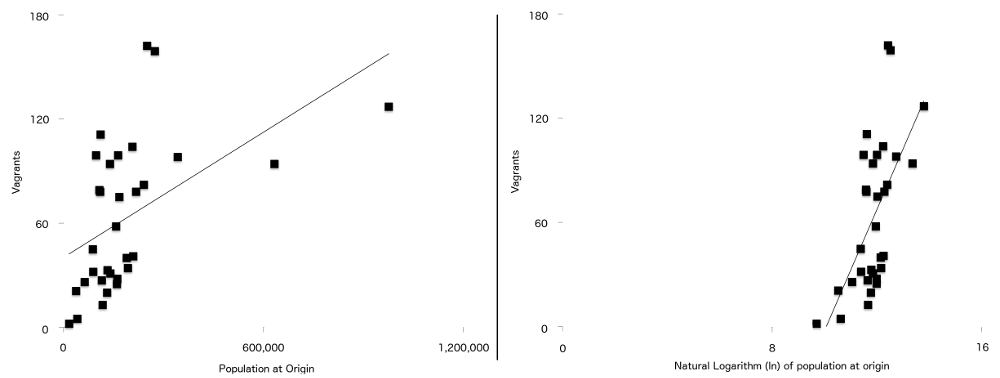
Figur 7: Antal Vagrants afbildet mod befolkning ved oprindelse (venstre) og naturlig log over oprindelsespopulation (højre) med en simpel regressionslinje overlejret på begge. Bemærk det stærkere forhold mellem de to variabler, der er synlige på den anden graf.
da dette er tilfældet med disse særlige data (dine egne data i en lignende type undersøgelse følger muligvis ikke dette mønster), blev formlen justeret til at bruge de naturligt loggede versioner af disse to variabler, hvilket resulterede i den endelige formel, der blev brugt i tyngdekraftsmodellen (figur 8). Vi kunne umuligt have vidst om behovet for denne justering, før vi havde indsamlet vores variable data:
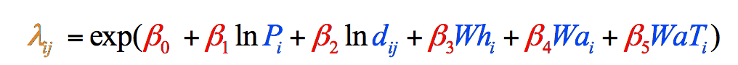
figur 8: den endelige tyngdekraftsmodelformel opdelt efter trin og farvekodet. Elementer i sort er matematiske operationer. Elementer i blåt repræsenterer vores variabler, som vi lige har samlet (Trin 1). Elementer i rødt repræsenterer vægtningerne for hver variabel, som vi skal beregne (Trin 2), og elementet i Orange er det endelige skøn over vagrants fra det amt, som vi kan beregne, når vi har de andre oplysninger (Trin 3).
værdierne i tabel 3 giver os alt, hvad vi har brug for for at udfylde de blå dele af hver ligning i figur 8. Vi kan nu rette opmærksomheden mod de røde dele, som fortæller os, hvor vigtig hver variabel er i modellen generelt, og giver os de tal, vi har brug for for at fuldføre ligningen.
Trin 2: Bestemmelse af Vægtningerne
vægtningerne for hver variabel fortæller os, hvor vigtig denne push/pull-faktor er i forhold til de andre variabler, når vi prøver at estimere antallet af vagrants, der skulle være kommet fra et givet amt. Parametrene for $ KRP skal bestemmes på tværs af hele datasættet ud fra de kendte data. Med disse til rådighed vil vi være i stand til at sammenligne individuelle oprindelsesspecifikke observationer med den generelle model. Vi kan derefter undersøge disse og identificere over og under forudsagte strømme mellem de forskellige oprindelser og destinationen.
på dette stadium ved vi ikke, hvor vigtigt hver er. Måske er hvedeprisen en bedre forudsigelse for migration end Afstand? Vi ved det ikke, før vi beregner værdierne på $kr1$ til $kr5$ (vægtningerne) ved at løse ligningen ovenfor. Den y-skæringspunktet ($KR0$) kun muligt at beregne, når du kender alle de andre (kr1-kr5 kr). Disse er de røde værdier i figur 8 ovenfor. Vægtningerne kan ses i tabel 4 og i tabel A1 i det originale papir.16 Vi vil nu vise, hvordan vi kom til disse værdier.
for at beregne disse værdier kræver langhånd en utrolig mængde arbejde. Vi vil bruge en hurtig løsning i programmeringssproget r, der udnytter Vilhelm Venables og Brian Ripleys MASSEPAKKE, der kan løse negative binomiale regressionsligninger som vores tyngdekraftsmodel med en enkelt kodelinje. Det er dog vigtigt at forstå principperne bag, hvad man gør for at forstå, hvad koden gør (bemærk de følgende afsnit gør ikke beregningen, men forklar dens trin for dig; vi foretager beregningen med koden længere nede på siden).
beregning af de individuelle vægtninger (i princippet)
$lira_{1}$, $lira_{2}$ osv.er de samme som $Lira$ i den enkle lineære regressionsmodel ovenfor, som er hældningen af regressionslinjen (stigningen i løbet af løbet, eller hvor meget $y$ stiger, når $$ stiger med 1). Den eneste forskel her mellem en simpel lineær Regression og vores tyngdekraftsmodel er, at vi skal beregne 5 skråninger i stedet for 1.
en simpel lineær Regression\(y = kr + kr\)
vi bliver nødt til at løse for hver af disse fem skråninger, før vi kan beregne y-skæringspunktet i det næste trin. Det skyldes, at skråningerne af de forskellige $liter$ værdier er en del af ligningen til beregning af y-intercept.
formlen til beregning af $liter$ i en regressionsanalyse er:
\
Pearsons korrelationskoefficient
Pearsons korrelationskoefficient kan beregnes langhånd, men det er en ret lang beregning i dette tilfælde, der kræver 64 tal. Der er nogle gode videotutorials på engelsk tilgængelige online, hvis du gerne vil se en gennemgang af, hvordan du foretager beregningerne langhånd.17 der er også et antal online-regnemaskiner, der beregner $r$ for dig, hvis du leverer dataene. I betragtning af det store antal cifre, der skal beregnes, vil jeg anbefale en hjemmeside med et indbygget værktøj designet til at foretage denne beregning. Sørg for at vælge et velrenommeret sted, såsom et, der tilbydes af et universitet.
beregning af $s_{y}$& $s_{s}$ (standardafvigelse)
standardafvigelse er en måde at udtrykke, hvor meget variation fra gennemsnittet (gennemsnittet) der er i dataene. Med andre ord, er dataene ret grupperet omkring gennemsnittet, eller er spredningen meget bredere?
igen er der online regnemaskiner og statistiske programpakker, der kan gøre denne beregning for dig, hvis du giver dataene.
beregning af $kris_{0}$ (y-skæringspunktet)
Dernæst skal vi beregne y-skæringspunktet. Formlen til beregning af y-intercept i en simpel lineær Regression er:
\
beregningen bliver imidlertid meget mere kompliceret i en multipel regressionsanalyse, da hver variabel påvirker beregningen. Dette gør det meget vanskeligt at gøre det i hånden, og er en af grundene til, at vi vælger en programmatisk løsning.
koden til beregning af Vægtningerne
MASSESTATISTIKPAKKEN, skrevet til programmeringssproget r, har en funktion, der kan løse negative binomiale regressionsligninger, hvilket gør det meget nemt at beregne, hvad der ellers ville være en meget vanskelig langhåndsformel.
dette afsnit forudsætter, at du har installeret r og har installeret MASSEPAKKEN. Hvis du ikke har gjort det, bliver du nødt til det, før du fortsætter. Taryn Devar tutorial om R Basics med tabeldata indeholder r installationsinstruktioner.
for at bruge denne kode, skal du hente en kopi af datasættet af de fem variabler plus antallet af observerede vagrants fra hver af de 32 amter. Dette er tilgængeligt ovenfor som Tabel 3, eller kan hentes som en .csv-fil. Uanset hvilken tilstand du vælger, skal du gemme filen som Vagrantseksampledata.csv. Hvis du bruger en Mac, skal du sørge for at gemme den som et format .csv-fil. Åbn Vagrantseksempledata.CSV og gøre dig bekendt med dens indhold. Du bør bemærke hver af de 32 amter, sammen med hver af de variabler, vi har diskuteret i hele denne tutorial. Vi bruger kolonneoverskrifterne til at få adgang til disse data med vores computerprogram. Jeg kunne have kaldt dem noget, men i denne fil er de:
vagrantspopulationdistancewheatwageswageTrajectory
i den samme mappe, som du gemte csv-filen, skal du oprette og gemme en ny r-scriptfil (du kan gøre dette med enhver teksteditor eller med RStudio, men brug ikke en tekstbehandler som MS-ord). Gem det som vægtningerberegninger.r.
vi vil nu skrive et kort program, der:
- installerer MASSEPAKKEN
- kalder MASSEPAKKEN, så vi kan bruge den i vores kode
- gemmer indholdet af .CSV-fil til en variabel, som vi kan bruge programmatisk
- løser tyngdekraftsmodelligningen ved hjælp af datasættet
- udsender resultaterne af beregningen.
hver af disse opgaver opnås igen med en enkelt linje kode
Kopier ovenstående kode til din vægtberegninger.R fil og gem. Du kan nu køre koden ved hjælp af dit foretrukne r-miljø (jeg bruger RStudio), og resultaterne af beregningen skal vises i konsolvinduet (hvordan dette ser ud afhænger af dit miljø). Det kan være nødvendigt at indstille arbejdsmappen i dit r-miljø til det bibliotek, der indeholder din .csv og .r filer. Hvis du bruger RStudio, kan du gøre dette via menuerne (Session -> Indstil arbejdsmappe -> Vælg mappe). Du kan også opnå det samme med kommandoen:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundBemærk, at Linje 4 er den linje, der løser ligningen for os ved hjælp af glm.nb-funktion, som er forkortelse for”generaliseret lineær model – negativ binomial”. Denne linje kræver en række indgange:
- vores variabler ved hjælp af kolonneoverskrifterne som skrevet i .CSV-fil, sammen med enhver logning, der skal gøres for dem (
vagrants, log (population), log(distance),wheat,wages,wageTrajectory). Hvis du kørte en model med dine egne data, ville du justere disse for at afspejle dine kolonneoverskrifter i dit datasæt. - hvor koden kan finde dataene – i dette tilfælde en variabel, vi har defineret i linje 3 kaldet
gravityModelData.
udgangene af beregningen kan ses i figur 9:
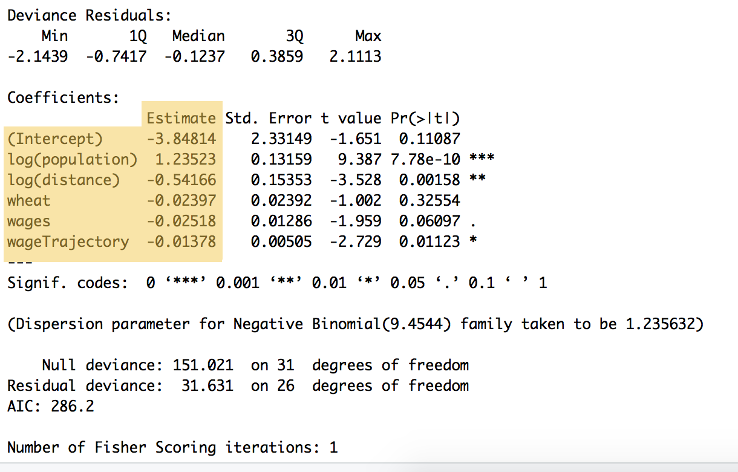
figur 9: sammendraget af ovenstående kode, der viser vægtningerne for hver variabel og y-intercept, angivet under overskriften ‘estimat’ ($\beta_{0}$ til $\beta_{5}$. Dette sammendrag viser også en række andre beregninger, herunder statistisk signifikans.
Trin 3: Beregning af estimaterne for hvert amt
vi skal gøre dette en gang for hvert af de 32 amter.
du kan gøre dette med en videnskabelig lommeregner, ved at oprette en regnearkformel eller skrive et computerprogram. For at gøre dette automatisk i R, kan du tilføje følgende til din kode og køre programmet igen. Denne for loop beregner det forventede antal vagrants fra hvert af de 32 amter i eksemplet og udskriver resultaterne for dig at se:
for at opbygge forståelse foreslår jeg at gøre en AMT langhånd. Denne tutorial vil bruge Hertfordshire som langhåndseksemplet (men processen er nøjagtig den samme for de andre 31 amter).
ved hjælp af dataene for Hertfordshire i tabel 3 og vægtningerne for hver variabel i tabel 4 kan vi nu udfylde vores formel, som giver resultatet af 95:
lad os først bytte symbolerne ud for tallene, taget fra tabellerne nævnt ovenfor.
start derefter med at beregne værdier for at komme til estimatet. Husk matematisk rækkefølge af operationer, multiplicer værdier, før du tilføjer. Så start med at beregne hver variabel (du kan bruge en videnskabelig lommeregner til dette):
det næste trin er at tilføje tallene sammen:
estimated vagrants = exp(4.56232408897)og endelig, for at beregne den eksponentielle funktion (brug en videnskabelig lommeregner):
estimated vagrants = 95.8059926832vi har droppet resten og erklæret, at det anslåede antal vagrants fra Hertfordshire i denne model er 95. Du er nødt til at foretage de samme beregninger for hver af de andre amter, som du kan fremskynde ved hjælp af et regnearksprogram. Bare for at sikre, at du kan gøre det igen, har jeg også medtaget tallene for Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
jeg anbefaler at vælge et andet amt og beregne det langhånd, før du går videre, for at sikre digkan gøre beregningerne alene. Det korrekte svar er tilgængeligt i tabel 5, der sammenligner de observerede værdier (som det ses i den primære kildepost) med de estimerede værdier (som beregnet af vores tyngdekraftsmodel). Den “resterende” er forskellen mellem de to, med en stor forskel, der tyder på et uventet antal vagrants, der måske er værd at se nærmere på med ens historikers hat på.
| Amt | Observeret Værdi | Estimeret Værdi | Restværdi |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Madsen | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 |
| Danmark | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| København | 104 | 70 | 34 |
| Vestmorland | 5 | 5 | 0 |
| Viltshire | 99 | 95 | 4 |
| Vesterbro | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Trin 4-historisk fortolkning
på dette trin er modelleringsprocessen afsluttet, og det sidste trin er historisk fortolkning.
den oprindelige offentliggjorte artikel, som denne casestudie var baseret på, er primært afsat til at fortolke, hvad resultaterne af modelleringen betyder for vores forståelse af lavere klasse migration i det attende århundrede. Som det ses på kortet i figur 5, der var dele af landet, som modellen stærkt antydede, enten var over – eller under-at sende migranter i lavere klasse til London.
medforfatterne tilbød deres fortolkninger af, hvorfor disse mønstre kan have vist sig. Disse fortolkninger varierede efter sted. I områder i det nordlige England, der hurtigt industrialiserede sig, såsom Yorkshire eller Manchester, syntes mulighederne lokalt at give folk færre grunde til at forlade, hvilket resulterede i lavere migration end forventet til London. I faldende områder mod vest, såsom Bristol, lokket i London var stærkere, da flere mennesker forlod at søge arbejde i hovedstaden.
ikke alle mønstre var forventet. Northumberland i det fjerne nordøst viste sig at være en regional anomali og sendte langt flere (kvindelige) migranter til London, end vi ville forvente at se. Uden output fra modellen er det usandsynligt, at vi overhovedet ville have tænkt at overveje Northumberland, især fordi det var så langt fra metropolen, og vi formodede at have svage bånd til London. Modellen gav således nye beviser for os at betragte som historikere og ændrede vores forståelse af forholdet mellem London og Northumberland. En fuldstændig diskussion af vores resultater kan læses i den oprindelige artikel.18
hvis du tager din viden videre
efter at have prøvet dette eksempelproblem, skal du have en klar forståelse af, hvordan du bruger denne eksempelformel, samt om en tyngdekraftsmodel kan være en passende løsning til dit forskningsproblem. Du har erfaring og ordforråd til at nærme dig og diskutere tyngdekraftsmodeller med en passende matematisk kompetent samarbejdspartner, hvis du har brug for det, som kan hjælpe dig med at tilpasse det til dit eget casestudie.
hvis du er heldig nok til også at have data om migranter, der flytter til slutningen af det attende århundrede London, og du vil modellere det ved hjælp af de samme fem variabler, der er anført ovenfor, ville denne formel fungere som-er – der er en nem undersøgelse her for nogen med de rigtige data. Imidlertid, denne model fungerer ikke kun for undersøgelser om migranter, der flytter til London. Variablerne kan ændre sig, og destinationen behøver ikke at være London. Det ville være muligt at bruge en tyngdekraftsmodel til at studere migration til det gamle Rom, eller enogtyvende århundrede Bangkok, hvis du har dataene og forskningsspørgsmålet. Det behøver ikke engang at være en model for migration. For at bruge den colombianske kaffecasestudie fra introduktionen, der fokuserer på handel snarere end migration, viser tabel 6 en levedygtig anvendelse af den samme formel, uændret.
| kriterier | kaffe eksport eksempel |
|---|---|
| et oprindelsessted | kaffeeksport fra havnen, Colombia |
| flere endelige destinationer | de 21 lande på den vestlige halvkugle i 1950 |
| fem forklarende variabler | (1) Antal Atlanterhavshavne i modtagerlandet (2) miles fra Colombia, (3) modtagerlandets bruttonationalprodukt, (4) indenlandsk kaffe dyrket i tons, (5) kaffebarer pr. 10.000 mennesker |
der er en lang historie med tyngdekraftsmodeller i akademisk stipendium. For at bruge en effektivt til forskning skal du forstå den grundlæggende teori og matematik bag dem og årsagerne til, at de har udviklet sig som de har. Det er også vigtigt at forstå deres grænser og betingelser for at bruge dem korrekt, hvoraf nogle blev diskuteret ovenfor. Det kan også hjælpe at vide:
-
en tyngdekraftsmodel som den, der bruges i dette eksempel, kan kun fungere i et lukket system. Ovenstående model havde kun 32 mulige oprindelsessteder, hvilket gjorde det muligt at køre modellen 32 gange. Et ukendt eller uendeligt stort antal oprindelsessteder (eller destinationer afhængigt af din model) ville kræve en anden ligning.
-
tyngdekraftsmodelkonceptet er også bygget på den forudsætning, at bevægelser (migration, handel osv.) er baseret på en samling frivillige individuelle beslutninger, der kan påvirkes af eksterne faktorer, men ikke kontrolleres fuldstændigt af dem. For eksempel kan frivillige vandringer eller køb foretaget af fri vilje modelleres ved hjælp af denne teknik, men tvungen migration, obligatorisk køb eller naturlige processer såsom fuglevandring eller flodstrøm følger muligvis ikke de samme principper, og derfor kan en anden type model være nødvendig.
-
Tyngdekraftsmodeller kan bruges til at forudsige adfærd hos populationer, men ikke enkeltpersoner, og forsøg på at modellere data bør derfor omfatte et stort antal bevægelser for at sikre statistisk signifikans.
der er mange flere faldgruber, men også enorme muligheder. Det er mit håb, at denne gennemgang af en tyngdekraftsmodel og dens ledsagende offentliggjorte forskning vil gøre dette kraftfulde værktøj mere tilgængeligt for historikere. Hvis du planlægger at bruge en tyngdekraftsmodel i din videnskabelige forskning, anbefaler forfatteren stærkt følgende artikler:
anerkendelser
med tak til Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cobins, Katrina Navickas og Leanne Calvert for at læse og kommentere tidligere udkast til denne artikel. Også tak til British Academy for finansiering af Skriveværkstedet i Bogot Kristi, Colombia, hvor denne artikel blev udarbejdet. Og endelig til Adam Dennett for at introducere mig til disse vidunderlige formler og frigøre deres potentiale for historikere.