Eine sanfte Einführung in den Auto-Encoder und einige seiner häufigsten Anwendungsfälle mit Python-Code
Hintergrund:
Autoencoder ist ein unbeaufsichtigtes künstliches neuronales Netzwerk, das lernt, wie man Daten effizient komprimiert und codiert, und dann lernt, wie man die Daten von der reduzierten codierten Darstellung zu einer Darstellung rekonstruiert, die der ursprünglichen Eingabe so nahe wie möglich kommt.
Autoencoder reduziert die Datendimensionen, indem es lernt, das Rauschen in den Daten zu ignorieren.
Hier ist ein Beispiel für das Eingabe- / Ausgabebild vom MNIST-Datensatz zu einem Autoencoder.
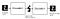
Autoencoder-Komponenten:
Autoencoder besteht aus 4 Hauptteilen:
1- Encoder: In dem das Modell lernt, die Eingabedimensionen zu reduzieren und die Eingabedaten in eine codierte Darstellung zu komprimieren.
2- Engpass: dies ist die Ebene, die die komprimierte Darstellung der Eingabedaten enthält. Dies ist die geringstmögliche Größe der Eingabedaten.
3- Decoder: Bei dem das Modell lernt, die Daten aus der codierten Darstellung so zu rekonstruieren, dass sie der ursprünglichen Eingabe so nahe wie möglich kommen.
4- Rekonstruktionsverlust: Mit dieser Methode wird gemessen, wie gut der Decoder arbeitet und wie nahe der Ausgang am ursprünglichen Eingang liegt.
Das Training beinhaltet dann die Verwendung von Backpropagation, um den Rekonstruktionsverlust des Netzwerks zu minimieren.
Sie müssen sich fragen, warum ich ein neuronales Netzwerk trainieren sollte, nur um ein Bild oder Daten auszugeben, die genau mit der Eingabe übereinstimmen! Dieser Artikel behandelt die häufigsten Anwendungsfälle für Autoencoder. Fangen wir an:
Autoencoder-Architektur:
Die Netzwerkarchitektur für Autoencoder kann je nach Anwendungsfall zwischen einem einfachen FeedForward-Netzwerk, einem LSTM-Netzwerk oder einem faltungsneuralen Netzwerk variieren. Wir werden einige dieser Architekturen in den nächsten Zeilen untersuchen.
Es gibt viele Möglichkeiten und Techniken, Anomalien und Ausreißer zu erkennen. Ich habe dieses Thema in einem anderen Beitrag unten behandelt:
Wenn Sie jedoch Eingabedaten korreliert haben, funktioniert die Autoencoder-Methode sehr gut, da der Codierungsvorgang auf den korrelierten Funktionen beruht, um die Daten zu komprimieren.
Angenommen, wir haben einen Autoencoder für den MNIST-Datensatz trainiert. Mit einem einfachen FeedForward-neuronalen Netzwerk können wir dies erreichen, indem wir ein einfaches 6-Schichten-Netzwerk wie folgt erstellen:
Die Ausgabe des obigen Codes lautet:
Wie Sie in der Ausgabe sehen können, ist der letzte Rekonstruktionsverlust / -fehler für den Validierungssatz 0,0193, was großartig ist. Wenn ich nun ein normales Bild aus dem MNIST-Datensatz übergebe, ist der Rekonstruktionsverlust sehr gering (< 0,02), ABER wenn ich versuche, ein anderes Bild (Ausreißer oder Anomalie) zu übergeben, erhalten wir einen hohen Rekonstruktionsverlustwert, da das Netzwerk das Bild / die Eingabe, die als Anomalie angesehen wird, nicht rekonstruieren konnte.
Hinweis Im obigen Code können Sie nur den Encoder-Teil verwenden, um einige Daten oder Bilder zu komprimieren, und Sie können auch nur den Decoder-Teil verwenden, um die Daten zu dekomprimieren, indem Sie die Decoder-Layer laden.
Lassen Sie uns nun eine Anomalieerkennung durchführen. Der folgende Code verwendet zwei verschiedene Bilder, um den Anomalie-Score (Rekonstruktionsfehler) mithilfe des oben trainierten Autoencoder-Netzwerks vorherzusagen. das erste Bild stammt vom MNIST und das Ergebnis ist 5.43209. Dies bedeutet, dass das Bild keine Anomalie darstellt. Das zweite Bild, das ich verwendet habe, ist ein völlig zufälliges Bild, das nicht zum Trainingsdatensatz gehört, und die Ergebnisse waren: 6789.4907. Dieser hohe Fehler bedeutet, dass das Bild eine Anomalie ist. Das gleiche Konzept gilt für jede Art von Datensatz.