Als Datenwissenschaftler in der Verbraucherindustrie habe ich normalerweise das Gefühl, dass Boosting-Algorithmen für die meisten Aufgaben des prädiktiven Lernens zumindest inzwischen ausreichen. Sie sind leistungsstark, flexibel und können mit einigen Tricks gut interpretiert werden. Daher denke ich, dass es notwendig ist, einige Materialien durchzulesen und etwas über die Boosting-Algorithmen zu schreiben.
Der größte Teil des Inhalts in diesem Artikel basiert auf dem Papier: Tree Boosting With XGBoost: Why Does XGBoost Win „Every“ Machine Learning Competition?. Es ist ein wirklich informatives Papier. Fast alles in Bezug auf Boosting-Algorithmen wird in dem Papier sehr klar erklärt. Das Papier enthält also 110 Seiten: (
Für mich werde ich mich grundsätzlich auf die drei beliebtesten Boosting-Algorithmen konzentrieren: AdaBoost, GBM und XGBoost. Ich habe den Inhalt in zwei Teile geteilt. Der erste Artikel (dieser) wird sich auf den AdaBoost-Algorithmus konzentrieren, und der zweite wird sich dem Vergleich zwischen GBM und XGBoost zuwenden.
AdaBoost, kurz für „Adaptive Boosting“, ist der erste praktische Boosting-Algorithmus, der 1996 von Freund und Schapire vorgeschlagen wurde. Es konzentriert sich auf Klassifizierungsprobleme und zielt darauf ab, eine Reihe schwacher Klassifikatoren in eine starke umzuwandeln. Die endgültige Gleichung für die Klassifizierung kann wie folgt dargestellt werden
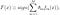
wobei f_m für den m_th schwachen Klassifikator steht und theta_m das entsprechende Gewicht ist. Es ist genau die gewichtete Kombination von M schwachen Klassifikatoren. Das gesamte Verfahren des AdaBoost-Algorithmus kann wie folgt zusammengefasst werden.
AdaBoost-Algorithmus
Bei einem Datensatz, der n Punkte enthält, wobei

Hier bezeichnet -1 die negative Klasse, während 1 die positive darstellt.
Initialisieren Sie das Gewicht für jeden Datenpunkt als:

Für Iteration m=1,…,M:
(1) Passen Sie schwache Klassifikatoren an den Datensatz an und wählen Sie den mit dem niedrigsten gewichteten Klassifizierungsfehler aus:

(2) Berechnen Sie das Gewicht für den m_th schwachen Klassifikator:

Für jeden Klassifikator mit einer Genauigkeit von mehr als 50% ist das Gewicht positiv. Je genauer der Klassifikator, desto größer das Gewicht. Während für den Klassifikator mit weniger als 50% Genauigkeit das Gewicht negativ ist. Es bedeutet, dass wir seine Vorhersage kombinieren, indem wir das Zeichen umdrehen. Zum Beispiel können wir einen Klassifikator mit 40% Genauigkeit in 60% Genauigkeit umwandeln, indem wir das Vorzeichen der Vorhersage umdrehen. Selbst wenn der Klassifikator schlechter abschneidet als das zufällige Erraten, trägt er dennoch zur endgültigen Vorhersage bei. Wir wollen nur keinen Klassifikator mit exakter Genauigkeit von 50%, der keine Informationen hinzufügt und somit nichts zur endgültigen Vorhersage beiträgt.
(3) Aktualisieren Sie das Gewicht für jeden Datenpunkt als:

wobei Z_m ein Normalisierungsfaktor ist, der sicherstellt, dass die Summe aller Instanzgewichte gleich 1 ist.
Wenn ein falsch klassifizierter Fall von einem positiv gewichteten Klassifikator stammt, wäre der Term „exp“ im Zähler immer größer als 1 (y*f ist immer -1, theta_m ist positiv). Daher würden falsch klassifizierte Fälle nach einer Iteration mit größeren Gewichten aktualisiert. Die gleiche Logik gilt für die negativ gewichteten Klassifikatoren. Der einzige Unterschied besteht darin, dass die ursprünglich korrekten Klassifikationen nach dem Umdrehen des Zeichens zu Fehlklassifikationen werden.
Nach jeder Iteration können wir die endgültige Vorhersage erhalten, indem wir die gewichtete Vorhersage jedes Klassifikators summieren.
AdaBoost as a Forward Stagewise Additive Model
Dieser Teil basiert auf einem Papier: Additive logistische Regression: eine statistische Sicht auf Boosting. Für mehr detaillierte informationen, bitte beachten sie die original papier.
Im Jahr 2000 haben Friedman et al. entwicklung einer statistischen Ansicht des AdaBoost-Algorithmus. Sie interpretierten AdaBoost als stufenweises Schätzverfahren zur Anpassung eines additiven logistischen Regressionsmodells. Sie zeigten, dass AdaBoost die exponentielle Verlustfunktion tatsächlich minimierte

Es wird minimiert bei

Da für AdaBoost y nur -1 oder 1 sein kann, kann die Verlustfunktion wie folgt umgeschrieben werden

Lösen wir weiter nach F(x), erhalten wir

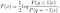
Wir können das normale logistische Modell weiter aus der optimalen Lösung von F (x) ableiten):

Es ist fast identisch mit dem logistischen Regressionsmodell trotz eines Faktors 2.
Angenommen, wir haben eine aktuelle Schätzung von F(x) und versuchen, eine verbesserte Schätzung F(x)+cf(x) . Für feste c und x können wir L(y, F (x) + cf (x)) um f(x) zweiter Ordnung erweitern)=0,

So,

wo E_w(./ x) gibt eine gewichtete bedingte Erwartung an, und die Gewichtung für jeden Datenpunkt wird berechnet als

Wenn c > 0, ist das Minimieren der gewichteten bedingten Erwartung gleich dem Maximieren

Da y nur 1 oder -1 sein kann, kann die gewichtete Erwartung wie folgt umgeschrieben werden

Die optimale Lösung kommt als

Nach der Bestimmung von f (x) kann das Gewicht c durch direkte Minimierung von L (y, F (x) + cf (x)) berechnet werden:

Lösen für c, erhalten wir


Sei epsilon gleich der gewichteten Summe falsch klassifizierter Fälle, dann

Beachten Sie, dass c negativ sein kann, wenn der schwache Lernende schlechter als zufällige Vermutung (50%), in in diesem Fall kehrt es automatisch die Polarität um.
In Bezug auf Instanzgewichte wird nach der verbesserten Addition das Gewicht für eine einzelne Instanz zu,

Somit wird das Instanzgewicht wie folgt aktualisiert

Im Vergleich zu denen, die im AdaBoost-Algorithmus verwendet werden,

wir können sehen, dass sie in identischer Form sind. Daher ist es sinnvoll, AdaBoost als vorwärtsstadienweises additives Modell mit exponentieller Verlustfunktion zu interpretieren, das iterativ einen schwachen Klassifikator anpasst, um die aktuelle Schätzung bei jeder Iteration zu verbessern.:
