Es gibt auch eine Reihe falscher Möglichkeiten, Variablen einzuschließen. Ein Gravitationsmodell funktioniert nur, wenn jede Variable die folgenden Kriterien erfüllt:
- Numerisch
- Vollständig
- Zuverlässig
Nur numerische Daten
Da das Gravitationsmodell eine mathematische Gleichung ist, müssen alle Eingangsvariablen numerisch sein. Dies kann eine Zählung (Bevölkerung), ein räumliches Maß (Fläche, Entfernung usw.), eine Zeit (Stunden zu Fuß von London entfernt), ein Prozentsatz (Lohnerhöhung / -abnahme), ein Währungswert (Löhne in Schilling) oder ein anderes Maß für die am Modell beteiligten Orte sein.
Zahlen müssen aussagekräftig sein und dürfen keine nominalen kategorialen Variablen sein, die als Ersatz für ein qualitatives Attribut dienen. Sie können beispielsweise keine Nummer willkürlich zuweisen und im Modell verwenden, wenn die Nummer keine Bedeutung hat (z. B. road quality = gut oder road quality = 4). Obwohl letzteres numerisch ist, ist es kein Maß für die Straßenqualität. Stattdessen können Sie die durchschnittliche Fahrgeschwindigkeit in Meilen pro Stunde als Proxy für die Straßenqualität verwenden. Ob die Durchschnittsgeschwindigkeit ein sinnvolles Maß für die Straßenqualität ist, müssen Sie als Autor der Studie bestimmen und verteidigen.
Wenn Sie es messen oder zählen können, können Sie es im Allgemeinen modellieren.
Nur vollständige Daten
Für jeden Point of Interest müssen alle Datenkategorien vorhanden sein. Das bedeutet, dass alle 32 untersuchten Landkreise über zuverlässige Daten für jeden Push- und Pull-Faktor verfügen müssen. Sie können keine Lücken oder Leerzeichen haben, z. B. einen Landkreis, in dem Sie nicht den Durchschnittslohn haben.
Nur zuverlässige Daten
Das Informatik-Sprichwort „Müll rein, Müll raus“ gilt auch für Gravitationsmodelle, die nur so zuverlässig sind wie die Daten, mit denen sie erstellt wurden. Neben der Auswahl robuster und zuverlässiger historischer Daten aus Quellen, denen Sie vertrauen können, gibt es viele Möglichkeiten, Fehler zu machen, die die Ausgaben Ihres Modells bedeutungslos machen. Es lohnt sich beispielsweise, sicherzustellen, dass die Daten, die Sie haben, genau mit den Gebieten übereinstimmen (z. B. Kreisdaten zur Darstellung von Landkreisen, keine Stadtdaten zur Darstellung eines Landkreises).
Je nach Zeit und Ort Ihrer Studie kann es schwierig sein, einen zuverlässigen Datensatz zu erhalten, auf dem Ihr Modell basieren kann. Je weiter man in der Vergangenheit studiert, desto schwieriger kann das sein. Ebenso kann es einfacher sein, diese Art von Analysen in Gesellschaften durchzuführen, die stark bürokratisch waren und eine gute überlebende Papierspur hinterließen, wie in Europa oder Nordamerika.
Um die Datenqualität in dieser Fallstudie sicherzustellen, wurde jede Variable entweder zuverlässig berechnet oder aus veröffentlichten, von Experten begutachteten historischen Daten abgeleitet (siehe Tabelle 1). Wie genau diese Daten zusammengestellt wurden, kann im Originalartikel nachgelesen werden, wo sie ausführlich erläutert wurden.11
Unsere fünf Modellvariablen
Unter Berücksichtigung der oben genannten Prinzipien hätten wir eine beliebige Anzahl von Variablen auswählen können, da wir über Migrations-Push- und Pull-Faktoren Bescheid wussten. Wir entschieden uns für fünf (5), die auf der Grundlage dessen ausgewählt wurden, was wir für am wichtigsten hielten und von denen wir wussten, dass sie mit zuverlässigen Daten gesichert werden konnten.
| Variable | Quelle |
|---|---|
| bevölkerung am Ursprung | 1771 Werte, Wrigley, „English County populations“, S. 54-5.12 |
| entfernung von London | berechnet mit Software |
| weizenpreis | Kanone und Hauptlast, „Wöchentliche britische Getreidepreise“13 |
| durchschnittliche Ursprungslöhne | Hunt, „Industrialization and Regional Inequality“, pp. 965-6.14 |
| Flugbahn der Löhne | Hunt, „Industrialisierung und regionale Ungleichheit“, pp. 965-6.15 |
Tabelle 1: Die fünf im Modell verwendeten Variablen und die Quelle jeder in der Peer-Review-Literatur
Nachdem der Co-Autor der ursprünglichen Studie, Adam Dennett, sich für diese Variablen entschieden hatte, beschloss er, die Formel neu zu schreiben, um sie selbst zu dokumentieren, so dass es leicht war zu sagen, welche Bits zu jeder dieser fünf Variablen gehörten. Aus diesem Grund sieht die oben gezeigte Formel anders aus als die in der ursprünglichen Forschungsarbeit. Die neuen Symbole sind in Tabelle 2 zu sehen:
Zwei zusätzliche Variablen $i $ und $j $ bedeuten „am Ursprungsort“ bzw. $ Wa_ {i} $ bedeutet „Lohnniveau am Ursprungsort“, während $ Wa_ {j} $ „Lohnniveau in London“ bedeuten würde. Diese sieben neuen Symbole können die allgemeineren in der Formel ersetzen:
\
Dies ist jetzt ausführlicher und eine leicht selbstdokumentierte Version der vorherigen Gleichung. Beide lösen mathematisch auf genau die gleiche Weise, da die Änderungen rein oberflächlich und zum Nutzen eines menschlichen Benutzers sind.
Der vollständige Variablendatensatz
Um das Tutorial schneller und einfacher zu vervollständigen, wurden die Daten für jede der 5 Variablen und jedes der 32 Counties bereits kompiliert und bereinigt und können in Tabelle 3 eingesehen oder als CSV-Datei heruntergeladen werden. Diese Tabelle enthält auch die bekannte Anzahl von Landstreichern aus diesem Landkreis, wie im primären Quelldatensatz beobachtet:
| Grafschaft | Landstreicher | $ d $ km nach London | $P $ Bevölkerung (Personen) | $Wa $ Durchschnittslohn (Schilling) | $ WaT $ Lohnentwicklung 1767-95 (Veränderung in%) | $ Wh $ Weizenpreis (Schilling) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornwalls | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Grafschaft Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
Der letzte Unterschied zwischen dieser Formel und der im Originalartikel verwendeten besteht darin, dass zwei der Variablen zufällig eine stärkere Beziehung zur Vagabundierung haben, wenn sie natürlich logarithmisch dargestellt werden. Sie sind Bevölkerung am Ursprung ($ P $) und Entfernung vom Ursprung nach London ($ d $). Dies bedeutet, dass für die Daten in dieser Studie die Regressionslinie (manchmal auch als Linie der besten Anpassung bezeichnet) besser passt, wenn die Daten protokolliert wurden, als wenn dies nicht der Fall war. Sie können dies in Abbildung 7 sehen, wobei die nicht protokollierten Bevölkerungszahlen links und die protokollierte Version rechts angezeigt werden. Im protokollierten Diagramm liegen mehr Punkte näher an der Linie der besten Anpassung als im nicht protokollierten Diagramm.
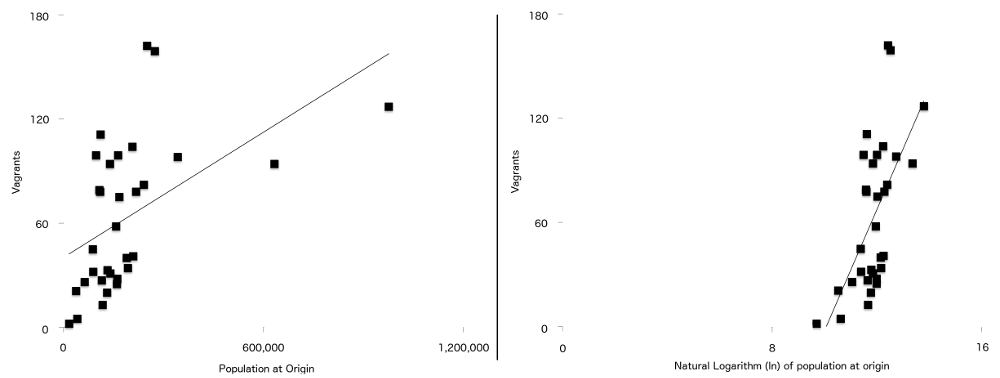
Abbildung 7: Anzahl der Vagabunden gegen die Population am Ursprung (links) und das natürliche Protokoll der Population am Ursprung (rechts) mit einer einfachen Regressionslinie, die auf beiden überlagert ist. Beachten Sie die stärkere Beziehung zwischen den beiden Variablen, die im zweiten Diagramm sichtbar ist.
Da dies bei diesen speziellen Daten der Fall ist (Ihre eigenen Daten in einer ähnlichen Art von Studie folgen möglicherweise nicht diesem Muster), wurde die Formel angepasst, um die natürlich protokollierten Versionen dieser beiden Variablen zu verwenden, was zu der endgültigen Formel führte, die im Gravitationsmodell verwendet wird (Abbildung 8). Wir konnten unmöglich über die Notwendigkeit dieser Anpassung Bescheid wissen, bis wir unsere variablen Daten gesammelt hatten:
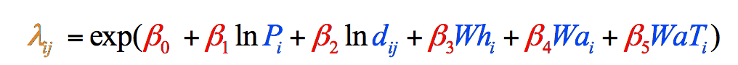
Abbildung 8: Die endgültige Formel des Gravitationsmodells, aufgeschlüsselt nach Schritten und farbcodiert. Elemente in Schwarz sind mathematische Operationen. Elemente in Blau repräsentieren unsere Variablen, die wir gerade gesammelt haben (Schritt 1). Elemente in Rot stellen die Gewichtungen jeder Variablen dar, die wir berechnen müssen (Schritt 2), und das Element in Orange ist die endgültige Schätzung der Landstreicher aus diesem Landkreis, die wir berechnen können, sobald wir die anderen Informationen haben (Schritt 3).
Die Werte in Tabelle 3 geben uns alles, was wir brauchen, um die blauen Teile jeder Gleichung in Abbildung 8 auszufüllen. Wir können jetzt unsere Aufmerksamkeit auf die roten Teile richten, die uns sagen, wie wichtig jede Variable im Modell insgesamt ist, und uns die Zahlen geben, die wir brauchen, um die Gleichung zu vervollständigen.
Schritt 2: Bestimmen der Gewichtungen
Die Gewichtungen für jede Variable geben an, wie wichtig dieser Push / Pull-Faktor im Verhältnis zu den anderen Variablen ist, wenn versucht wird, die Anzahl der Vagabunden zu schätzen, die aus einem bestimmten Landkreis stammen sollten. Die Parameter $β$ müssen über den gesamten Datensatz aus den bekannten Daten ermittelt werden. Mit diesen können wir einzelne ursprungsspezifische Beobachtungen mit dem allgemeinen Modell vergleichen. Wir können diese dann untersuchen und über- und unterprognostizierte Flüsse zwischen den verschiedenen Ursprüngen und dem Ziel identifizieren.
In diesem Stadium wissen wir nicht, wie wichtig jeder ist. Vielleicht ist der Weizenpreis ein besserer Prädiktor für Migration als die Entfernung? Wir werden es erst wissen, wenn wir die Werte von $ β1 $ bis $ β5 $ (die Gewichtungen) berechnen, indem wir die obige Gleichung lösen. Der y-Achsenabschnitt ($ β0 $) kann nur berechnet werden, wenn Sie alle anderen kennen ($ β1-β5 $). Dies sind die ROTEN Werte in Abbildung 8 oben. Die Gewichtungen sind der Tabelle 4 und der Tabelle A1 der Originalarbeit zu entnehmen.16 Wir werden nun zeigen, wie wir zu diesen Werten gekommen sind.
Um diese Werte mit der langen Hand zu berechnen, ist unglaublich viel Arbeit erforderlich. Wir werden eine schnelle Lösung in der Programmiersprache R verwenden, die das Massenpaket von William Venables und Brian Ripley nutzt, das negative binomiale Regressionsgleichungen wie unser Gravitationsmodell mit einer einzigen Codezeile lösen kann. Es ist jedoch wichtig, die Prinzipien hinter dem, was man tut, zu verstehen, um zu verstehen, was der Code tut (beachten Sie, dass die folgenden Abschnitte die Berechnung nicht durchführen, sondern die Schritte für Sie erklären; wir werden die Berechnung mit dem Code weiter unten auf der Seite durchführen).
Berechnung der einzelnen Gewichtungen (im Prinzip)
$ β_ {1} $, $ β_ {2} $ usw. sind die gleichen wie $ β $ im obigen einfachen linearen Regressionsmodell, das die Steigung der Regressionsgeraden ist (der Anstieg über den Lauf oder wie viel $ y $ zunimmt, wenn $ x $ um 1 zunimmt). Der einzige Unterschied zwischen einer einfachen linearen Regression und unserem Gravitationsmodell besteht darin, dass wir 5 Steigungen anstelle von 1 berechnen müssen.
Eine einfache lineare Regression\(y = α + ßx\)
Wir müssen für jede dieser fünf Steigungen lösen, bevor wir den y-Schnittpunkt im nächsten Schritt berechnen können. Das liegt daran, dass die Steigungen der verschiedenen $ β $ -Werte Teil der Gleichung zur Berechnung des y-Schnittpunkts sind.
Die Formel zur Berechnung von $ β $ in einer Regressionsanalyse lautet:
\
Pearson’s Correlation Coefficient
Pearson’s correlation coefficient kann mit langer Hand berechnet werden, aber es ist eine ziemlich lange Berechnung in diesem Fall, die 64 Zahlen erfordert. Es gibt einige große Video-Tutorials in englischer Sprache online verfügbar, wenn Sie einen Spaziergang durch sehen möchten, wie die Berechnungen lange Hand zu tun.17 Es gibt auch eine Reihe von Online-Taschenrechnern, die $ r $ für Sie berechnen, wenn Sie die Daten angeben. Angesichts der großen Anzahl zu berechnender Ziffern würde ich eine Website mit einem integrierten Tool für diese Berechnung empfehlen. Stellen Sie sicher, dass Sie eine seriöse Website auswählen, z. B. eine, die von einer Universität angeboten wird.
Berechnen von $s_{y} $ & $s_{x}$ (Standardabweichung)
Die Standardabweichung gibt an, wie viel Abweichung vom Mittelwert (Durchschnitt) in den Daten vorliegt. Mit anderen Worten, sind die Daten ziemlich um den Mittelwert gruppiert oder ist die Verbreitung viel breiter?
Auch hier gibt es Online-Rechner und statistische Softwarepakete, die diese Berechnung für Sie durchführen können, wenn Sie die Daten bereitstellen.
Berechnung von $β_{0}$ (der y-Achsenabschnitt)
Als nächstes müssen wir den y-Achsenabschnitt berechnen. Die Formel zur Berechnung des y-Schnittpunkts in einer einfachen linearen Regression lautet:
\
Die Berechnung wird jedoch in einer multiplen Regressionsanalyse viel komplizierter, da jede Variable die Berechnung beeinflusst. Dies macht es sehr schwierig, dies von Hand zu tun, und ist einer der Gründe, warum wir uns für eine programmatische Lösung entscheiden.
Der Code zur Berechnung der Gewichtungen
Das für die Programmiersprache R geschriebene statistische Massenpaket verfügt über eine Funktion, mit der negative binomiale Regressionsgleichungen gelöst werden können.
In diesem Abschnitt wird davon ausgegangen, dass Sie R und das Massenpaket installiert haben. Wenn Sie dies nicht getan haben, müssen Sie, bevor Sie fortfahren. Taryn Dewars Tutorial zu R-Grundlagen mit tabellarischen Daten enthält R-Installationsanweisungen.
Um diesen Code zu verwenden, müssen Sie eine Kopie des Datensatzes der fünf Variablen sowie die Anzahl der beobachteten Vagabunden aus jedem der 32 Landkreise herunterladen. Dies ist oben als Tabelle verfügbar 3, oder kann als heruntergeladen werden .csv-Datei. Speichern Sie die Datei unabhängig vom gewählten Modus als VagrantsExampleData .csv. Wenn Sie einen Mac verwenden, stellen Sie sicher, dass Sie ihn als Windows-Format speichern .csv-Datei. Öffnen Sie VagrantsExampleData.csv und machen Sie sich mit den Inhalten vertraut. Sie sollten jede der 32 Grafschaften zusammen mit jeder der Variablen beachten, die wir in diesem Tutorial besprochen haben. Wir werden die Spaltenüberschriften verwenden, um mit unserem Computerprogramm auf diese Daten zuzugreifen. Ich hätte sie alles nennen können, aber in dieser Datei sind sie:
vagrantspopulationdistancewheatwageswageTrajectory
Erstellen und speichern Sie im selben Verzeichnis, in dem Sie die CSV-Datei gespeichert haben, eine neue R-Skriptdatei (Sie können dies mit einem beliebigen Texteditor oder mit RStudio tun, verwenden Sie jedoch kein Textverarbeitungsprogramm wie MS Word). Speichern Sie es als weightingsCalculations .r.
Wir werden nun ein kurzes Programm schreiben, das:
- Installiert das Massenpaket
- Ruft das Massenpaket auf, damit wir es in unserem Code verwenden können
- Speichert den Inhalt des .CSV-Datei in eine Variable, die wir programmgesteuert verwenden können
- Löst die Gravitationsmodellgleichung mit dem Datensatz
- Gibt die Ergebnisse der Berechnung aus.
Jede dieser Aufgaben wird nacheinander mit einer einzigen Codezeile gelöst
Kopieren Sie den obigen Code in Ihre Gewichtsberechnungen.r-Datei und speichern. Sie können den Code jetzt in Ihrer bevorzugten R-Umgebung ausführen (ich verwende RStudio) und die Ergebnisse der Berechnung sollten im Konsolenfenster angezeigt werden (wie dies aussieht, hängt von Ihrer Umgebung ab). Möglicherweise müssen Sie das Arbeitsverzeichnis Ihrer R-Umgebung auf das Verzeichnis festlegen, das Ihre enthält.csv und .r-Dateien. Wenn Sie RStudio verwenden, können Sie dies über die Menüs tun (Sitzung -> Arbeitsverzeichnis festlegen -> Verzeichnis auswählen). Sie können dasselbe auch mit dem Befehl erreichen:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundBeachten Sie, dass Zeile 4 die Zeile ist, die die Gleichung für uns mithilfe des glm löst.nb-Funktion, kurz für „generalized linear model – negative binomial“. Diese Zeile erfordert eine Reihe von Eingängen:
- unsere Variablen verwenden die Spaltenüberschriften wie in der .csv-Datei, zusammen mit jeder Protokollierung, die mit ihnen durchgeführt werden muss (
vagrants, log(population), log(distance),wheat,wages,wageTrajectory). Wenn Sie ein Modell mit Ihren eigenen Daten ausführen würden, würden Sie diese anpassen, um Ihre Spaltenüberschriften in Ihrem Dataset widerzuspiegeln. - wo der Code die Daten finden kann – in diesem Fall eine Variable, die wir in Zeile 3 definiert haben, genannt
gravityModelData.
Die Ergebnisse der Berechnung sind in Abbildung zu sehen 9:
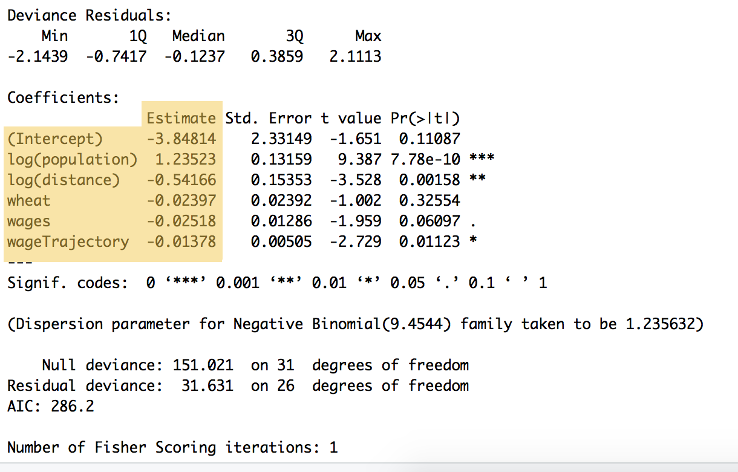
Abbildung 9: Die Zusammenfassung des obigen Codes, die die Gewichtungen für jede Variable und den y-Achsenabschnitt zeigt, aufgelistet unter der Überschrift ‚Schätzung‘ ($\beta_{0} $ bis $ \beta_{5} $. Diese Zusammenfassung zeigt auch eine Reihe anderer Berechnungen, einschließlich der statistischen Signifikanz.
Schritt 3: Berechnung der Schätzungen für jede Grafschaft
Wir müssen dies einmal für jede der 32 Grafschaften tun.
Sie können dies mit einem wissenschaftlichen Taschenrechner tun, indem Sie eine Tabellenkalkulationsformel erstellen oder ein Computerprogramm schreiben. Um dies automatisch in R zu tun, können Sie Ihrem Code Folgendes hinzufügen und das Programm erneut ausführen. Diese for -Schleife berechnet die erwartete Anzahl von Vagabunden aus jedem der 32 Landkreise im Beispiel und druckt die Ergebnisse aus, damit Sie sie sehen können:
Um das Verständnis zu verbessern, schlage ich vor, eine Grafschaft mit langer Hand auszuführen. Dieses Tutorial wird Hertfordshire als Long-Hand-Beispiel verwenden (aber der Prozess ist genau das gleiche für die anderen 31 Grafschaften).
Mit den Daten für Hertfordshire in Tabelle 3 und den Gewichtungen für jede Variable in Tabelle 4 können wir nun unsere Formel vervollständigen, die das Ergebnis von 95 ergibt:
Tauschen wir zunächst die Symbole gegen die Zahlen aus den oben genannten Tabellen aus.
Beginnen Sie dann mit der Berechnung der Werte, um zur Schätzung zu gelangen. Erinnern mathematische Reihenfolge der Operationen, multiplizieren Werte vor dem Hinzufügen. Beginnen Sie also mit der Berechnung jeder Variablen (Sie können dafür einen wissenschaftlichen Taschenrechner verwenden):
Der nächste Schritt besteht darin, die Zahlen zu addieren:
estimated vagrants = exp(4.56232408897)Und schließlich, um die Exponentialfunktion zu berechnen (verwenden Sie einen wissenschaftlichen Taschenrechner):
estimated vagrants = 95.8059926832Wir haben den Rest fallen gelassen und erklärt, dass die geschätzte Anzahl von Landstreichern aus Hertfordshire in diesem Modell 95 beträgt. Sie müssen für jedes der anderen Länder dieselben Berechnungen durchführen, die Sie mit einem Tabellenkalkulationsprogramm beschleunigen können. Nur um sicherzustellen, dass Sie es wieder tun können, habe ich auch die Zahlen für Buckinghamshire aufgenommen:
Hertfordshire
\
Buckinghamshire
\
Ich empfehle, eine andere Grafschaft auszuwählen und sie lange zu berechnen, bevor Sie fortfahren, um sicherzustellen, dass Sie die Berechnungen selbst durchführen können. Die richtige Antwort finden Sie in Tabelle 5, in der die beobachteten Werte (wie im primären Quelldatensatz angegeben) mit den geschätzten Werten (wie von unserem Gravitationsmodell berechnet) verglichen werden. Der „Rest“ ist der Unterschied zwischen den beiden, wobei ein großer Unterschied auf eine unerwartete Anzahl von Landstreichern hindeutet, die einen genaueren Blick mit dem Hut des Historikers wert sein könnten.
| Grafschaft | Beobachteter Wert | Geschätzter Wert | Restwert | |||
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 | |||
| Berkshire | 111 | 76 | 35 | |||
| Buckinghamshire | 79 | 83 | -4 | |||
| Cambridgeshire | 32 | 48 | -16 | |||
| Cheshire | 34 | 44 | -10 | |||
| Cornwalls | 40 | 42 | -2 | |||
| Cumberland | 13 | 21 | -8 | |||
| Derbyshire | 28 | 36 | -8 | |||
| Devon | 98 | 121 | -23 | |||
| Dorset | 27 | 36 | -9 | |||
| Durham | 25 | 31 | -6 | |||
| Gloucestershire | 162 | 123 | 39 | |||
| Hampshire | 78 | 92 | -14 | |||
| Herefordshire | 45 | 39 | 6 | |||
| Hertfordshire | 99 | 95 | 4 | |||
| Huntingdonshire | 21 | 18 | 3 | |||
| Lancashire | 94 | 84 | 10 | |||
| Leicestershire | 20 | 28 | -8 | |||
| Grafschaft Lincolnshire | 41 | 86 | -45 | |||
| Northamptonshire | 33 | 78 | -45 | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 | |||
| Oxfordshire | 78 | 52 | 26 | |||
| Rutland | 2 | 4 | -2 | |||
| Shropshire | 75 | 66 | 9 | |||
| Somerset | 159 | 145 | 14 | |||
| Staffordshire | 82 | 85 | -3 | |||
| Warwickshire | 104 | 70 | 34 | |||
| Westmorland | 5 | 5 | 0 | |||
| Wiltshire | 99 | 95 | 4 | |||
| Worcestershire | 94 | 53 | 41 | |||
| Yorkshire | 127 | 207 | -80 |
Schritt 4 – Historische Interpretation
In diesem Stadium ist der Modellierungsprozess abgeschlossen und die letzte Stufe ist die historische Interpretation.
Der ursprünglich veröffentlichte Artikel, auf dem diese Fallstudie basierte, widmet sich in erster Linie der Interpretation dessen, was die Ergebnisse der Modellierung für unser Verständnis der Migration der unteren Klassen im achtzehnten Jahrhundert bedeuten. Wie auf der Karte in Abbildung 5 zu sehen ist, gab es Teile des Landes, von denen das Modell stark annahm, dass sie entweder Migranten der unteren Klasse nach London schickten.
Die Co-Autoren boten ihre Interpretationen an, warum diese Muster aufgetreten sein könnten. Diese Interpretationen variierten je nach Ort. In Gebieten im Norden Englands, die sich rasch industrialisierten, wie Yorkshire oder Manchester, schienen die Möglichkeiten vor Ort den Menschen weniger Gründe zu geben, zu gehen, was zu einer geringeren als erwarteten Migration nach London führte. In rückläufigen Gebieten im Westen, wie Bristol, Die Verlockung Londons war stärker, als mehr Menschen in der Hauptstadt Arbeit suchten.
Nicht alle Muster wurden erwartet. Northumberland im äußersten Nordosten erwies sich als regionale Anomalie und schickte weit mehr (weibliche) Migranten nach London, als wir erwarten würden. Ohne die Ergebnisse des Modells, Es ist unwahrscheinlich, dass wir Northumberland überhaupt in Betracht gezogen hätten, vor allem, weil es so weit von der Metropole entfernt war und wir vermuteten, dass es schwache Beziehungen zu London haben würde. Das Modell lieferte somit neue Beweise für uns als Historiker und veränderte unser Verständnis der Beziehung zwischen London und Northumberland. Eine vollständige Diskussion unserer Ergebnisse finden Sie im Originalartikel.18
Ihr Wissen voranbringen
Nachdem Sie dieses Beispielproblem ausprobiert haben, sollten Sie ein klares Verständnis dafür haben, wie Sie diese Beispielformel verwenden und ob ein Gravitationsmodell eine geeignete Lösung für Ihr Forschungsproblem darstellt oder nicht. Sie verfügen über die Erfahrung und das Vokabular, um Gravitationsmodelle bei Bedarf mit einem entsprechend mathematisch versierten Mitarbeiter anzugehen und zu diskutieren, der Ihnen helfen kann, sie an Ihre eigene Fallstudie anzupassen.
Wenn Sie das Glück haben, auch Daten über Migranten zu haben, die nach London des späten achtzehnten Jahrhunderts ziehen, und Sie möchten es mit den gleichen fünf Variablen modellieren, die oben aufgeführt sind, würde diese Formel so funktionieren, wie sie ist – es gibt eine einfache Studie hier für jemanden mit den richtigen Daten. Dieses Modell funktioniert jedoch nicht nur für Studien über Migranten, die nach London ziehen. Die Variablen können sich ändern, und das Ziel muss nicht geändert werden. Es wäre möglich, ein Gravitationsmodell zu verwenden, um die Migration ins antike Rom oder Bangkok des einundzwanzigsten Jahrhunderts zu untersuchen, wenn Sie die Daten und die Forschungsfrage haben. Es muss nicht einmal ein Migrationsmodell sein. Um die kolumbianische Kaffeefallstudie aus der Einleitung zu verwenden, die sich eher auf Handel als auf Migration konzentriert, zeigt Tabelle 6 eine praktikable Verwendung derselben Formel, unverändert.
| Kriterien | Kaffeeexportbeispiel |
|---|---|
| EIN Ursprungsort | Kaffeeexporte aus dem Hafen von Barranquilla, Kolumbien |
| MEHRERE endliche Ziele | die 21 Länder der westlichen Hemisphäre in 1950 |
| FÜNF erklärende Variablen | (1) Anzahl der Atlantikhäfen im Empfängerland (2) Meilen von Kolumbien entfernt, (3) Bruttoinlandsprodukt des Empfängerlandes, (4) Inländischer Kaffee in Tonnen, (5) Coffeeshops pro 10.000 Einwohner |
Es gibt eine lange Geschichte von Gravitationsmodellen in der akademischen Wissenschaft. Um eine effektiv für die Forschung zu verwenden, müssen Sie die grundlegende Theorie und Mathematik dahinter und die Gründe verstehen, warum sie sich so entwickelt haben. Es ist auch wichtig, ihre Grenzen und Bedingungen für ihre ordnungsgemäße Verwendung zu verstehen, von denen einige oben erörtert wurden. Es könnte auch helfen zu wissen:
-
Ein Gravitationsmodell wie das in diesem Beispiel verwendete kann nur in einem geschlossenen System funktionieren. Das obige Modell hatte nur 32 mögliche Ursprungspunkte, so dass das Modell 32 Mal ausgeführt werden konnte. Eine unbekannte oder unendlich große Anzahl von Ursprungspunkten (oder Zielen je nach Modell) würde eine andere Gleichung erfordern.
-
Das Gravitationsmodellkonzept basiert auch auf der Prämisse, dass Bewegungen (Migration, Handel usw.) auf einer Sammlung freiwilliger individueller Entscheidungen basieren, die von externen Faktoren beeinflusst werden können, aber nicht vollständig von ihnen kontrolliert werden. Zum Beispiel könnten freiwillige Migrationen oder Käufe aus freiem Willen mit dieser Technik modelliert werden, aber Zwangsmigration, Zwangskauf oder natürliche Prozesse wie Vogelzug oder Flussfluss folgen möglicherweise nicht denselben Prinzipien und daher kann eine andere Art von Modell erforderlich sein.
-
Gravitationsmodelle können verwendet werden, um das Verhalten von Populationen, aber nicht von Individuen vorherzusagen, und daher sollten Versuche, Daten zu modellieren, eine große Anzahl von Bewegungen umfassen, um statistische Signifikanz sicherzustellen.
Es gibt viele weitere Fallstricke, aber auch enorme Möglichkeiten. Ich hoffe, dass diese Begehung eines Gravitationsmodells und die dazugehörige veröffentlichte Forschung dieses mächtige Werkzeug für Historiker zugänglicher machen wird. Wenn Sie planen, ein Gravitationsmodell in Ihrer wissenschaftlichen Forschung zu verwenden, empfiehlt der Autor dringend die folgenden Artikel:
Danksagung
Mit Dank an Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas und Leanne Calvert für das Lesen und Kommentieren früherer Entwürfe dieses Artikels. Vielen Dank auch an die British Academy für die Finanzierung des Schreibworkshops in Bogotá, Kolumbien, bei dem dieser Artikel verfasst wurde. Und schließlich an Adam Dennett, der mir diese wunderbaren Formeln vorgestellt und ihr Potenzial für Historiker entfesselt hat.