Datenbanken? Nicht sehr interessant.
So könnte eine durchschnittliche Person, die mit GIS oder Datenvisualisierungen arbeitet, denken. Ich muss zugeben, dass Datenbanken nicht die sexieste Sache der Welt sind (sorry DBAs), aber wenn Sie behaupten (oder darauf abzielen), Analysen oder Visualisierungen mit (räumlichen) Daten auf ernstere Weise durchzuführen, sollten Sie sie definitiv nicht ignorieren. Ich hoffe, dieser Blogbeitrag kann Ihnen eine Vorstellung davon geben, welche Vorteile Ihnen die effiziente Nutzung räumlicher Datenbanken bieten könnte.
Hype Begriffe kommen und gehen in der IT und es gab noch vor ein paar Jahren einen großen Hype um Big Data, aber der schwindet nun langsam. Nun, Daten sind immer noch groß und tatsächlich größer als je zuvor. Dateigrößen wachsen und in „Data Science“ und Geowissenschaften muss man sich mit Daten beschäftigen, die leicht im Gigabyte-Bereich liegen können. Je größer die Daten sind, desto mehr Aufmerksamkeit müssen wir der Art und Weise widmen, wie wir sie speichern und analysieren.
Hier kommt eine Datenbank ins Spiel.
In der Softwareentwicklung ist die Arbeit mit Datenbanken ein Muss. Aber für Menschen in anderen Subdomänen der Informatik (wie GIS) sind die Vorteile einer Datenbank möglicherweise nicht immer so offensichtlich. Natürlich neigen die Menschen dazu, die ihnen vertrautesten Tools zu verwenden, obwohl dies nicht der effizienteste Weg wäre, um Ziele zu erreichen. Aber manchmal kann das Verlassen Ihrer Komfortzone Ihnen wirklich große Vorteile bringen. Ich habe selbst langsam das Potenzial erkannt, das in räumlichem SQL liegt.

Dieser Blogbeitrag richtet sich hauptsächlich an Personen, die mit Geodaten arbeiten, aber PostGIS noch nicht berührt haben oder vielleicht noch nicht einmal davon gehört haben. Ich werde nicht durchgehen, wie man PostgreSQL / PostGIS installiert, sondern versuchen, Ihnen einen Überblick darüber zu geben, was es ist und wofür es gut ist.
Mein Workflow und meine Beispiele konzentrieren sich hauptsächlich auf die Kombination QGIS + PostGIS, aber Sie sollten beachten, dass Sie auch nur mit PostGIS, Ihrem eigenen Code oder mit einigen anderen GIS-Clients arbeiten können.
Beitrag… was?
Schon während meines GIS-Studiums hatte ich mehrfach den Satz ‚PostGIS ist eine räumliche Erweiterung von Postgres‘ gehört. Es bedeutete nicht, dass ich eine Ahnung hatte, was das bedeutet. Ich hatte keine Ahnung, was Postgres ist, geschweige denn eine räumliche Erweiterung.
Versuchen wir es so einfach wie möglich zu bremsen.
Einige Leute mögen mich für diesen Vergleich hassen, aber ich gehe das Risiko ein: Wenn Sie noch nie mit Datenbanken gearbeitet haben, können Sie sich Datenbanktabellen als massive Excel-Tabellen vorstellen. Aber ein massives intelligentes Excel-Blatt, von dem aus Sie in einer Millisekunde herausfinden können, welcher Wert in der dritten Spalte der Zeilennummer 433 285 steht. Anstatt Funktionen innerhalb des Arbeitsblatts in eine einzelne Zelle zu schreiben, schreiben Sie sie in Ihr SQL-Befehlsfenster. Also ein Ort, an dem Sie Daten speichern und von wo aus Sie effizient abgerufen werden können.
PostGIS ist ein Open Source, frei verfügbarer Spatial Database Extender für das PostgreSQL Database Management System (auch bekannt als DBMS). PostgreSQL (auch bekannt als Postgres) ist also DIE Datenbank und PostGIS ist wie ein Add-On zu dieser Datenbank. Die neueste Version von PostGIS wird jetzt mit PostgreSQL geliefert.
Kurz gesagt, PostGIS fügt PostgreSQL räumliche Funktionen wie Entfernung, Fläche, Vereinigung, Schnittpunkt und spezielle Geometriedatentypen hinzu.Räumliche Datenbanken speichern und bearbeiten räumliche Objekte wie jedes andere Objekt in der Datenbank.
In einer normalen Datenbank speichern Sie also Daten verschiedener Typen (numerisch, Text, Zeitstempel, Bilder …) und können diese bei Bedarf abfragen (abrufen), um Fragen mit Ihren Daten zu beantworten. Die Fragen können sein, wie viele Personen sich auf Ihrer Website angemeldet haben oder wie viele Transaktionen in einem Online-Shop getätigt wurden. Räumliche Funktionen können stattdessen Fragen beantworten wie ‚wie nah ist das nächste Geschäft‘, ‚Ist dieser Punkt in diesem Bereich‘ oder ‚Wie groß ist dieses Land‘.
Die Daten werden also in Zeilen und Spalten gespeichert. Da es sich bei PostGIS um eine räumliche Datenbank handelt, verfügen die Daten auch über eine Geometriespalte mit Daten in einem bestimmten Koordinatensystem, das durch Spatial Reference Identifier (SRID) definiert ist. Aber denken Sie daran, dass, obwohl Sie PostGIS hauptsächlich für räumliche Daten verwenden würden, es auch möglich ist, nicht-räumliche Daten dort zu speichern, da es immer noch alle Funktionen einer normalen PostgreSQL-Datenbank hat!
Das ausgezeichnete Boundless PostGIS Intro stellt drei Kernkonzepte vor, die räumliche Daten mit einer Datenbank verknüpfen. Kombiniert bieten diese eine flexible Struktur für optimierte Leistung und Analyse.
- Räumliche Datentypen wie Punkt, Linie und Polygon. Den meisten vertraut, die mit räumlichen Daten arbeiten;
- Die mehrdimensionale räumliche Indizierung wird für die effiziente Verarbeitung räumlicher Operationen verwendet;
- Räumliche Funktionen, die in SQL bereitgestellt werden, dienen zum Abfragen räumlicher Eigenschaften und Beziehungen.
SQL oder „Structured Query Language“ ist ein Mittel, um Fragen zu stellen und Daten in relationalen Datenbanken zu aktualisieren. Eine Select-Abfrage (mit der Sie die Fragen stellen) ist im Allgemeinen ein Befehl der folgenden Form
SELECT some_columns FROM some_data_source WHERE some_condition;
PostGIS-spezifische Funktionen haben normalerweise die Form ST_functionName .
Sie schreiben diese Befehle in der Befehlszeile, nachdem Sie sich in Ihrer Datenbank oder in Ihrem Datenbank-GUI-Tool (z. B. pgAdmin oder QGIS DB Manager) angemeldet haben. Also ja, SQL erfordert, dass Sie wirklich etwas schreiben. Das Klicken mit der rechten Maustaste wird im Allgemeinen möglicherweise unterschätzt, aber für jemanden, der keinen Code schreibt, ist SQL ein guter erster Schritt, um eigene Befehle und möglicherweise späteren Code zu schreiben.
Neben PostGIS gibt es noch andere räumliche Datenbanken. SQL Server Spatial, ESRI ArcSDE, Oracle Spatial und GeoMesa sind einige weitere Optionen zum Verwalten und Analysieren räumlicher Daten. PostGIS soll jedoch mehr Funktionen und allgemein eine bessere Leistung bieten. Auch die anderen genannten (außer GeoMesa) sind nicht Open Source.
Wenn Sie neu in diesem Bereich sind, könnten Sie jetzt verwirrt sein: es ist also ein Ort zum Speichern von Daten und Sie müssen Informationen auf komplexe Weise abrufen, indem Sie seltsame Dinge in die Befehlszeile schreiben? Warte darauf. Es gibt auch einige echte Vorteile, die PostGIS Ihnen bieten kann, wenn Sie sich wirklich dazu verpflichten.
Ich habe einige Ideen für den Blogbeitrag von Twitter angefordert und viel gutes Feedback erhalten. Von dort kam mir die Idee, dies in zwei Teile zu teilen. Im ersten Teil werde ich auf die Vorteile eingehen, die PostGIS für Ihre tägliche Arbeit bringen kann. Im zweiten Teil werde ich mich mehr auf Spatial SQL konzentrieren.
PostGIS ermöglicht Ihnen eine neue Arbeitsweise. Dieser neue Weg kann leichter reproduzierbar sein, Sie können die Versionskontrolle einfacher verwenden und Mehrbenutzer-Workflows ermöglichen.
Dateien erfordern oft spezielle Software zum Lesen und Schreiben. SQL ist eine Abstraktion für den zufälligen Datenzugriff und die Analyse. Ohne diese Abstraktion benötigen Sie entweder eine bestimmte Software, um die Vorgänge auszuführen, oder Sie müssen den gesamten Zugriffs- und Analysecode selbst schreiben.
Wenn Sie Ihre Analyse in SQL durchführen, anstatt nur zufällige Operationen für Dateien mit einigen zufälligen Tools mit zufälligen Parametern durchzuführen, können Sie Ihre Ergebnisse einfacher freigeben und reproduzieren. Möglicherweise haben Sie dieses eine „Master-Shapefile“ derzeit irgendwo, wo Sie mehrere räumliche Verknüpfungen und Clipoperationen zu einem Shapefile vorgenommen haben, damit es so ist, wie es sein soll. Was, wenn das verschwindet?
Johnnie hat auf Twitter ein gutes Beispiel dafür geschrieben, wie er versehentlich alle seine Daten gelöscht hat, sie aber mit minimalem Aufwand mit den SQL-Skripten, die er in GIT gespeichert hat, reproduzieren konnte.
Menschen, die mit Softwareentwicklung arbeiten, sind wahrscheinlich (oder hoffentlich) mit Versionskontrolle vertraut. Ich werde in diesem Blogbeitrag nicht näher darauf eingehen, aber Sie können (und sollten) Ihre SQL-Skripte in einem Versionskontrollsystem wie GIT haben. Betrachten Sie es als ein Kochbuch, das Sie in Ihrem Bücherregal aufbewahren und ständig aktualisieren, um immer die besten Rezepte für eine leckere Datenanalyse zu finden. Nur dass Sie ein neues Exemplar dieses genauen Kochbuchs bei Amazon wieder kaufen können, wenn Ihr Haus niederbrennt.
Eine Datenbank kann Ihnen auch dabei helfen, Ihre Geodaten besser zu ordnen. Keiner von uns ist wirklich perfekt und wahrscheinlich werden Sie immer noch Tabellen wie temp_1 , final_final erstellen, aber eine Datenbank bietet Ihnen immer noch eine bessere Möglichkeit, Ihre Datenstruktur zu standardisieren als nur Dateien (z. B. durch Standardisierung der Datentypen in Ihren Tabellen).
Und was ist mit diesen großen Datensätzen? Mit einer räumlichen Datenbank wird das Arbeiten mit großen Datensätzen möglich. Nicht nur einfacher, aber manchmal ist es fast unmöglich, an größeren Datensätzen ohne Datenbank zu arbeiten. Haben Sie jemals versucht, 2 GB CSV-Datei zu öffnen? Oder versucht, eine Geoverarbeitung für einen 800 MB GeoJSON durchzuführen? Wussten Sie überhaupt, dass Shapefiles eine Größenbeschränkung haben? Natürlich können Sie einige dieser Probleme mit Geopackage oder anderen Dateiformaten angehen, aber im Allgemeinen ist PostGIS das optimale Werkzeug für den Umgang mit großen (Geodaten-) Daten.

Eine sehr nette Funktion bei Datenbanken ist, dass Sie Prozesse, die Sie normalerweise manuell ausführen, einfacher automatisieren können. Wenn Sie beispielsweise die PostgreSQL-Benachrichtigungsfunktion verwenden, können Sie Ihre QGIS-Karten automatisch aktualisieren. Auch wenn Sie mit ETL-Tools (z. B. FME) arbeiten, um Ihre Arbeit zu automatisieren, ist das Lesen / Schreiben von / in PostGIS-Tabellen viel einfacher als mit Dateien.
Wenn du nicht wie ich bist (ich mache das momentan alleine und zum Spaß), hast du vielleicht ein Ding namens Team. Auch bekannt als Co-Worker. Möglicherweise müssen sie auf dieselben Daten zugreifen wie Sie. Die Verwendung einer Datenbank in Ihrem Workflow ermöglicht das parallele Arbeiten auf einer anderen Ebene als nur Dateien auf einem freigegebenen Laufwerk.
Ein Hauptgrund dafür ist, dass gleichzeitige Benutzer Korruption verursachen können. Es ist zwar möglich, zusätzlichen Code zu schreiben, um sicherzustellen, dass mehrere Schreibvorgänge in dieselbe Datei die Daten nicht beschädigen, aber wenn Sie das Problem und auch das damit verbundene Leistungsproblem gelöst haben, hätten Sie den besseren Teil eines Datenbanksystems geschrieben.
Natürlich gibt es sowohl Vor- als auch Nachteile bei der Einführung eines neuen Workflows. Genau wie Ihre Dateien in Ordnung zu halten, kann am Ende des Tages auch die Pflege einer Datenbank eine Menge Arbeit sein. Zum Beispiel kann das Aktualisieren Ihres PostGIS auf eine neue Version ein echter Schmerz sein, wie es auf Twitter hervorgehoben wurde. Mit großer Macht kommt große Verantwortung.
Aber lassen Sie uns mehr über diesen Leistungsteil sprechen.
Teil 2: Die magische Welt von Spatial SQL
Spatial SQL kann Ihre Verarbeitung wirklich beschleunigen (wenn Sie mit Bedacht verwendet werden). Nachfolgend finden Sie einen Vergleich zwischen dem Ausführen desselben Prozesses mit einem Shapefile und der QGIS-Verarbeitung und dann in PostGIS mit ST_GeneratePoints.

Für diesen Vergleich hatte ich Postleitzahlendaten aus Finnland und die Bevölkerung in jedem Postleitzahlengebiet. Ich hatte dies sowohl als Shapefile als auch als Tabelle in meiner lokalen Datenbank. Ich habe zufällige Punkte in jedem Polygon erstellt, um die Population darzustellen. Ich habe die QGIS-Verarbeitung (zufällige Punkte innerhalb des Polygons aus der Vektorverarbeitung) für das Shapefile verwendet und in PostGIS war die SQL wirklich so einfach:
SELECT ST_GeneratePoints(geom, he_vakiy) from paavo.paavo
Wie Sie der obigen Grafik entnehmen können, benötigte PostGIS im Vergleich zu QGIS und einem Shapefile weniger als 10% der Zeit, um dieselbe Analyse durchzuführen. Wenn Sie ein GIS-Analyst sind und solche Prozesse jeden Tag durchführen, können Sie in einem Jahr viel Zeit sparen.
Neben der schnelleren Verarbeitung können Sie die große Auswahl an räumlichen Funktionen genießen, die PostGIS zu bieten hat. Welche Funktionen für Sie am nützlichsten sind, hängt ganz vom Anwendungsfall ab. Zusätzlich zur Voronoi-Analyse und traditionelleren GIS-Analyse (Buffer, Overlay, Intersect, Clip usw..) Sie können fortgeschrittenere Dinge tun:
- Routing. Mit pgRouting- und Straßendaten können Sie optimale Routen finden und verschiedene Netzwerkanalysen durchführen.
- Polygonskelettierung. Mit dieser Funktion können Sie die Mittelachse eines Polygons im laufenden Betrieb erstellen;
- Geometrieunterteilung. Die Aufteilung Ihrer Geometrien für die weitere Verarbeitung kann Ihre Prozesse erheblich beschleunigen;
- Clustering. Finden Sie Cluster und Muster aus Ihren Daten. Mit dem KI-Hype auf dem Höhepunkt, Die k-Means könnten für einige noch interessanter sein als zuvor…
Wofür brauchst du Sachen wie Polygonskelettierung? Könnte eine gültige Frage für die meisten sein, aber das eine Mal, wenn Ihre räumliche Analyse es braucht, werden Sie sehr erfreut sein, dass jemand die harte Arbeit (= Mathematik) für Sie getan hat. Durch die Kombination verschiedener räumlicher Funktionen und die Verwendung der in Postgres integrierten Funktionen können Sie erweiterte räumliche Analysen in Ihrer Datenbank durchführen.
Komplizierte und interessante Fragen (räumliche Verknüpfungen, Aggregationen usw.), die in einer SQL-Zeile in der Datenbank ausgedrückt werden können, erfordern viel Rechenleistung, und das bietet Ihnen PostGIS. Wenn Sie dieselben Fragen mit Ihrem eigenen Code beantworten, sind möglicherweise Hunderte von Zeilen speziellen Codes erforderlich, um sie beim Programmieren gegen Dateien zu beantworten.
PostGIS für dataviz
In vielen der Visualisierungen, die ich in meinem Portfolio habe, hat PostGIS eine Art Rolle im Visualisierungsprozess gespielt. In meinem Workflow verarbeite ich meistens die Daten vor und mache dann die eigentliche Visualisierung in QGIS.
Sehen wir uns ein Beispiel für einen dieser Prozesse an.
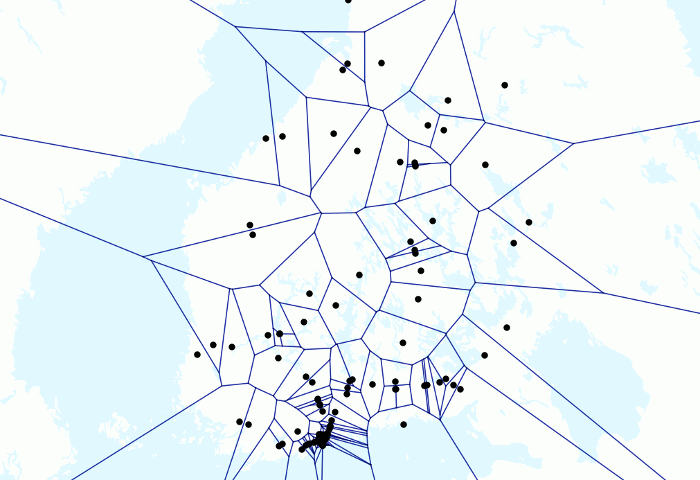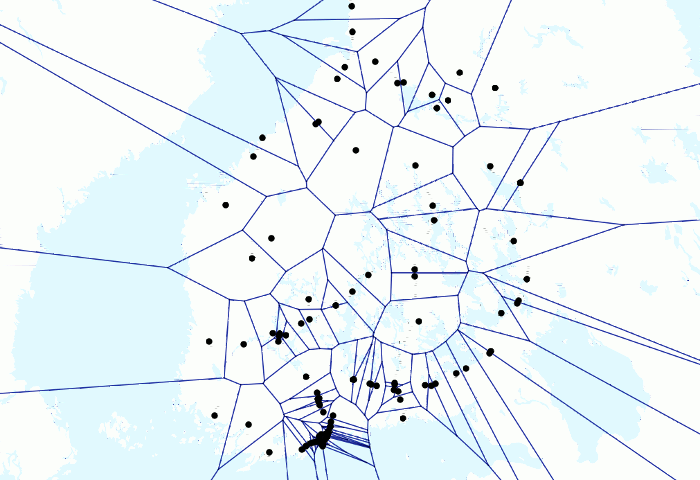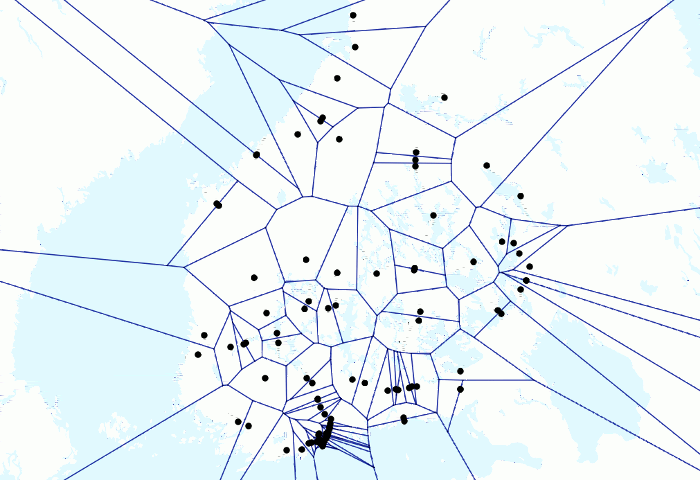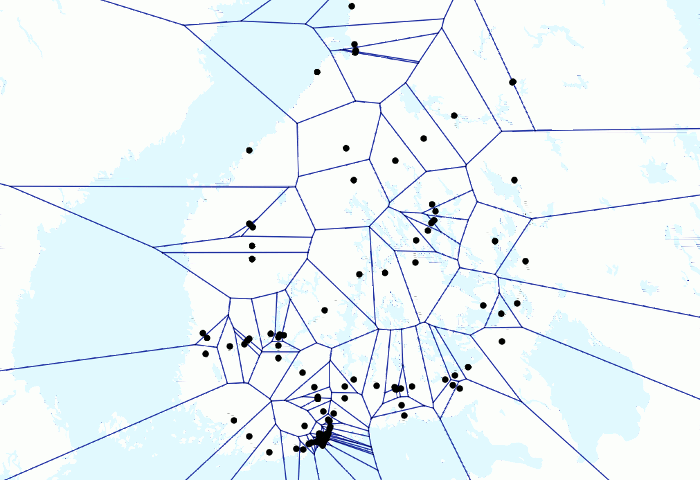
Animation über Züge und Voronois oben geben ein spielerisches Beispiel für die Leistung von PostGIS. Ich hatte ein paar Millionen Zug-GPS-Punkte in meiner lokalen Datenbank und hatte bereits Animationen erstellt, bei denen sich die Punkte nur bewegten. Aber ich wollte testen, wie eine Animation mit Voronoi-Linien aussehen würde.
Da ich zunächst mehrere GPS-Punkte für jeden Zug pro Minute hatte, wollte ich sie so gruppieren, dass ich für jede Minute pro Zug einen repräsentativen Punkt habe. Ich hatte zuerst manuell eine Tabelle für die resultierenden Punkte erstellt. Ich habe die folgende Abfrage geschrieben
INSERT INTO trains.voronoipoints
SELECT '2018–01–15 09:00:00' AS t,
geom
FROM (SELECT St_centroid(St_collect(geom)) AS geom,
trainno
FROM (SELECT geom,
trainno
FROM trains.week
WHERE time > '2018–01–15 09:00:00'
AND time < '2018–01–15 09:01:00') AS a
GROUP BY trainno) AS b
Wenn wir die Abfrage in Teile zerlegen, können wir die folgenden Teile des Puzzles sehen:
- Sie können einige der normalen Elemente einer SQL-Abfrage sehen (INSERT INTO, SELECT, AS, FROM, WHERE, AND, GROUP BY)
- geom, trainno und time sind Spaltennamen in meiner Wochentabelle im Schema trains
- Die Unterabfrage a gibt alle GPS-Punkte zurück, die innerhalb des angeforderten Zeitrahmens verfolgt wurden.
- Da ich alle GPS-Punkte auswähle, die innerhalb einer Minute verfolgt werden, erhalte ich möglicherweise mehrere Punkte für jeden Zug. Ich wollte nur eine, damit die Voronoi-Linien vernünftiger aussehen. Aus diesem Grund verwende ich ST_Collect , um die Punkte zu gruppieren und daraus eine Mehrpunktgeometrie zu erstellen. ST_Centroid ersetzt die Mehrpunktgeometrie durch einen einzelnen Punkt am Schwerpunkt (Unterabfrage b), und die Daten werden nach Zugnummern gruppiert.
Um dasselbe mehrmals zu tun, hatte ich ein einfaches Python-Skript, um die gleiche Abfrage einige hundert Mal zu durchlaufen, wobei ich die Start- und Endzeiten als Parameter hatte. Nachdem ich erfolgreich einen repräsentativen Punkt für jede Minute gefunden hatte, führte ich einfach den folgenden Befehl aus (in 11,5 Sekunden):
SELECT t, ST_VoronoiLines(geom) from trains.voronoipoints
Dann habe ich das Ergebnis zu QGIS hinzugefügt und mit Time Manager visualisiert. Dies ist möglicherweise ein etwas hackiger Weg, um das Ergebnis zu erzielen, und ein erfahrenerer SQL-Benutzer hat es möglicherweise vollständig mit einem einzigen SQL-Befehl ausgeführt, aber ich bin immer noch ziemlich zufrieden mit dem Ergebnis. Obwohl es sinnlos sein könnte.
Schließlich ziemlich einfach, aber das Ergebnis sieht aus wie Mathematik auf höherer Ebene (und das ist es!), da die ganze harte Arbeit von PostGIS erledigt wird. Auch weil ich die Voronoi-Analyse nur für einen Punkt pro Zug durchführen konnte, betrug die Verarbeitungszeit für Hunderttausende von Punkten nur Sekunden.
Oft wächst die Verarbeitungszeit Ihrer Abfragen exponentiell, wenn die Datenmengen wachsen. Deshalb müssen Sie mit Ihren Abfragen klug sein.

Als Faustregel gilt: Je mehr Daten eine Abfrage abrufen muss und je mehr Operationen die Datenbank ausführen muss (Ordnen, Gruppieren usw.), desto langsamer und damit weniger effizient. Eine effiziente SQL-Abfrage ruft nur die Zeilen und Spalten ab, die sie wirklich benötigt. SQL kann wie ein logisches Puzzle funktionieren, bei dem Sie wirklich gründlich überlegen müssen, was Sie erreichen möchten.
Ich muss auch beachten, dass das Optimieren der Leistung Ihrer Abfragen ein rutschiger Abhang ist und Sie sich in der Welt der endlosen Optimierung verlieren können. Das Gleichgewicht zwischen einer „optimalen Abfrage“ und einer optimalen Abfrage zu finden, ist wirklich wichtig. Besonders wenn Sie keine Anwendung für eine Million Benutzer erstellen, werden ein paar Millisekunden hier oder da Ihr Boot wahrscheinlich nicht rocken.
Wie fange ich an?
Ich wage zu sagen, dass das Erlernen von SQL für einen durchschnittlichen GIS-Benutzer noch vorteilhafter ist als das Erlernen von JavaScript, Python oder R. Die SQL-Syntax hat sich im Laufe der Jahre nur geringfügig geändert und SQL-Kenntnisse sind sehr gut übertragbar.
Ich habe festgestellt, dass die Lernkurve in SQL nicht wirklich steil ist, um die Grundlagen zu erlernen, aber es kann einige Zeit dauern, bis Sie die Vorteile, die es für Ihre räumliche Analyse bringen kann, wirklich erkannt haben. Aber ich ermutige, geduldig zu sein und kompliziertere Analysen auszuprobieren und eine schnellere Verarbeitung anzustreben. Schließlich werden Sie den Unterschied sehen.
Wenn Sie SQL-Grundlagen erlernen, lernen Sie zunächst, wie Sie Daten aus einer einzelnen Tabelle mithilfe grundlegender Datenauswahltechniken wie Auswählen von Spalten, Sortieren von Ergebnismengen und Filtern von Zeilen abfragen. Anschließend lernen Sie die erweiterten Abfragen kennen, z. B. das Verbinden mehrerer Tabellen, das Verwenden von Set-Operationen und das Erstellen einer Unterabfrage. Schließlich lernen Sie, wie Sie Datenbanktabellen verwalten, z. B. eine neue Tabelle erstellen oder die Struktur einer vorhandenen Tabelle ändern.
Aber es gibt auch Tools, die Ihnen helfen!
QGIS hat ein großartiges Tool namens DB Manager. Es bietet eine ähnliche GUI für Ihre Datenbank, jedoch viel komprimierter und in QGIS. Sie können Tabellen ändern und hinzufügen, Indizes hinzufügen und viele der grundlegenden Operationen mit der rechten Maustaste ausführen.

Sie sollten auch pgAdmin überprüfen, die beliebteste Verwaltungs- und Entwicklungsplattform für PostgreSQL. Es gibt mehrere Möglichkeiten, Ihre Daten in PostGIS zu übertragen (z. B. ogr2ogr, shp2pgsql). Generell empfehle ich, verschiedene Tools und Methoden zum Arbeiten mit den Daten auszuprobieren.
Ich habe ein paar kleine Experimente zur Kombination von Python und PostGIS durchgeführt. Die gemeinsame Arbeit mit Python (oder R) und PostGIS kann Ihre Datenverarbeitung und Automatisierung auf die nächste Stufe heben. Die Kombination der grundlegenden Skriptfunktionen von Python und die Verbindung zu PostGIS mit psycopg2 sind gute Einstiegsmöglichkeiten.
Möchten Sie mit PostGIS beginnen?
- Laden Sie einfach die Installationsprogramme herunter und installieren Sie PostGIS auf Ihrem lokalen Computer. Folgen Sie den Anweisungen in den Tutorials;
- Laden Sie dort einige Daten. Beginnen Sie mit einem einzelnen Shapefile mit QGIS DB Manager oder chech zum Beispiel dieses Tutorial, wie man natürliche Erddaten zu PostGIS bekommt;
- Fangen Sie an, mit SQL herumzuspielen. Beginnen Sie mit den Grundlagen (Auswählen, Filtern und Ändern der Daten) und langsam werden Sie sehen, welche Vorteile dies für Ihren Workflow bringen könnte.
Schlussfolgerungen
Wenn Ihre Arbeitsweise derzeit ineffizient ist, wird das Ändern Ihrer Werkzeuge Ihr Ergebnis nicht verbessern oder den Prozess weniger schmerzhaft machen. Sie müssen die Art und Weise ändern, wie Sie über das Datenmanagement denken. Es gibt zahlreiche Möglichkeiten, Datenbanken ineffizient zu nutzen. Vertrau mir, ich habe sie gesehen und sogar ein paar ausprobiert.
Auch Dinge zu ändern, nur um der Veränderung willen, macht keinen Sinn. Wenn Ihre tägliche Arbeit nur ab und zu ein paar Punkte auf einer Karte zeichnet, können Sie dies auch in Zukunft mit Shapefiles und CSV-Dateien tun. Könnte auf diese Weise sogar effizienter sein.
ABER.
Wenn Sie ernsthafte räumliche Analysen durchführen, Ihre Prozesse automatisieren oder Ihre Arbeitsweise mit SPS-Daten auf die nächste Ebene heben möchten, kann ich Ihnen dringend empfehlen, sich mit PostGIS und insbesondere Spatial SQL vertraut zu machen. SQL lernen kann auch Spaß machen. Ernst.
Nicht zuletzt. Wie Tom betonte: Mit PostGIS erhalten Sie Geohipster cred!

Eine Sache, die ich nur kurz erwähnt habe, war, dass PostGIS Open Source und frei verfügbar ist. Dies bedeutet, dass Menschen, die mit kleinem oder keinem Budget arbeiten (wie ich), keine Eintrittsbarriere haben. Kommerzielle räumliche Datenbanken können sehr teuer sein. Vielen Dank an alle aktiven Entwickler, die an dem Projekt arbeiten!
Danke fürs Lesen! Besuchen Sie meine Website für weitere Informationen über mich oder werfen Sie mir einen Kommentar auf Twitter.
Möchten Sie mehr erfahren? Quellen für diesen Blogbeitrag und weitere PostGIS lesen
RTFD. Die PostGIS-Dokumentation ist wirklich gut.
PostGIS Guru Paul Ramsey hat auf seiner Seite
mehrere Vorträge zum Thema aus verschiedenen Blickwinkeln gehalten.
Anita Graser hat eine grandiose Serie von Blogbeiträgen über den Umgang mit Bewegungsdaten in PostGIS geschrieben.
Schauen Sie sich die PostGIS-Bücher von Regina Obe an
Ich habe dieses Boston GIS-Tutorial verwendet, als ich PostGIS zum ersten Mal lokal installiert habe
Extra für Leute, die Dataviz machen: Ein interessantes Experiment zum Speichern von Farben als 3D-Punkte in PostGIS