Zuletzt aktualisiert am 7. August 2019
Worteinbettungen sind eine Art Wortdarstellung, die es Wörtern mit ähnlicher Bedeutung ermöglicht, eine ähnliche Darstellung zu haben.
Sie sind eine verteilte Repräsentation für Text, die vielleicht einer der wichtigsten Durchbrüche für die beeindruckende Leistung von Deep-Learning-Methoden bei anspruchsvollen Problemen der Verarbeitung natürlicher Sprache ist.
In diesem Beitrag werden Sie den Ansatz der Worteinbettung zur Darstellung von Textdaten kennenlernen.
Nach Abschluss dieses Beitrags werden Sie wissen:
- Was der Worteinbettungsansatz zur Darstellung von Text ist und wie er sich von anderen Methoden zur Merkmalsextraktion unterscheidet.
- Dass es 3 Hauptalgorithmen zum Erlernen einer Worteinbettung aus Textdaten gibt.
- Dass Sie entweder eine neue Einbettung trainieren oder eine vortrainierte Einbettung für Ihre Aufgabe zur Verarbeitung natürlicher Sprache verwenden können.
Starten Sie Ihr Projekt mit meinem neuen Buch Deep Learning for Natural Language Processing, einschließlich Schritt-für-Schritt-Anleitungen und den Python-Quellcodedateien für alle Beispiele.
Lass uns anfangen.

Was sind Worteinbettungen für Text?
Foto von Heather, einige Rechte vorbehalten.
- Übersicht
- Benötigen Sie Hilfe beim Deep Learning für Textdaten?
- Was sind Word Embeddings?
- Worteinbettungsalgorithmen
- Einbettungsschicht
- Word2Vec
- GloVe
- Verwenden von Word-Einbettungen
- Lernen Sie eine Einbettung
- Wiederverwendung einer Einbettung
- Welche Option sollten Sie verwenden?
- Tutorials zum Einbetten von Wörtern
- Weiterführende Literatur
- Artikel
- Papiere
- Projekte
- Bücher
- Zusammenfassung
- Entwickeln Sie noch heute Deep-Learning-Modelle für Textdaten!
- Entwickeln Sie Ihre eigenen Textmodelle in wenigen Minuten
- Bringen Sie endlich Deep Learning in Ihre Projekte zur Verarbeitung natürlicher Sprache
Übersicht
Dieser Beitrag ist in 3 Teile unterteilt; Sie sind:
- Was sind Word Embeddings?
- Worteinbettungsalgorithmen
- Verwenden von Worteinbettungen
Benötigen Sie Hilfe beim Deep Learning für Textdaten?
Nehmen Sie jetzt an meinem kostenlosen 7-tägigen E-Mail-Crashkurs teil (mit Code).
Klicken Sie hier, um sich anzumelden und eine kostenlose PDF-Ebook-Version des Kurses zu erhalten.
Starten Sie jetzt Ihren KOSTENLOSEN Crashkurs
Was sind Word Embeddings?
Eine Worteinbettung ist eine gelernte Darstellung für Text, bei der Wörter, die dieselbe Bedeutung haben, eine ähnliche Darstellung haben.
Dieser Ansatz zur Darstellung von Wörtern und Dokumenten kann als einer der wichtigsten Durchbrüche des tiefen Lernens bei herausfordernden Problemen der Verarbeitung natürlicher Sprache angesehen werden.
Einer der Vorteile der Verwendung dichter und niedrigdimensionaler Vektoren ist die Berechnung: die Mehrheit der neuronalen Netzwerk-Toolkits spielt nicht gut mit sehr hochdimensionalen, spärlichen Vektoren. … Der Hauptvorteil der dichten Darstellungen ist die Verallgemeinerungskraft: Wenn wir glauben, dass einige Merkmale ähnliche Hinweise liefern können, lohnt es sich, eine Darstellung bereitzustellen, die diese Ähnlichkeiten erfassen kann.
— Seite 92, Neuronale Netzwerkmethoden in der Verarbeitung natürlicher Sprache, 2017.
Worteinbettungen sind in der Tat eine Klasse von Techniken, bei denen einzelne Wörter als reellwertige Vektoren in einem vordefinierten Vektorraum dargestellt werden. Jedes Wort wird einem Vektor zugeordnet, und die Vektorwerte werden auf eine Weise gelernt, die einem neuronalen Netzwerk ähnelt.
Der Schlüssel zum Ansatz ist die Idee, für jedes Wort eine dichte verteilte Darstellung zu verwenden.
Jedes Wort wird durch einen reellen Vektor dargestellt, oft zehn oder Hunderte von Dimensionen. Dies steht im Gegensatz zu den Tausenden oder Millionen von Dimensionen, die für spärliche Wortdarstellungen erforderlich sind, z. B. eine One-Hot-Codierung.
Ordnen Sie jedem Wort im Vokabular einen verteilten Wortmerkmalsvektor zu … Der Merkmalsvektor repräsentiert verschiedene Aspekte des Wortes: Jedes Wort ist einem Punkt in einem Vektorraum zugeordnet. Die Anzahl der Funktionen … ist viel kleiner als die Größe des Vokabulars
— Ein neuronales probabilistisches Sprachmodell, 2003.
Die verteilte Repräsentation wird basierend auf der Verwendung von Wörtern gelernt. Auf diese Weise können Wörter, die auf ähnliche Weise verwendet werden, zu ähnlichen Darstellungen führen und ihre Bedeutung auf natürliche Weise erfassen. Dies kann mit der knackigen, aber fragilen Darstellung in einem Bag of Words-Modell kontrastiert werden, wo, sofern nicht explizit verwaltet, verschiedene Wörter unterschiedliche Darstellungen haben, unabhängig davon, wie sie verwendet werden.
Hinter dem Ansatz steckt eine tiefere linguistische Theorie, nämlich die „Verteilungshypothese“ von Zellig Harris, die wie folgt zusammengefasst werden könnte: Wörter mit ähnlichem Kontext haben ähnliche Bedeutungen. Für mehr Tiefe siehe Harris ‚1956 Papier „Verteilungsstruktur“.
Diese Vorstellung, die Verwendung des Wortes seine Bedeutung definieren zu lassen, kann durch einen oft wiederholten Witz von John Firth zusammengefasst werden:
Sie werden ein Wort von der Firma wissen, die es hält!
— Seite 11, „Eine Zusammenfassung der Sprachtheorie 1930-1955“, in Studien zur Sprachanalyse 1930-1955, 1962.
Worteinbettungsalgorithmen
Worteinbettungsmethoden Lernen Sie eine reellwertige Vektordarstellung für ein vordefiniertes Vokabular fester Größe aus einem Textkorpus.
Der Lernprozess ist entweder gemeinsam mit dem neuronalen Netzwerkmodell für eine bestimmte Aufgabe, z. B. die Dokumentenklassifizierung, oder es handelt sich um einen unbeaufsichtigten Prozess, der Dokumentenstatistiken verwendet.
In diesem Abschnitt werden drei Techniken beschrieben, mit denen Sie das Einbetten eines Wortes aus Textdaten erlernen können.
Einbettungsschicht
Eine Einbettungsschicht ist mangels eines besseren Namens eine Worteinbettung, die gemeinsam mit einem neuronalen Netzwerkmodell für eine bestimmte Verarbeitungsaufgabe der natürlichen Sprache wie Sprachmodellierung oder Dokumentenklassifizierung gelernt wird.
Es erfordert, dass Dokumenttext bereinigt und so vorbereitet wird, dass jedes Wort One-Hot-codiert ist. Die Größe des Vektorraums wird als Teil des Modells angegeben, z. B. 50, 100 oder 300 Dimensionen. Die Vektoren werden mit kleinen Zufallszahlen initialisiert. Die Einbettungsschicht wird am vorderen Ende eines neuronalen Netzwerks verwendet und mithilfe des Backpropagationsalgorithmus überwacht angepasst.
… wenn die Eingabe in ein neuronales Netzwerk symbolische kategoriale Merkmale enthält (z. b. Merkmale, die eines von k verschiedenen Symbolen annehmen, wie z. B. Wörter aus einem geschlossenen Vokabular), ist es üblich, jeden möglichen Merkmalswert (d. H. Jedes Wort im Vokabular) für einige d mit einem d-dimensionalen Vektor zu verknüpfen.
— Seite 49, Neuronale Netzwerkmethoden in der Verarbeitung natürlicher Sprache, 2017.
Die One-Hot-codierten Wörter werden den Wortvektoren zugeordnet. Wenn ein mehrschichtiges Perzeptron-Modell verwendet wird, werden die Wortvektoren verkettet, bevor sie als Eingabe in das Modell eingespeist werden. Wenn ein rekurrentes neuronales Netzwerk verwendet wird, kann jedes Wort als eine Eingabe in einer Sequenz verwendet werden.
Dieser Ansatz zum Erlernen einer Einbettungsebene erfordert viele Trainingsdaten und kann langsam sein, lernt jedoch eine Einbettung, die sowohl auf die spezifischen Textdaten als auch auf die NLP-Aufgabe abzielt.
Word2Vec
Word2Vec ist eine statistische Methode zum effizienten Erlernen einer eigenständigen Worteinbettung aus einem Textkorpus.
Es wurde von Tomas Mikolov, et al. bei Google im Jahr 2013 als Reaktion auf das neuronale Netzwerk-basierte Training der Einbettung effizienter zu machen und seitdem ist der De-facto-Standard für die Entwicklung von vortrainierten Worteinbettung geworden.
Darüber hinaus umfasste die Arbeit die Analyse der gelernten Vektoren und die Erforschung der Vektormathematik über die Repräsentation von Wörtern. Zum Beispiel, dass das Subtrahieren der „Man-ness“ von „King“ und das Hinzufügen von „women-ness“ zu dem Wort „Queen“ führt und die Analogie „king is to queen as man is to woman“ erfasst.
Wir finden, dass diese Darstellungen überraschend gut darin sind, syntaktische und semantische Gesetzmäßigkeiten in der Sprache zu erfassen, und dass jede Beziehung durch einen beziehungsspezifischen Vektorversatz gekennzeichnet ist. Dies ermöglicht vektororientiertes Denken basierend auf den Offsets zwischen Wörtern. Zum Beispiel wird die männlich / weibliche Beziehung automatisch gelernt, und mit den induzierten Vektordarstellungen führt „König – Mann + Frau“ zu einem Vektor, der der „Königin“ sehr nahe kommt.“
— Linguistische Gesetzmäßigkeiten in kontinuierlichen Raumwortdarstellungen, 2013.
Es wurden zwei verschiedene Lernmodelle eingeführt, die als Teil des word2vec-Ansatzes zum Erlernen der Worteinbettung verwendet werden können; Sie sind:
- Continuous Bag-of-Words oder CBOW-Modell.
- Kontinuierliche Überspringen-Gramm Modell.
Das CBOW-Modell lernt die Einbettung, indem es das aktuelle Wort basierend auf seinem Kontext vorhersagt. Das kontinuierliche Skip-Gram-Modell lernt, indem es die umgebenden Wörter bei einem aktuellen Wort vorhersagt.
Das kontinuierliche Skip-Gram-Modell lernt, indem es die umgebenden Wörter bei einem aktuellen Wort vorhersagt.
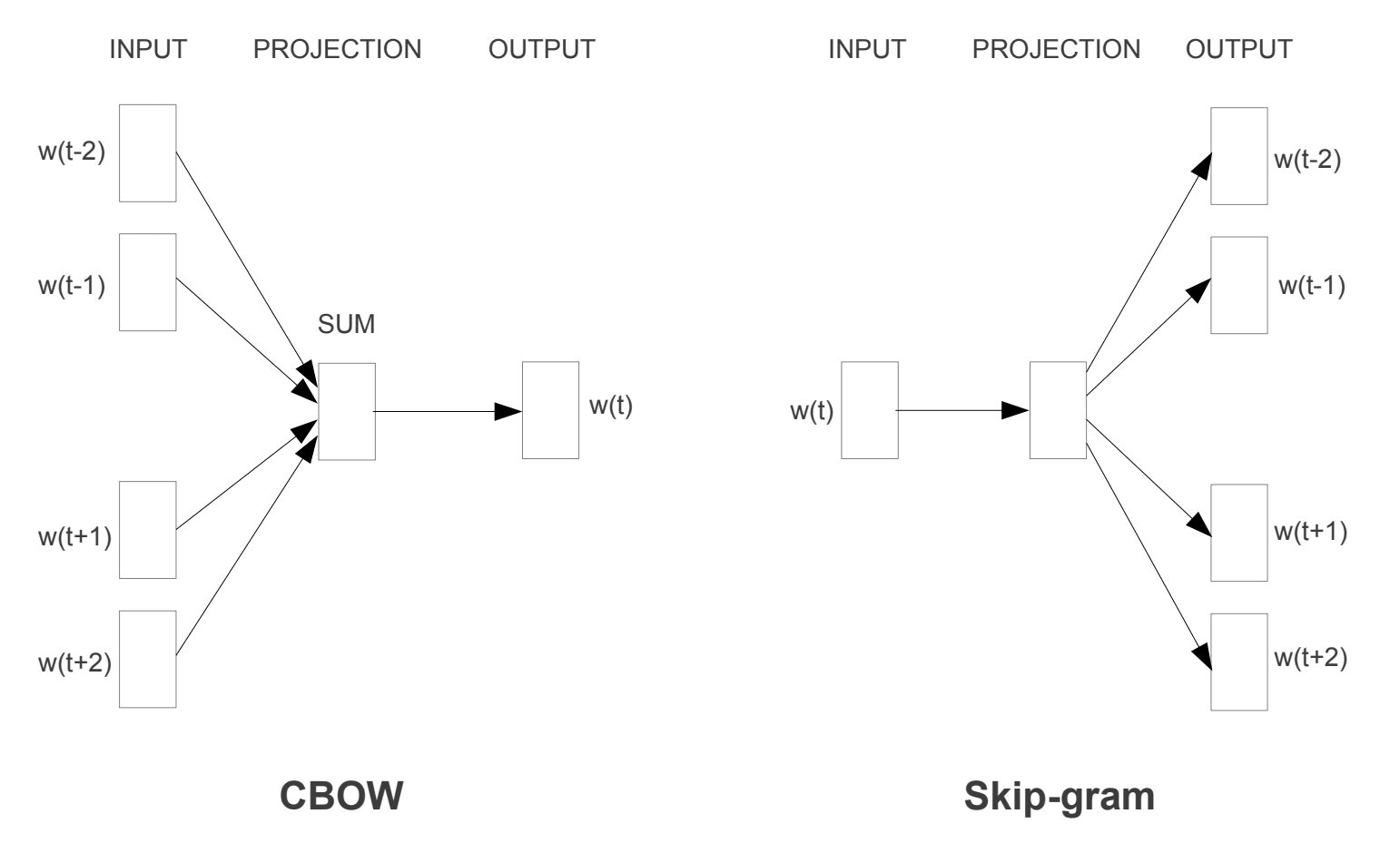
Word2Vec-Trainingsmodelle
Entnommen aus „Effiziente Schätzung von Wortdarstellungen im Vektorraum“, 2013
Beide Modelle konzentrieren sich darauf, Wörter anhand ihres lokalen Verwendungskontexts zu lernen, wobei der Kontext durch ein Fenster benachbarter Wörter definiert wird. Dieses Fenster ist ein konfigurierbarer Parameter des Modells.
Die Größe des Schiebefensters hat einen starken Einfluss auf die resultierenden Vektorähnlichkeiten. Große Fenster neigen dazu, mehr aktuelle Ähnlichkeiten zu erzeugen , während kleinere Fenster dazu neigen, mehr funktionale und syntaktische Ähnlichkeiten zu erzeugen.
— Seite 128, Neuronale Netzwerkmethoden in der Verarbeitung natürlicher Sprache, 2017.
Der Hauptvorteil des Ansatzes besteht darin, dass qualitativ hochwertige Worteinbettungen effizient erlernt werden können (geringe räumliche und zeitliche Komplexität), sodass größere Einbettungen (mehr Dimensionen) aus viel größeren Textkorpora (Milliarden von Wörtern) erlernt werden können.
GloVe
Der Glove-Algorithmus (Global Vectors for Word Representation) ist eine Erweiterung der word2vec-Methode zum effizienten Erlernen von Wortvektoren, die von Pennington et al. in Stanford.
Klassische Vektorraummodelldarstellungen von Wörtern wurden unter Verwendung von Matrixfaktorisierungstechniken wie Latent Semantic Analysis (LSA) entwickelt, die eine gute Arbeit bei der Verwendung globaler Textstatistiken leisten, aber nicht so gut sind wie die erlernten Methoden wie word2vec, um Bedeutung zu erfassen und sie bei Aufgaben wie der Berechnung von Analogien (z. der König und die Königin Beispiel oben).
Dies ist ein Ansatz, um sowohl die globale Statistik von Matrixfaktorisierungstechniken wie LSA mit dem lokalen kontextbasierten Lernen in word2vec zu verbinden.
Anstatt ein Fenster zum Definieren des lokalen Kontexts zu verwenden, konstruiert GloVe eine explizite Wortkontext- oder Wortko-Vorkommen-Matrix unter Verwendung von Statistiken über den gesamten Textkorpus. Das Ergebnis ist ein Lernmodell, das zu allgemein besseren Worteinbettungen führen kann.
GloVe ist ein neues globales log-bilineares Regressionsmodell für das unbeaufsichtigte Lernen von Wortdarstellungen, das andere Modelle für Wortanalogie-, Wortähnlichkeits- und benannte Entitätserkennungsaufgaben übertrifft.
— GloVe: Globale Vektoren für die Wortdarstellung, 2014.
Verwenden von Word-Einbettungen
Sie haben einige Optionen, wenn es darum geht, Word-Einbettungen in Ihrem Natural Language Processing-Projekt zu verwenden.
Dieser Abschnitt beschreibt diese Optionen.
Lernen Sie eine Einbettung
Sie können wählen, ein Wort Einbettung für Ihr Problem zu lernen.
Dies erfordert eine große Menge an Textdaten, um sicherzustellen, dass nützliche Einbettungen gelernt werden, z. B. Millionen oder Milliarden von Wörtern.
Sie haben zwei Hauptoptionen, wenn Sie Ihre Worteinbettung trainieren:
- Lernen Sie es eigenständig, wo ein Modell trainiert wird, um die Einbettung zu lernen, die gespeichert und später als Teil eines anderen Modells für Ihre Aufgabe verwendet wird. Dies ist ein guter Ansatz, wenn Sie dieselbe Einbettung in mehreren Modellen verwenden möchten.
- Gemeinsam lernen, wobei die Einbettung als Teil eines großen aufgabenspezifischen Modells erlernt wird. Dies ist ein guter Ansatz, wenn Sie die Einbettung nur für eine Aufgabe verwenden möchten.
Wiederverwendung einer Einbettung
Es ist üblich, dass Forscher vortrainierte Worteinbettungen kostenlos zur Verfügung stellen, häufig unter einer freizügigen Lizenz, damit Sie sie für Ihre eigenen akademischen oder kommerziellen Projekte verwenden können.
Zum Beispiel stehen sowohl word2vec- als auch GloVe Word-Einbettungen zum kostenlosen Download zur Verfügung.
Diese können in Ihrem Projekt verwendet werden, anstatt Ihre eigenen Einbettungen von Grund auf neu zu trainieren.
Sie haben zwei Hauptoptionen, wenn Sie vortrainierte Einbettungen verwenden möchten:
- Statisch, wobei die Einbettung statisch gehalten und als Komponente Ihres Modells verwendet wird. Dies ist ein geeigneter Ansatz, wenn die Einbettung gut zu Ihrem Problem passt und gute Ergebnisse liefert.
- Aktualisiert, wobei die vortrainierte Einbettung zum Seeding des Modells verwendet wird, die Einbettung jedoch gemeinsam während des Trainings des Modells aktualisiert wird. Dies kann eine gute Option sein, wenn Sie das Modell optimal nutzen und in Ihre Aufgabe einbetten möchten.
Welche Option sollten Sie verwenden?
Erkunden Sie die verschiedenen Optionen und testen Sie, wenn möglich, welche die besten Ergebnisse für Ihr Problem liefert.
Beginnen Sie vielleicht mit schnellen Methoden wie der Verwendung einer vortrainierten Einbettung und verwenden Sie eine neue Einbettung nur, wenn dies zu einer besseren Leistung Ihres Problems führt.
Tutorials zum Einbetten von Wörtern
In diesem Abschnitt werden einige Schritt-für-Schritt-Tutorials aufgeführt, die Sie befolgen können, um Word-Einbettungen zu verwenden und Word-Einbettungen in Ihr Projekt zu integrieren.
- So entwickeln Sie Worteinbettungen in Python mit Gensim
- So verwenden Sie Worteinbettungsebenen für Deep Learning mit Keras
- So entwickeln Sie ein tiefes CNN für die Stimmungsanalyse (Textklassifizierung)
Weiterführende Literatur
Dieser Abschnitt enthält weitere Ressourcen zum Thema, wenn Sie tiefer gehen möchten.
Artikel
- Worteinbettung auf Wikipedia
- Word2vec auf Wikipedia
- GloVe auf Wikipedia
- Ein Überblick über Worteinbettungen und ihre Verbindung zu verteilungssemantischen Modellen, 2016.
- Tiefes Lernen, NLP und Darstellungen, 2014.
Papiere
- Verteilungsstruktur, 1956.
- Ein neuronales probabilistisches Sprachmodell, 2003.
- Eine einheitliche Architektur für die Verarbeitung natürlicher Sprache: Tiefe neuronale Netze mit Multitasking-Lernen, 2008.
- Kontinuierliche Raumsprachmodelle, 2007.
- Effiziente Schätzung von Wortdarstellungen im Vektorraum, 2013
- Verteilte Darstellungen von Wörtern und Phrasen und ihre Kompositorität, 2013.
- GloVe: Globale Vektoren für die Wortdarstellung, 2014.
Projekte
- word2vec auf Google Code
- GloVe: Globale Vektoren für die Wortdarstellung
Bücher
- Neuronale Netzwerkmethoden in der Verarbeitung natürlicher Sprache, 2017.
Zusammenfassung
In diesem Beitrag haben Sie Worteinbettungen als Darstellungsmethode für Text in Deep-Learning-Anwendungen entdeckt.
Insbesondere haben Sie gelernt:
- Was der Worteinbettungsansatz für Darstellungstext ist und wie er sich von anderen Merkmalsextraktionsmethoden unterscheidet.
- Dass es 3 Hauptalgorithmen zum Erlernen einer Worteinbettung aus Textdaten gibt.
- Dass Sie entweder eine neue Einbettung trainieren oder eine vortrainierte Einbettung für Ihre Aufgabe zur Verarbeitung natürlicher Sprache verwenden können.
Haben Sie Fragen?
Stellen Sie Ihre Fragen in den Kommentaren unten und ich werde mein Bestes tun, um zu antworten.
Entwickeln Sie noch heute Deep-Learning-Modelle für Textdaten!

Entwickeln Sie Ihre eigenen Textmodelle in wenigen Minuten
…mit nur wenigen Zeilen Python-Code
Entdecken Sie, wie in meinem neuen Ebook:
Deep Learning für die Verarbeitung natürlicher Sprache
Es bietet Tutorials zum Selbststudium zu Themen wie:
Wortsack, Worteinbettung, Sprachmodelle, Beschriftungsgenerierung, Textübersetzung und vieles mehr…
Bringen Sie endlich Deep Learning in Ihre Projekte zur Verarbeitung natürlicher Sprache
Überspringen Sie die Akademiker. Nur Ergebnisse.
Sehen, was drin ist