Como científico de datos en la industria del consumo, lo que generalmente siento es que los algoritmos de impulso son suficientes para la mayoría de las tareas de aprendizaje predictivo, al menos por ahora. Son potentes, flexibles y se pueden interpretar muy bien con algunos trucos. Por lo tanto, creo que es necesario leer algunos materiales y escribir algo sobre los algoritmos de refuerzo.
La mayor parte del contenido de este artículo se basa en el artículo: Impulso de árboles Con XGBoost: ¿Por qué XGBoost gana «Cada» Competencia de Aprendizaje Automático?. Es un documento muy informativo. Casi todo lo relacionado con los algoritmos de impulso se explica muy claramente en el documento. Así que el documento contiene 110 páginas: (
Para mí, básicamente me centraré en los tres algoritmos de refuerzo más populares: AdaBoost, GBM y XGBoost. He dividido el contenido en dos partes. El primer artículo (este) se centrará en el algoritmo AdaBoost, y el segundo se centrará en la comparación entre GBM y XGBoost.
AdaBoost, abreviatura de «Impulso adaptativo», es el primer algoritmo de impulso práctico propuesto por Freund y Schapire en 1996. Se centra en problemas de clasificación y tiene como objetivo convertir un conjunto de clasificadores débiles en uno fuerte. La ecuación final para la clasificación puede ser representado como
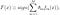
donde f_m representa el m_th débil clasificador y theta_m es el peso correspondiente. Es exactamente la combinación ponderada de clasificadores débiles M. Todo el procedimiento del algoritmo AdaBoost se puede resumir de la siguiente manera.
algoritmo AdaBoost
Dado un conjunto de datos que contiene n puntos, donde

Aquí -1 denota la clase negativa, mientras que el 1 representa el positivo.
Inicializar el peso para cada punto de datos como:

Para iteración m = 1,…, M:
(1) Ajuste clasificadores débiles al conjunto de datos y seleccione el que tenga el error de clasificación ponderado más bajo:

(2) Calcular el peso de la m_th débil clasificador:

Para cualquier clasificador con precisión superior al 50%, el peso es positivo. Cuanto más preciso sea el clasificador, mayor será el peso. Mientras que para el clasificador con menos del 50% de precisión, el peso es negativo. Significa que combinamos su predicción volteando el signo. Por ejemplo, podemos convertir un clasificador con una precisión del 40% en una precisión del 60% volteando el signo de la predicción. Por lo tanto, incluso el clasificador funciona peor que la adivinación aleatoria, todavía contribuye a la predicción final. Solo que no queremos ningún clasificador con una precisión exacta del 50%, que no agregue ninguna información y, por lo tanto, no contribuya en nada a la predicción final.
(3) Actualice el peso para cada punto de datos como:

donde Z_m es un factor de normalización que garantiza que la suma de todos los pesos de instancia sea igual a 1.
Si un caso clasificado incorrectamente proviene de un clasificador ponderado positivo, el término» exp » en el numerador sería siempre mayor que 1 (y*f es siempre -1, theta_m es positivo). Por lo tanto, los casos clasificados incorrectamente se actualizarían con pesos más grandes después de una iteración. La misma lógica se aplica a los clasificadores ponderados negativos. La única diferencia es que las clasificaciones correctas originales se convertirían en clasificaciones erróneas después de voltear el signo.
Después de la iteración M, podemos obtener la predicción final sumando la predicción ponderada de cada clasificador.
AdaBoost como Modelo de Aditivo por etapas
Esta parte se basa en el papel: Regresión logística aditiva: una visión estadística del impulso. Para obtener información más detallada, consulte el documento original.
En 2000, Friedman et al. se desarrolló una vista estadística del algoritmo AdaBoost. Interpretaron AdaBoost como procedimientos de estimación escalonada para ajustar un modelo de regresión logística aditiva. Ellos demostraron que AdaBoost en realidad era minimizar la exponencial de la función de pérdida

es minimizado en

Ya que para AdaBoost, y sólo puede ser -1 o 1, la pérdida de la función puede escribirse como

Continuar para resolver F(x), obtenemos

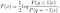
Podemos derivar aún más el modelo logístico normal de la solución óptima de F (x):

Es casi idéntico al modelo de regresión logística a pesar de un factor 2.
Supongamos que tenemos una estimación actual de F (x) e intentamos buscar una estimación mejorada de F(x)+cf(x). Fijo c y x, podemos ampliar L(y, F(x)+cf(x)) de segundo orden acerca de f(x)=0,

Así,

donde E_w(./ x) indica una expectativa condicional ponderada y el peso para cada punto de datos se calcula como

Si c > 0, minimizar la expectativa condicional ponderada es igual a maximizar

Dado que y solo puede ser 1 o -1, la expectativa ponderada se puede reescribir como

La solución óptima viene como

Después de determinar f (x), el peso c se puede calcular minimizando directamente L(y, F(x)+cf(x)):

la Solución para c, obtenemos


Vamos a epsilon es igual a la suma ponderada de mal clasificado de los casos, entonces

tenga en cuenta que c puede ser negativo si la débil alumno hace peor que adivinar al azar (50%), en en cuyo caso invierte automáticamente la polaridad.
En términos de la instancia de pesos, después de la mejora, además, el peso de una sola instancia se convierte en,

por Lo tanto la instancia de peso es actualizado

en Comparación con los utilizados en el algoritmo AdaBoost,

podemos ver que se encuentran en idéntica forma. Por lo tanto, es razonable interpretar AdaBoost como un modelo aditivo en etapas avanzadas con función de pérdida exponencial, que se ajusta iterativamente a un clasificador débil para mejorar la estimación actual en cada iteración m:
