Una introducción Suave al Codificador Automático y Algunos De Sus Casos de Uso Comunes Con Código Python
Fondo:
Autoencoder es una red neuronal artificial no supervisada que aprende a comprimir y codificar datos de manera eficiente y luego aprende a reconstruir los datos de la representación codificada reducida a una representación lo más cercana posible a la entrada original.
Autoencoder, por diseño, reduce las dimensiones de los datos al aprender a ignorar el ruido en los datos.
Aquí hay un ejemplo de la imagen de entrada/salida del conjunto de datos MNIST a un autoencodificador.
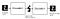
Componentes de Autoencoder:
Autoencoders consta de 4 partes principales:
1-Codificador: En el que el modelo aprende a reducir las dimensiones de entrada y comprimir los datos de entrada en una representación codificada.
2-Cuello de botella: que es la capa que contiene la representación comprimida de los datos de entrada. Se trata de las dimensiones más bajas posibles de los datos de entrada.
Decodificador 3: En el que el modelo aprende a reconstruir los datos de la representación codificada para que estén lo más cerca posible de la entrada original.
4-Pérdida de reconstrucción: Este es el método que mide el rendimiento del decodificador y la proximidad de la salida a la entrada original.
El entrenamiento consiste en utilizar la propagación hacia atrás para minimizar la pérdida de reconstrucción de la red.
¡Te debes estar preguntando por qué entrenaría una red neuronal solo para generar una imagen o datos que sean exactamente los mismos que la entrada! Este artículo cubrirá los casos de uso más comunes de Autoencoder. Comencemos:
Arquitectura de Autoencodificador:
La arquitectura de red para autoencodificadores puede variar entre una red simple de alimentación directa, una red LSTM o una Red Neuronal Convolucional, dependiendo del caso de uso. Exploraremos algunas de esas arquitecturas en las nuevas líneas siguientes.
Hay muchas formas y técnicas para detectar anomalías y valores atípicos. He cubierto este tema en una publicación diferente a continuación:
Sin embargo, si tiene datos de entrada correlacionados, el método autoencoder funcionará muy bien porque la operación de codificación se basa en las características correlacionadas para comprimir los datos.
Digamos que hemos entrenado un autoencodificador en el conjunto de datos MNIST. Usando una red neuronal de alimentación directa simple, podemos lograr esto construyendo una red simple de 6 capas como se muestra a continuación:
La salida del código anterior es:
Como puede ver en la salida, la última pérdida/error de reconstrucción para el conjunto de validación es 0.0193, lo que es genial. Ahora, si paso cualquier imagen normal del conjunto de datos MNIST, la pérdida de reconstrucción será muy baja (< 0.02), PERO si intento pasar cualquier otra imagen diferente (valor atípico o anomalía), obtendremos un valor de pérdida de reconstrucción alto porque la red no pudo reconstruir la imagen/entrada que se considera una anomalía.
Observe que en el código anterior, puede usar solo la parte del codificador para comprimir algunos datos o imágenes y también puede usar solo la parte del decodificador para descomprimir los datos cargando las capas del decodificador.
Ahora, vamos a hacer algo de detección de anomalías. El siguiente código utiliza dos imágenes diferentes para predecir la puntuación de anomalías (error de reconstrucción) utilizando la red de autoencoder que entrenamos anteriormente. la primera imagen es del MNIST y el resultado es 5.43209. Esto significa que la imagen no es una anomalía. La segunda imagen que utilicé, es una imagen completamente aleatoria que no pertenece al conjunto de datos de entrenamiento y los resultados fueron: 6789.4907. Este error alto significa que la imagen es una anomalía. El mismo concepto se aplica a cualquier tipo de conjunto de datos.