También hay varias formas incorrectas de incluir variables. Un modelo de gravedad no funcionará a menos que cada variable cumpla con los siguientes criterios:
- Numérica
- Completa
- Fiable
Solo Datos numéricos
Como el modelo de gravedad es una ecuación matemática, todas las variables de entrada deben ser numéricas. Podría ser un recuento (población), una medida espacial (área, distancia, etc.), el tiempo (horas desde Londres a pie), el porcentaje (aumento/disminución de salarios), el valor de la moneda (salarios en chelines) o alguna otra medida de los lugares involucrados en el modelo.
Los números deben ser significativos y no pueden ser variables categóricas nominales que actúen como sustitutos de un atributo cualitativo. Por ejemplo, no puede asignar arbitrariamente un número y usarlo en el modelo si el número no tiene significado (por ejemplo, road quality = bueno, o road quality = 4). Aunque este último es numérico, no es una medida de la calidad de la carretera. En su lugar, puede usar la velocidad promedio de viaje en millas por hora como un indicador de la calidad de la carretera. Si la velocidad promedio es una medida significativa de la calidad de la carretera, depende de usted determinar y defender como autor del estudio.
En términos generales, si puede medirlo o contarlo, puede modelarlo.
Solo Datos completos
Todas las categorías de datos deben existir para cada punto de interés. Eso significa que los 32 condados en análisis deben tener datos confiables para cada factor de empuje y atracción. No puede tener huecos o espacios en blanco, como un condado donde no tiene el salario promedio.
Solo Datos confiables
El adagio informático «basura dentro, basura fuera» también se aplica a los modelos de gravedad, que solo son tan confiables como los datos utilizados para construirlos. Más allá de elegir datos históricos sólidos y confiables de fuentes en las que puede confiar, hay muchas formas de cometer errores que harán que los resultados de su modelo no tengan sentido. Por ejemplo, vale la pena asegurarse de que los datos que tiene coincidan exactamente con los territorios (por ejemplo, datos del condado para representar condados, no datos de la ciudad para representar un condado).
Dependiendo de la hora y el lugar de su estudio, es posible que le resulte difícil obtener un conjunto de datos confiables en los que basar su modelo. Cuanto más atrás en el estudio del pasado, más difícil puede ser. Del mismo modo, puede ser más fácil llevar a cabo este tipo de análisis en sociedades que eran muy burocráticas y dejaron un buen rastro de papel, como en Europa o América del Norte.
Para garantizar la calidad de los datos en este estudio de caso, cada variable se calculó de forma fiable o se derivó de datos históricos publicados revisados por expertos (ver Tabla 1). La forma exacta en que se recopilaron estos datos se puede leer en el artículo original, donde se explicó en profundidad.11
- Nuestras Cinco Variables del modelo
- El Conjunto de Datos de Variables completado
- Paso 2: Determinación de las ponderaciones
- El Código para Calcular las Ponderaciones
- Paso 3: Calculando las Estimaciones para Cada Condado
- Paso 4 – la Interpretación Histórica
- Llevando su conocimiento hacia adelante
- Agradecimientos
- Notas al final
Nuestras Cinco Variables del modelo
Con los principios anteriores en mente, podríamos haber elegido cualquier número de variables, dado lo que sabíamos sobre los factores de empuje y atracción de la migración. Nos decidimos por cinco (5), elegidos en función de lo que pensábamos que sería más importante, y que sabíamos que se podía respaldar con datos confiables.
| Variable | Fuente |
|---|---|
| población en origen | 1771 valores, Wrigley, «English county populations», pp. 54-5.12 |
| distancia desde Londres | calculada con software |
| precio del trigo | Cannon and Brunt, «Weekly British Grain Prices»13 |
| salarios medios en origen | Hunt, «Industrialización y desigualdad regional», pp. 965-6.14 |
| trayectoria de los salarios | Hunt, «Industrialización y Desigualdad Regional», pp. 965-6.15 |
Cuadro 1: Las cinco variables utilizadas en el modelo, y la fuente de cada una en la literatura revisada por pares
Una vez decididas estas variables, el coautor del estudio original, Adam Dennett, decidió reescribir la fórmula para que se documentara por sí misma, de modo que fuera fácil decir qué bits pertenecían a cada una de estas cinco variables. Esta es la razón por la que la fórmula que se muestra arriba se ve diferente a la del artículo de investigación original. Los nuevos símbolos se pueden ver en la Tabla 2:
Dos variables adicionales i i and y j j j, significan» en el punto de origen «y» en Londres » respectivamente. $Wa_{i}$ significa «los niveles salariales en el punto de origen», mientras que $Wa_{j}$ significaría «los niveles salariales en Londres». Estos siete símbolos nuevos pueden reemplazar a los más genéricos de la fórmula:
\
Esto ahora es más detallado y una versión ligeramente auto documentada de la ecuación anterior. Ambos se resuelven matemáticamente exactamente de la misma manera, ya que los cambios son puramente superficiales y para el beneficio de un usuario humano.
El Conjunto de Datos de Variables completado
Para que el tutorial sea más rápido y fácil de completar, los datos para cada una de las 5 variables y cada uno de los 32 condados ya se han compilado y limpiado, y se pueden ver en la Tabla 3 o descargarse como un archivo csv. Esta tabla también incluye el número conocido de vagabundos de ese condado, según se observa en el registro de la fuente primaria:
| el Condado de | Vagabundos | $d$ km a Londres | $P$ de la Población (personas) | $Wa$ Promedio de Salarios (chelines) | $WaT$ Salario Trayectoria 1767-95 (% de cambio) | $Wh$ Precio del Trigo (chelines) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| En El Condado De Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornwall | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| En El Condado De Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
La diferencia final entre esta fórmula y la utilizada en el artículo original, es que dos de las variables de pasar a tener una relación más fuerte con la vagancia cuando se representa, naturalmente, de forma logarítmica. Son población de origen (P P)) y distancia de origen a Londres (d d d). Lo que esto significa es que para los datos de este estudio, la línea de regresión (a veces llamada línea de mejor ajuste) es un mejor ajuste cuando los datos se han registrado que cuando no se han registrado. Puede ver esto en la Figura 7, con las cifras de población no registrada a la izquierda y la versión registrada a la derecha. Más de los puntos están más cerca de la línea de mejor ajuste en el gráfico registrado que en el no registrado.
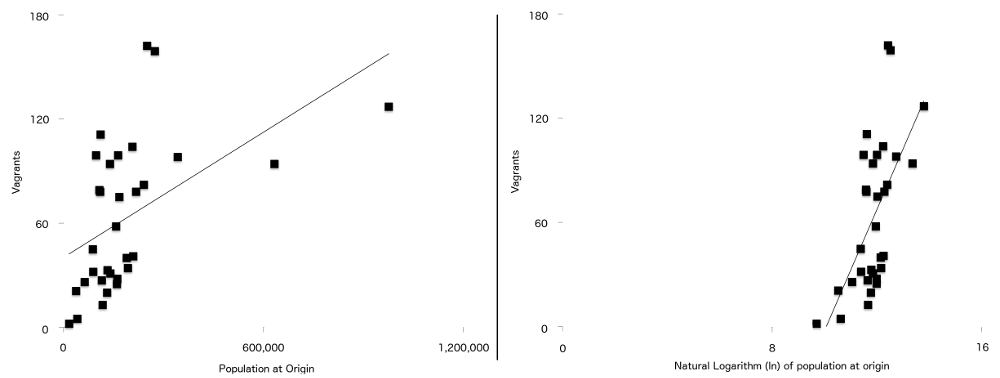
Gráfico 7: Número de vagabundos trazados en función de la población de origen (izquierda) y el registro natural de la población de origen (derecha) con una línea de regresión simple superpuesta en ambos. Tenga en cuenta la relación más fuerte entre las dos variables visibles en el segundo gráfico.
Debido a que este es el caso de estos datos en particular (es posible que sus propios datos en un tipo de estudio similar no sigan este patrón), la fórmula se ajustó para usar las versiones registradas naturalmente de estas dos variables, lo que resultó en la fórmula final utilizada en el modelo de gravedad (Figura 8). No podríamos haber sabido sobre la necesidad de este ajuste hasta después de haber recopilado nuestros datos variables:
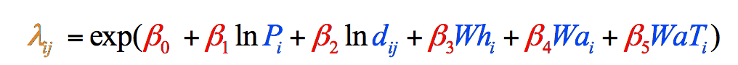
Figura 8: Fórmula del modelo de gravedad final desglosada por pasos y codificada por colores. Los elementos en negro son operaciones matemáticas. Los elementos en azul representan nuestras variables, que acabamos de reunir (Paso 1). Los elementos en rojo representan las ponderaciones de cada variable, que debemos calcular (Paso 2), y el Elemento en Naranja es la estimación final de los vagabundos de ese condado, que podemos calcular una vez que tengamos la otra información (Paso 3).
Los valores de la Tabla 3 nos dan todo lo que necesitamos para rellenar las partes azules de cada ecuación en la Figura 8. Ahora podemos dirigir nuestra atención a las partes rojas, que nos dicen cuán importante es cada variable en el modelo en general, y nos dan los números que necesitamos para completar la ecuación.
Paso 2: Determinación de las ponderaciones
Las ponderaciones para cada variable nos dicen cuán importante es ese factor de empuje/tracción en relación con las otras variables cuando se trata de estimar el número de vagabundos que deberían haber venido de un condado determinado. Los parámetros β β must deben determinarse en todo el conjunto de datos a partir de los datos conocidos. Con estos a mano, podremos comparar observaciones específicas de origen individuales con el modelo general. A continuación, podemos examinarlos e identificar flujos sobre y sobre predichos entre los diversos orígenes y el destino.
En esta etapa no sabemos lo importante que es cada uno. Tal vez el precio del trigo es un mejor predictor de la migración que la distancia? No lo sabremos hasta que calculemos los valores de β β1 through a β β5 β (las ponderaciones) resolviendo la ecuación anterior. La intersección en y (β β0.) solo es posible de calcular una vez que conoces todos los demás (β β1-β5 β). Estos son los valores ROJOS de la Figura 8 anterior. Las ponderaciones pueden verse en el Cuadro 4 y en el Cuadro A1 del documento original.16 Ahora demostraremos cómo llegamos a estos valores.
Calcular estos valores a mano larga requiere una cantidad increíble de trabajo. Utilizaremos una solución rápida en el lenguaje de programación R que aprovecha el paquete masivo de William Venables y Brian Ripley que puede resolver ecuaciones de regresión binomial negativas como nuestro modelo de gravedad con una sola línea de código. Sin embargo, es importante entender los principios detrás de lo que uno está haciendo para apreciar lo que hace el código (tenga en cuenta que las siguientes secciones no hacen el cálculo, sino que le explican sus pasos; haremos el cálculo con el código más abajo en la página).
Cálculo de la ponderación Individual (en Principio)
$β_{1}$, $β_{2}$, etc, son los mismos que $β$ en el modelo de Regresión Lineal Simple de arriba, que es la pendiente de la recta de regresión (la subida más de la carrera, o cuánto $$ y aumenta cuando $$ x se incrementa en 1). La única diferencia aquí entre una Regresión Lineal Simple y nuestro modelo de gravedad es que tenemos que calcular 5 pendientes en lugar de 1.
Una Regresión Lineal Simple\(y = α + ßx\)
Necesitaremos resolver para cada una de estas cinco pendientes antes de poder calcular la intersección en y en el siguiente paso. Esto se debe a que las pendientes de los diversos valores β β are son parte de la ecuación para calcular la intersección en y.
La fórmula para calcular β β is en un análisis de regresión es:
\
Coeficiente de Correlación de Pearson
El coeficiente de correlación de Pearson se puede calcular a mano larga, pero es un cálculo bastante largo en este caso, que requiere 64 números. Hay algunos excelentes tutoriales en video en inglés disponibles en línea si desea ver un recorrido de cómo hacer los cálculos a mano larga.17 También hay una serie de calculadoras en línea que calcularán $r r para usted si proporciona los datos. Dado el gran número de dígitos a calcular, recomendaría un sitio web con una herramienta incorporada diseñada para hacer este cálculo. Asegúrese de elegir un sitio de buena reputación, como uno ofrecido por una universidad.
Calcular deviation s_{y}
La desviación estándar es una forma de expresar cuánta variación de la media (promedio) hay en los datos. En otras palabras, ¿los datos están bastante agrupados alrededor de la media, o la propagación es mucho más amplia?
De nuevo, hay calculadoras en línea y paquetes de software estadístico que pueden hacer este cálculo por usted si proporciona los datos.
Calculando β β_{0}
A continuación, tenemos que calcular la intersección en y. La fórmula para calcular la intersección en y en una Regresión Lineal Simple es:
\
Sin embargo, el cálculo se vuelve mucho más complicado en un análisis de regresión múltiple, ya que cada variable influye en el cálculo. Esto hace que hacerlo a mano sea muy difícil, y es una de las razones por las que optamos por una solución programática.
El Código para Calcular las Ponderaciones
El paquete estadístico de MASAS, escrito para el lenguaje de programación R, tiene una función que puede resolver ecuaciones de regresión binomial negativas, por lo que es muy fácil calcular lo que de otro modo sería una fórmula de mano larga muy difícil.
Esta sección asume que ha instalado R y ha instalado el paquete MASIVO. Si no lo ha hecho, tendrá que hacerlo antes de continuar. El tutorial de Taryn Dewar sobre Conceptos básicos de R con Datos Tabulares incluye instrucciones de instalación de R.
Para utilizar este código, deberá descargar una copia del conjunto de datos de las cinco variables más el número de vagabundos observados de cada uno de los 32 condados. Esto está disponible en la Tabla 3, o puede descargarse como a .archivo csv. Sea cual sea el modo que elija, guarde el archivo como VagrantsExampleData.csv. Si está utilizando un Mac, asegúrese de guardarlo como formato de Windows .archivo csv. Abre Vagantsexampledata.csv y familiarízate con su contenido. Debe notar cada uno de los 32 condados, junto con cada una de las variables que hemos discutido a lo largo de este tutorial. Utilizaremos los encabezados de columna para acceder a estos datos con nuestro programa informático. Podría haberles llamado de cualquier manera, pero en este archivo están:
vagrantspopulationdistancewheatwageswageTrajectory
En el mismo directorio en el que guardó el archivo csv, cree y guarde un nuevo archivo de script R (puede hacerlo con cualquier editor de texto o con RStudio, pero no utilice un procesador de textos como MS Word). Guárdelo como cálculos de peso.r.
Ahora escribiremos un programa corto que:
- Instala el paquete MASIVO
- Llama al paquete MASIVO para que podamos usarlo en nuestro código
- Almacena el contenido del .archivo csv a una variable que podemos usar programáticamente
- Resuelve la ecuación del modelo de gravedad utilizando el conjunto de datos
- Que arroja los resultados del cálculo.
Cada una de estas tareas se logrará a su vez con una sola línea de código
Copie el código anterior en sus cálculos de ponderación.archivo r y guardar. Ahora puede ejecutar el código utilizando su entorno R favorito (yo uso RStudio) y los resultados del cálculo deben aparecer en la ventana de la consola (el aspecto dependerá de su entorno). Es posible que necesite establecer el Directorio de trabajo de su entorno R en el directorio que contiene su .csv y .archivos r. Si está utilizando RStudio, puede hacerlo a través de los menús (Sesión – > Establecer directorio de trabajo – > Elegir Directorio). También puede lograr lo mismo con el comando:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundObserve que la línea 4 es la línea que resuelve la ecuación para nosotros, con el glm.función nb, que es la abreviatura de «modelo lineal generalizado – binomio negativo». Esta línea requiere un número de entradas:
- nuestras variables usan los encabezados de columna tal como están escritos en el .archivo csv, junto con cualquier registro que se deba realizar en ellos (
vagrants, log (population), log(distance),wheat,wages,wageTrajectory). Si estuviera ejecutando un modelo con sus propios datos, los ajustaría para reflejar los encabezados de columna en el conjunto de datos. - donde el código puede encontrar los datos, en este caso una variable que hemos definido en la línea 3 llamada
gravityModelData.
Las salidas del cálculo se pueden ver en la Figura 9:
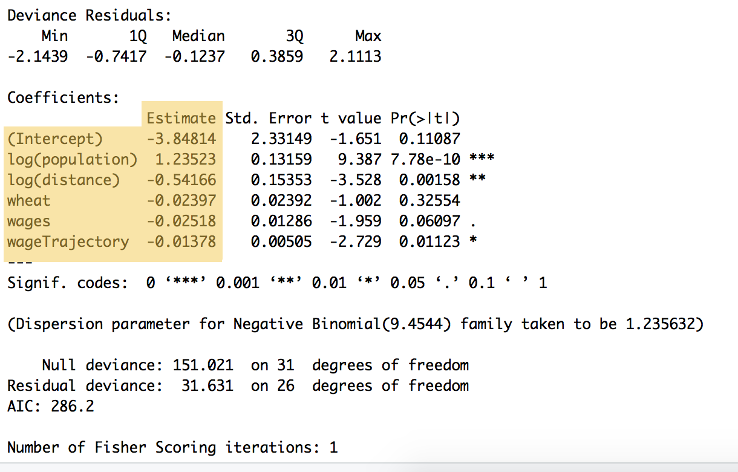
Figura 9: El resumen del código anterior, que muestra las ponderaciones para cada variable y la intersección en y, listadas bajo el encabezado «Estimación» ($\beta_{0} to a to\beta_{5}.. Este resumen también muestra una serie de otros cálculos, incluida la significación estadística.
Paso 3: Calculando las Estimaciones para Cada Condado
Tenemos que hacer esto una vez para cada uno de los 32 condados.
Puede hacer esto con una calculadora científica, creando una fórmula de hoja de cálculo o escribiendo un programa informático. Para hacer esto automáticamente en R, puede agregar lo siguiente a su código y volver a ejecutar el programa. Este bucle for calcula el número esperado de vagabundos de cada uno de los 32 condados del ejemplo e imprime los resultados para que los veas:
Para mejorar la comprensión, sugiero hacer una mano larga de condado. Este tutorial usará Hertfordshire como ejemplo de mano larga (pero el proceso es exactamente el mismo para los otros 31 condados).
Usando los datos para Hertfordshire en la Tabla 3, y las ponderaciones para cada variable en la Tabla 4, ahora podemos completar nuestra fórmula, que dará el resultado de 95:
Primero, intercambiemos los símbolos por los números, tomados de las tablas mencionadas anteriormente.
A continuación, comience a calcular los valores para llegar a la estimación. Recordando el orden matemático de las operaciones, multiplique los valores antes de sumar. Así que comience calculando cada variable (puede usar una calculadora científica para esto):
El siguiente paso es sumar los números juntos:
estimated vagrants = exp(4.56232408897)Y finalmente, para calcular la función exponencial (use una calculadora científica):
estimated vagrants = 95.8059926832Hemos eliminado el resto y declarado que el número estimado de vagabundos de Hertfordshire en este modelo es de 95. Debe realizar los mismos cálculos para cada uno de los otros condados, lo que podría acelerar utilizando un programa de hojas de cálculo. Solo para asegurarme de que puedes hacerlo de nuevo, también he incluido los números para Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
Recomiendo elegir otro condado y calcularlo a mano larga antes de seguir adelante, para asegurarme de que puedes hacer los cálculos por tu cuenta. La respuesta correcta está disponible en la Tabla 5, que compara los valores observados (como se ve en el registro de la fuente primaria) con los valores estimados (calculados por nuestro modelo de gravedad). El «Residuo» es la diferencia entre los dos, con una gran diferencia que sugiere un número inesperado de vagabundos que podría valer la pena mirar de cerca con el sombrero de historiador puesto.
| El Condado De | Valor Observado | Valor Estimado | Residual |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| En El Condado De Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornwall | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| En El Condado De Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Warwickshire | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Paso 4 – la Interpretación Histórica
En esta etapa, el proceso de modelización es completa y la etapa final es la interpretación histórica.
El artículo original publicado en el que se basó este estudio de caso, está dedicado principalmente a interpretar lo que significan los resultados del modelado para nuestra comprensión de la migración de clases bajas en el siglo XVIII. Como se ve en el mapa de la Figura 5, había partes del país en las que el modelo sugería fuertemente que el envío de migrantes de clase baja a Londres era excesivo o insuficiente.
Los coautores ofrecieron sus interpretaciones de por qué esos patrones pueden haber aparecido. Estas interpretaciones variaban según el lugar. En áreas del norte de Inglaterra que se estaban industrializando rápidamente, como Yorkshire o Manchester, las oportunidades locales parecían dar a la gente menos razones para irse, lo que resultó en una migración menor de lo esperado a Londres. En las zonas en declive hacia el oeste, como Bristol, el atractivo de Londres se hizo más fuerte a medida que más gente salía en busca de trabajo en la capital.
No se esperaban todos los patrones. Northumberland, en el extremo noreste, resultó ser una anomalía regional, enviando a Londres a muchos más migrantes (mujeres) de los que esperaríamos ver. Sin los resultados del modelo, es poco probable que hubiéramos pensado en Northumberland en absoluto, particularmente porque estaba tan lejos de la Metrópoli y suponíamos que tendría vínculos débiles con Londres. El modelo, por lo tanto, proporcionó nueva evidencia para que la consideráramos como historiadores y cambió nuestra comprensión de la relación Londres-Northumberland. Una discusión completa de nuestros hallazgos se puede leer en el artículo original.18
Llevando su conocimiento hacia adelante
Después de haber probado este problema de ejemplo, debe tener una comprensión clara de cómo usar esta fórmula de ejemplo, así como si un modelo de gravedad podría ser una solución adecuada para su problema de investigación. Usted tiene la experiencia y el vocabulario para abordar y discutir los modelos de gravedad con un colaborador con conocimientos matemáticos adecuados si lo necesita, que puede ayudarlo a adaptarlos a su propio estudio de caso.
Si tiene la suerte de tener también datos sobre los migrantes que se mudan a Londres a finales del siglo XVIII y desea modelarlos utilizando las mismas cinco variables enumeradas anteriormente, esta fórmula funcionaría tal cual: aquí hay un estudio fácil para alguien con los datos correctos. Sin embargo, este modelo no solo funciona para estudios sobre migrantes que se mudan a Londres. Las variables pueden cambiar, y el destino no tiene que ser Londres. Sería posible usar un modelo de gravedad para estudiar la migración a la antigua Roma, o a Bangkok del siglo XXI, si tienes los datos y la pregunta de investigación. Ni siquiera tiene que ser un modelo de migración. Para utilizar el estudio de caso del café colombiano de la introducción, que se centra en el comercio más que en la migración, el cuadro 6 muestra un uso viable de la misma fórmula, sin modificaciones.
| Criterios | Ejemplo de Exportación de café |
|---|---|
| UN punto de origen | exportaciones de café desde el puerto de Barranquilla, Colombia |
| Destinos finitos múltiples | los 21 países del Hemisferio Occidental en 1950 |
| CINCO variables explicativas | (1) número de puertos del Océano Atlántico en el país receptor (2) millas de Colombia, (3) Producto interno bruto del país receptor, (4) Café nacional cultivado en toneladas, (5) cafeterías por 10.000 personas |
Hay una larga historia de modelos de gravedad en la erudición académica. Para usar uno de manera efectiva para la investigación, es necesario comprender la teoría básica y las matemáticas detrás de ellos y las razones por las que se han desarrollado como lo han hecho. También es importante comprender sus límites y condiciones para usarlos correctamente, algunos de los cuales se discutieron anteriormente. También podría ayudar saber:
-
Un modelo de gravedad como el utilizado en este ejemplo solo puede funcionar en un sistema cerrado. El modelo anterior solo tenía 32 puntos de origen posibles, lo que permite ejecutar el modelo 32 veces. Un número desconocido o infinitamente grande de puntos de origen (o destinos dependiendo de su modelo), requeriría una ecuación diferente.
-
El concepto de modelo de gravedad también se basa en la premisa de que los movimientos (migración, comercio, etc.) se basan en un conjunto de decisiones individuales voluntarias que podrían estar influenciadas por factores externos, pero que no están totalmente controladas por ellos. Por ejemplo, las migraciones voluntarias o las compras realizadas por libre albedrío podrían modelarse utilizando esta técnica, pero la migración forzada, la compra obligatoria o los procesos naturales como la migración de aves o el flujo de ríos pueden no seguir los mismos principios y, por lo tanto, puede ser necesario un tipo diferente de modelo.
-
Los modelos de gravedad se pueden utilizar para predecir el comportamiento de las poblaciones, pero no de los individuos, y, por lo tanto, los intentos de modelar los datos deben incluir un gran número de movimientos para garantizar la significación estadística.
Hay muchos más escollos, pero también enormes posibilidades. Espero que este recorrido por un modelo de gravedad, y la investigación publicada que lo acompaña, hagan que esta poderosa herramienta sea más accesible para los historiadores. Si planea usar un modelo de gravedad en su investigación académica, el autor recomienda encarecidamente los siguientes artículos:
Agradecimientos
Con agradecimiento a Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas y Leanne Calvert por leer y comentar borradores anteriores de este artículo. También gracias a la Academia Británica por financiar el taller de escritura en Bogotá, Colombia en el que se redactó este artículo. Y finalmente a Adam Dennett por presentarme estas maravillosas fórmulas y liberar su potencial para los historiadores.