Última actualización el 7 de agosto de 2019
Las incrustaciones de palabras son un tipo de representación de palabras que permite que las palabras con un significado similar tengan una representación similar.
Son una representación distribuida para texto que es quizás uno de los avances clave para el impresionante rendimiento de los métodos de aprendizaje profundo en los desafiantes problemas de procesamiento del lenguaje natural.
En esta publicación, descubrirás el enfoque de incrustación de palabras para representar datos de texto.
Después de completar este post, sabrás:
- Qué es el enfoque de incrustación de palabras para representar texto y en qué se diferencia de otros métodos de extracción de características.
- Que hay 3 algoritmos principales para aprender la incrustación de una palabra a partir de datos de texto.
- Que puede entrenar una nueva incrustación o usar una incrustación preentrenada en su tarea de procesamiento de lenguaje natural.
Inicie su proyecto con mi nuevo libro Aprendizaje profundo para el procesamiento del lenguaje natural, que incluye tutoriales paso a paso y los archivos de código fuente de Python para todos los ejemplos.
Comencemos.

¿Qué son las Incrustaciones de Palabras para Texto?
Foto de Heather, algunos derechos reservados.
- Descripción general
- ¿Necesita ayuda con el Aprendizaje Profundo para Datos de Texto?
- ¿Qué Son Las Incrustaciones De Palabras?
- Algoritmos de incrustación de palabras
- Capa de incrustación
- Word2Vec
- GloVe
- Usar incrustaciones de Word
- Aprender una incrustación
- Reutilizar una incrustación
- ¿Qué Opción Debe Usar?
- Tutoriales de incrustación de palabras
- Artículos
- Papeles
- Proyectos
- Libros
- Resumen
- ¡Desarrolle modelos de Aprendizaje Profundo para Datos de Texto Hoy mismo!
- Desarrolle sus Propios modelos de texto en Minutos
- Finalmente, lleve el Aprendizaje Profundo a sus Proyectos de Procesamiento de Lenguaje Natural
Descripción general
Esta publicación se divide en 3 partes; son:
- ¿Qué Son Las Incrustaciones De Palabras?
- Algoritmos de Incrustación de Palabras
- Utilizando Incrustaciones de Palabras
¿Necesita ayuda con el Aprendizaje Profundo para Datos de Texto?
Toma mi curso intensivo de correo electrónico gratuito de 7 días ahora (con código).
Haga clic para inscribirse y también obtenga una versión gratuita en PDF del curso.
Comience Su Curso Intensivo GRATUITO Ahora
¿Qué Son Las Incrustaciones De Palabras?
Una incrustación de palabras es una representación aprendida para texto donde las palabras que tienen el mismo significado tienen una representación similar.
Este enfoque para representar palabras y documentos puede considerarse uno de los avances clave del aprendizaje profundo en los desafiantes problemas de procesamiento del lenguaje natural.
Uno de los beneficios de usar vectores densos y de baja dimensión es computacional: la mayoría de los kits de herramientas de redes neuronales no funcionan bien con vectores dispersos de dimensiones muy altas. The El principal beneficio de las representaciones densas es el poder de generalización: si creemos que algunas características pueden proporcionar pistas similares, vale la pena proporcionar una representación que sea capaz de capturar estas similitudes.
— Página 92, Métodos de Redes Neuronales en el Procesamiento del Lenguaje Natural, 2017.
Las incrustaciones de palabras son, de hecho, una clase de técnicas en las que las palabras individuales se representan como vectores de valor real en un espacio vectorial predefinido. Cada palabra se asigna a un vector y los valores vectoriales se aprenden de una manera que se asemeja a una red neuronal, por lo que la técnica a menudo se agrupa en el campo del aprendizaje profundo.
La clave del enfoque es la idea de usar una representación distribuida densa para cada palabra.
Cada palabra está representada por un vector de valor real, a menudo decenas o cientos de dimensiones. Esto contrasta con los miles o millones de dimensiones que se requieren para las representaciones de palabras dispersas, como una codificación en caliente.
asociado con cada palabra en el vocabulario distribuida característica palabra vector … La función vectorial que representa diferentes aspectos de la palabra: cada palabra está asociada con un punto en un espacio vectorial. El número de características is es mucho menor que el tamaño del vocabulario
— A Neural Probabilistic Language Model, 2003.
La representación distribuida se aprende en función del uso de palabras. Esto permite que las palabras que se usan de formas similares tengan representaciones similares, capturando naturalmente su significado. Esto se puede contrastar con el modelo de representación nítida pero frágil en una bolsa de palabras donde, a menos que se maneje explícitamente, diferentes palabras tienen diferentes representaciones, independientemente de cómo se usen.
Hay una teoría lingüística más profunda detrás del enfoque, a saber, la «hipótesis de distribución» de Zellig Harris que podría resumirse como: las palabras que tienen un contexto similar tendrán significados similares. Para más profundidad, véase el artículo de Harris de 1956 «Distributional structure».
Esta noción de dejar que el uso de la palabra defina su significado se puede resumir en un chiste a menudo repetido de John Firth:
¡Conocerás una palabra por la compañía que mantiene!
— Página 11, «A synopsis of linguistic theory 1930-1955», en Studies in Linguistic Analysis 1930-1955, 1962.
Algoritmos de incrustación de palabras
Métodos de incrustación de palabras aprenda una representación vectorial de valor real para un vocabulario predefinido de tamaño fijo a partir de un corpus de texto.
El proceso de aprendizaje es conjunto con el modelo de red neuronal en alguna tarea, como la clasificación de documentos, o es un proceso no supervisado, utilizando estadísticas de documentos.
Esta sección revisa tres técnicas que se pueden usar para aprender a incrustar una palabra a partir de datos de texto.
Capa de incrustación
Una capa de incrustación, a falta de un nombre mejor, es una incrustación de palabras que se aprende conjuntamente con un modelo de red neuronal en una tarea de procesamiento de lenguaje natural específica, como modelado de lenguaje o clasificación de documentos.
Requiere que el texto del documento se limpie y prepare de manera que cada palabra esté codificada en caliente. El tamaño del espacio vectorial se especifica como parte del modelo, como 50, 100 o 300 dimensiones. Los vectores se inicializan con números aleatorios pequeños. La capa de incrustación se utiliza en la parte frontal de una red neuronal y se ajusta de forma supervisada utilizando el algoritmo de Backpropagación.
… cuando la entrada a una red neuronal contiene características categóricas simbólicas (p. ej. características que toman uno de los símbolos distintos de k, como palabras de un vocabulario cerrado), es común asociar cada valor de característica posible (es decir, cada palabra en el vocabulario) con un vector dimensional d para algunos d. Estos vectores se consideran parámetros del modelo, y se entrenan conjuntamente con los otros parámetros.
— Página 49, Métodos de Redes Neuronales en el Procesamiento del Lenguaje Natural, 2017.
Las palabras codificadas en caliente se asignan a los vectores de palabras. Si se utiliza un modelo Perceptrón multicapa, los vectores de palabras se concatenan antes de ser alimentados como entrada al modelo. Si se utiliza una red neuronal recurrente, entonces cada palabra puede tomarse como una entrada en una secuencia.
Este enfoque de aprendizaje de una capa de incrustación requiere una gran cantidad de datos de entrenamiento y puede ser lento, pero aprenderá una incrustación dirigida tanto a los datos de texto específicos como a la tarea de PNL.
Word2Vec
Word2Vec es un método estadístico para aprender de manera eficiente una incrustación de palabras independiente de un corpus de texto.
Fue desarrollado por Tomas Mikolov, et al. en Google en 2013 como respuesta para hacer que el entrenamiento basado en redes neuronales de la incrustación sea más eficiente y, desde entonces, se ha convertido en el estándar de facto para desarrollar incrustaciones de palabras preentrenadas.
Además, el trabajo incluyó el análisis de los vectores aprendidos y la exploración de la matemática vectorial en las representaciones de palabras. Por ejemplo, que restar la «condición de hombre» de » Rey «y agregar» condición de mujer «resulta en la palabra» Reina», capturando la analogía»el rey es a la reina como el hombre es a la mujer».
Encontramos que estas representaciones son sorprendentemente buenas para capturar regularidades sintácticas y semánticas en el lenguaje, y que cada relación se caracteriza por un desplazamiento vectorial específico de la relación. Esto permite un razonamiento orientado a vectores basado en las compensaciones entre palabras. Por ejemplo, la relación hombre/mujer se aprende automáticamente, y con las representaciones vectoriales inducidas, » Rey-Hombre + Mujer «resulta en un vector muy cercano a «Reina».»
— Regularidades Lingüísticas en Representaciones de Palabras Espaciales Continuas, 2013.
Se introdujeron dos modelos de aprendizaje diferentes que se pueden usar como parte del enfoque word2vec para aprender la incrustación de palabras; son:
- Bolsa de palabras continua, o modelo CBOW.
- Modelo Continuo de Saltos de Gramo.
El modelo CBOW aprende la incrustación prediciendo la palabra actual en función de su contexto. El modelo continuo de saltos de gramo aprende prediciendo las palabras circundantes dadas a una palabra actual.
El modelo continuo de saltos de gramo aprende prediciendo las palabras circundantes dadas una palabra actual.
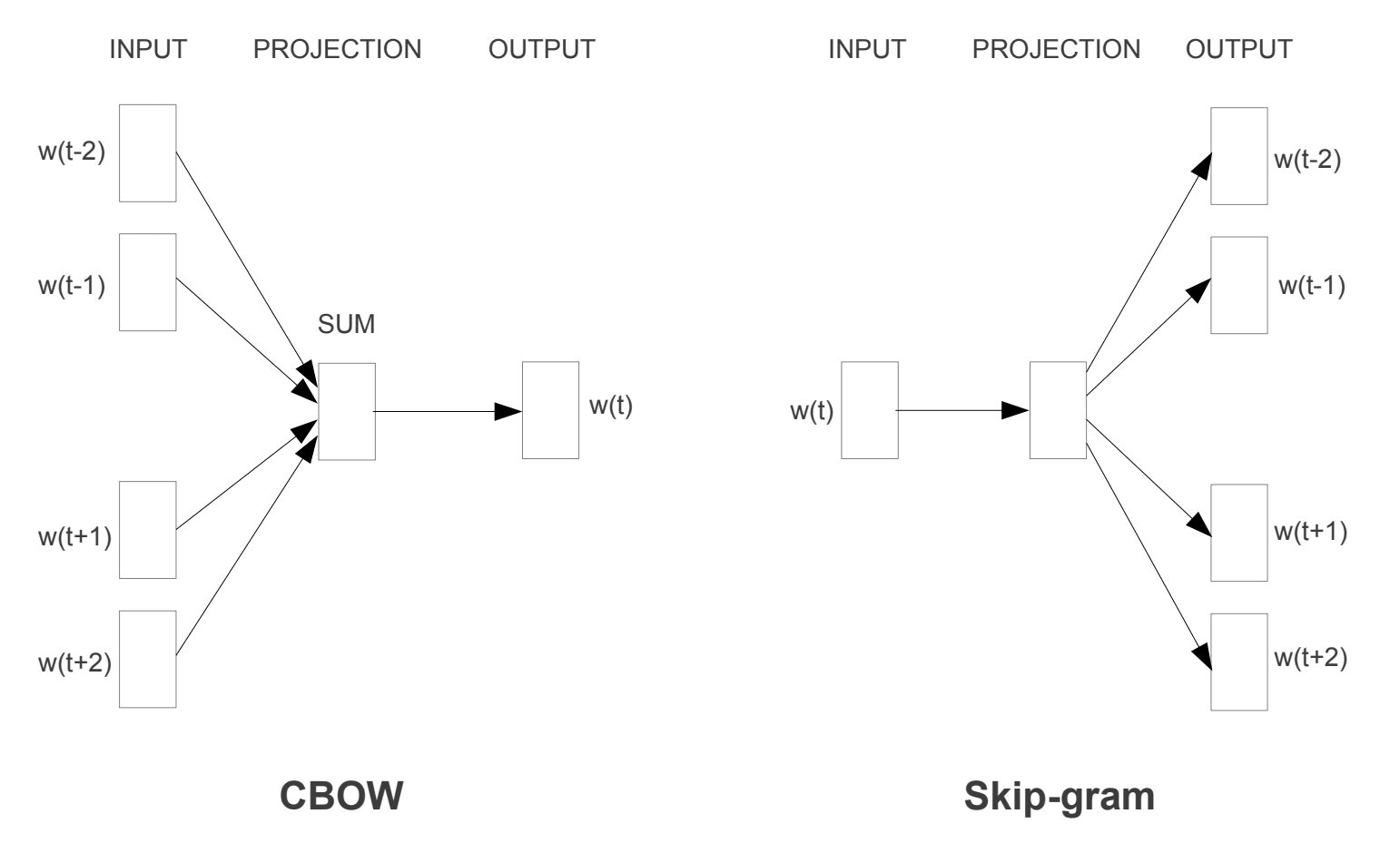
Modelos de Entrenamiento de Word2Vec
Tomados de «Estimación Eficiente de Representaciones de Palabras en el Espacio Vectorial», 2013
Ambos modelos se centran en aprender sobre las palabras dado su contexto de uso local, donde el contexto se define por una ventana de palabras vecinas. Esta ventana es un parámetro configurable del modelo.
El tamaño de la ventana deslizante tiene un fuerte efecto en las similitudes de vectores resultantes. Las ventanas grandes tienden a producir similitudes más tópicas , mientras que las ventanas más pequeñas tienden a producir similitudes más funcionales y sintácticas.
— Página 128, Métodos de Redes Neuronales en el Procesamiento del Lenguaje Natural, 2017.
El beneficio clave del enfoque es que las incrustaciones de palabras de alta calidad se pueden aprender de manera eficiente (baja complejidad de espacio y tiempo), lo que permite aprender incrustaciones más grandes (más dimensiones) de corpus de texto mucho más grandes (miles de millones de palabras).
GloVe
El algoritmo de Vectores Globales para Representación de palabras, o GloVe, es una extensión del método word2vec para el aprendizaje eficiente de vectores de palabras, desarrollado por Pennington, et al. en Stanford.
Las representaciones de palabras del modelo de espacio vectorial clásico se desarrollaron utilizando técnicas de factorización matricial, como el Análisis Semántico Latente (LSA), que hacen un buen trabajo al usar estadísticas de texto globales, pero no son tan buenas como los métodos aprendidos, como word2vec, para capturar el significado y demostrarlo en tareas como calcular analogías (p. ej. el ejemplo de Rey y Reina de arriba).
GloVe es un enfoque para combinar las estadísticas globales de las técnicas de factorización de matrices como LSA con el aprendizaje basado en el contexto local en word2vec.
En lugar de usar una ventana para definir el contexto local, GloVe construye una matriz explícita de contexto de palabra o co-ocurrencia de palabras utilizando estadísticas en todo el corpus de texto. El resultado es un modelo de aprendizaje que puede resultar en incrustaciones de palabras generalmente mejores.
GloVe, es un nuevo modelo de regresión log-bilineal global para el aprendizaje no supervisado de representaciones de palabras que supera a otros modelos de analogía de palabras, similitud de palabras y tareas de reconocimiento de entidades nombradas.
— Guante: Vectores Globales para Representación de Palabras, 2014.
Usar incrustaciones de Word
Tiene algunas opciones a la hora de usar incrustaciones de word en su proyecto de procesamiento de lenguaje natural.
Esta sección describe esas opciones.
Aprender una incrustación
Puede elegir aprender una incrustación de palabras para su problema.
Esto requerirá una gran cantidad de datos de texto para garantizar que se aprendan incrustaciones útiles, como millones o miles de millones de palabras.
Tiene dos opciones principales al entrenar la incrustación de palabras:
- Aprenda de forma independiente, donde se entrena a un modelo para aprender la incrustación, que se guarda y se usa como parte de otro modelo para su tarea más adelante. Este es un buen enfoque si desea utilizar la misma incrustación en varios modelos.
- Aprender de forma conjunta, donde la incrustación se aprende como parte de un modelo grande para tareas específicas. Este es un buen enfoque si solo tiene la intención de usar la incrustación en una tarea.
Reutilizar una incrustación
Es común que los investigadores hagan disponibles incrustaciones de palabras pre-entrenadas de forma gratuita, a menudo bajo una licencia permisiva para que pueda usarlas en sus propios proyectos académicos o comerciales.
Por ejemplo, tanto word2vec como GloVe word embeddings están disponibles para descarga gratuita.
Se pueden usar en su proyecto en lugar de entrenar sus propias incrustaciones desde cero.
Tiene dos opciones principales cuando se trata de usar incrustaciones preentrenadas:
- Estático, donde la incrustación se mantiene estática y se usa como componente de su modelo. Este es un enfoque adecuado si la incrustación es una buena opción para su problema y da buenos resultados.
- Actualizado, donde la incrustación preentrenada se utiliza para sembrar el modelo, pero la incrustación se actualiza conjuntamente durante el entrenamiento del modelo. Esta puede ser una buena opción si está buscando aprovechar al máximo el modelo y la incrustación en su tarea.
¿Qué Opción Debe Usar?
Explore las diferentes opciones y, si es posible, pruebe para ver cuál da los mejores resultados en su problema.
Quizás comience con métodos rápidos, como usar una incrustación preentrenada, y solo use una nueva incrustación si resulta en un mejor rendimiento en su problema.
Tutoriales de incrustación de palabras
Esta sección enumera algunos tutoriales paso a paso que puede seguir para usar incrustaciones de palabras y llevar la incrustación de palabras a su proyecto.
- Cómo desarrollar Incrustaciones de palabras en Python con Gensim
- Cómo Usar Capas de Incrustación de palabras para Aprendizaje profundo con Keras
- Cómo Desarrollar una CNN Profunda para el Análisis de Sentimientos (Clasificación de Texto)
Esta sección proporciona más recursos sobre el tema si está buscando profundizar más.
Artículos
- Incrustación de palabras en Wikipedia
- Word2vec en Wikipedia
- GloVe en Wikipedia
- Descripción general de incrustaciones de palabras y su conexión con modelos semánticos distributivos, 2016.
- Aprendizaje profundo, PNL y representaciones, 2014.
Papeles
- Estructura de distribución, 1956.
- Un Modelo de Lenguaje Probabilístico Neural, 2003.
- Una Arquitectura Unificada para el Procesamiento del Lenguaje Natural: Redes Neuronales Profundas con Aprendizaje Multitarea, 2008.
- Modelos de lenguaje espacial continuo, 2007.
- Estimación Eficiente de Representaciones de Palabras en el Espacio Vectorial, 2013
- Representaciones Distribuidas de Palabras y Frases y su Composicionalidad, 2013.
- Guante: Vectores Globales para Representación de Palabras, 2014.
Proyectos
- word2vec en Código de Google
- Guante: Vectores globales para Representación de Palabras
Libros
- Métodos de Redes Neuronales en Procesamiento de Lenguaje Natural, 2017.
Resumen
En esta publicación, descubriste Incrustaciones de palabras como un método de representación para texto en aplicaciones de aprendizaje profundo.
Específicamente, aprendiste:
- Qué es el enfoque de incrustación de palabras para texto de representación y en qué se diferencia de otros métodos de extracción de características.
- Que hay 3 algoritmos principales para aprender la incrustación de una palabra a partir de datos de texto.
- Que puede entrenar una nueva incrustación o usar una incrustación preentrenada en su tarea de procesamiento de lenguaje natural.
¿tiene alguna pregunta?
Haga sus preguntas en los comentarios a continuación y haré todo lo posible para responder.
¡Desarrolle modelos de Aprendizaje Profundo para Datos de Texto Hoy mismo!

Desarrolle sus Propios modelos de texto en Minutos
…con solo unas pocas líneas de código python
Descubra cómo en mi nuevo libro electrónico:
Aprendizaje Profundo para Procesamiento de lenguaje natural
Proporciona tutoriales de autoaprendizaje sobre temas como:
Bolsa de Palabras, Incrustación de palabras, Modelos de Lenguaje, Generación de subtítulos, Traducción de texto y mucho más…
Finalmente, lleve el Aprendizaje Profundo a sus Proyectos de Procesamiento de Lenguaje Natural
Omita los aspectos Académicos. Sólo Resultados.
Ver Lo que hay Dentro