En tant que data scientist dans l’industrie de la consommation, ce que je pense généralement, c’est que les algorithmes de stimulation suffisent amplement pour la plupart des tâches d’apprentissage prédictif, du moins maintenant. Ils sont puissants, flexibles et peuvent être bien interprétés avec quelques astuces. Ainsi, je pense qu’il est nécessaire de lire certains matériaux et d’écrire quelque chose sur les algorithmes de stimulation.
La majeure partie du contenu de cette acticle est basée sur l’article: Boosting d’arbre Avec XGBoost: Pourquoi XGBoost Gagne-t-il « Toutes » les compétitions d’Apprentissage Automatique?. C’est un document très instructif. Presque tout ce qui concerne les algorithmes de stimulation est expliqué très clairement dans le document. Le document contient donc 110 pages: (
Pour moi, je vais essentiellement me concentrer sur les trois algorithmes de stimulation les plus populaires: AdaBoost, GBM et XGBoost. J’ai divisé le contenu en deux parties. Le premier article (celui-ci) se concentrera sur l’algorithme AdaBoost, et le second portera sur la comparaison entre GBM et XGBoost.
AdaBoost, abréviation de « Adaptive Boosting », est le premier algorithme de boosting pratique proposé par Freund et Schapire en 1996. Il se concentre sur les problèmes de classification et vise à convertir un ensemble de classificateurs faibles en un classificateur fort. L’équation finale pour la classification peut être représentée comme suit
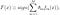
où f_m représente le m_ème classificateur faible et theta_m est le poids correspondant. C’est exactement la combinaison pondérée de M classificateurs faibles. L’ensemble de la procédure de l’algorithme AdaBoost peut être résumé comme suit.
Algorithme AdaBoost
Étant donné un ensemble de données contenant n points, où

Ici -1 désigne la classe négative tandis que 1 représente la classe positive.
Initialisez le poids de chaque point de données comme suit:

Pour l’itération m = 1,…, M:
(1) Ajustez les classificateurs faibles à l’ensemble de données et sélectionnez celui avec l’erreur de classification pondérée la plus faible:

(2) Calculer le poids pour le m_th classificateur faible:

Pour tout classificateur avec une précision supérieure à 50%, le poids est positif. Plus le classificateur est précis, plus le poids est important. Alors que pour le classificateur avec une précision inférieure à 50%, le poids est négatif. Cela signifie que nous combinons sa prédiction en retournant le signe. Par exemple, nous pouvons transformer un classificateur avec une précision de 40% en une précision de 60% en retournant le signe de la prédiction. Ainsi, même le classificateur fonctionne moins bien que les devinettes aléatoires, il contribue toujours à la prédiction finale. Nous ne voulons seulement aucun classificateur avec une précision exacte de 50%, qui n’ajoute aucune information et ne contribue donc rien à la prédiction finale.
(3) Mettez à jour le poids de chaque point de données comme suit:

où Z_m est un facteur de normalisation qui garantit que la somme de tous les poids d’instance est égale à 1.
Si un cas mal classé provient d’un classificateur pondéré positif, le terme « exp » dans le numérateur serait toujours supérieur à 1 (y * f est toujours -1, theta_m est positif). Ainsi, les cas mal classés seraient mis à jour avec des poids plus importants après une itération. La même logique s’applique aux classificateurs pondérés négatifs. La seule différence est que les classifications correctes d’origine deviendraient des classifications erronées après avoir retourné le signe.
Après M itération, nous pouvons obtenir la prédiction finale en additionnant la prédiction pondérée de chaque classificateur.
AdaBoost en tant que Modèle Additif par étapes
Cette partie est basée sur un article: Régression logistique additive: une vue statistique de l’amplification. Pour des informations plus détaillées, veuillez vous référer au document original.
En 2000, Friedman et al. développement d’une vue statistique de l’algorithme AdaBoost. Ils ont interprété AdaBoost comme des procédures d’estimation par étapes pour l’ajustement d’un modèle de régression logistique additive. Ils ont montré qu’AdaBoost minimisait en fait la fonction de perte exponentielle

Il est minimisé à

Comme pour AdaBoost, y ne peut être que de -1 ou 1, la fonction de perte peut être réécrite comme

Continuez à résoudre pour F(x), nous obtenons

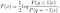
Nous pouvons en outre dériver le modèle logistique normal de la solution optimale de F(x):

Il est presque identique au modèle de régression logistique malgré un facteur 2.
Supposons que nous ayons une estimation actuelle de F(x) et essayons de rechercher une estimation améliorée F(x) + cf(x). Pour c et x fixes, nous pouvons étendre L(y, F(x) + cf(x)) au second ordre à propos de f(x)=0,

Ainsi,

où E_w(./x) indique une attente conditionnelle pondérée et le poids pour chaque point de données est calculé comme suit

Si c > 0, minimiser l’attente conditionnelle pondérée est égal à maximiser

Puisque y ne peut être que 1 ou -1, l’attente pondérée peut être réécrite comme suit

La solution optimale se présente comme suit

Après détermination de f(x), le poids c peut être calculé en minimisant directement L(y, F(x) + cf(x)):

En résolvant pour c, nous obtenons


Soit epsilon égal à la somme pondérée des cas mal classés, alors

Notez que c peut être négatif si l’apprenant faible fait pire que la supposition aléatoire (50%), dans dans ce cas, il inverse automatiquement la polarité.
En termes de poids d’instance, après l’addition améliorée, le poids d’une instance unique devient,

Ainsi, le poids de l’instance est mis à jour comme suit

Par rapport à ceux utilisés dans l’algorithme AdaBoost,

nous pouvons voir qu’ils sont sous une forme identique. Par conséquent, il est raisonnable d’interpréter AdaBoost comme un modèle additif par étapes avec une fonction de perte exponentielle, qui s’adapte itérativement à un classificateur faible pour améliorer l’estimation actuelle à chaque itération m:
