Il existe également un certain nombre de mauvaises façons d’inclure des variables. Un modèle de gravité ne fonctionnera que si chaque variable répond aux critères suivants:
- Numérique
- Complet
- Fiable
Données numériques uniquement
Comme le modèle de gravité est une équation mathématique, toutes les variables d’entrée doivent être numériques. Cela peut être un décompte (population), une mesure spatiale (superficie, distance, etc.), le temps (heures de Londres à pied), le pourcentage (augmentation / diminution des salaires), la valeur monétaire (salaires en shillings) ou une autre mesure des lieux impliqués dans le modèle.
Les nombres doivent être significatifs et ne peuvent pas être des variables catégorielles nominales qui servent de substitut à un attribut qualitatif. Par exemple, vous ne pouvez pas attribuer arbitrairement un nombre et l’utiliser dans le modèle si le nombre n’a pas de signification (par exemple, road quality = bon ou road quality = 4). Bien que ce dernier soit numérique, il ne s’agit pas d’une mesure de la qualité de la route. Au lieu de cela, vous pouvez utiliser la vitesse de déplacement moyenne en miles par heure comme indicateur de la qualité de la route. C’est à vous de déterminer et de défendre la question de savoir si la vitesse moyenne est une mesure significative de la qualité de la route en tant qu’auteur de l’étude.
D’une manière générale, si vous pouvez le mesurer ou le compter, vous pouvez le modéliser.
Données complètes seulement
Toutes les catégories de données doivent exister pour chaque point d’intérêt. Cela signifie que tous les 32 comtés analysés doivent disposer de données fiables pour chaque facteur de poussée et de traction. Vous ne pouvez pas avoir de lacunes ou de blancs, comme un comté où vous n’avez pas le salaire moyen.
Données fiables Uniquement
L’adage informatique « garbage in, garbage out » s’applique également aux modèles de gravité, qui ne sont aussi fiables que les données utilisées pour les construire. Au-delà du choix de données historiques robustes et fiables à partir de sources auxquelles vous pouvez faire confiance, il existe de nombreuses façons de commettre des erreurs qui rendront les résultats de votre modèle vides de sens. Par exemple, il vaut la peine de s’assurer que les données dont vous disposez correspondent exactement aux territoires (par exemple, les données de comté pour représenter les comtés, et non les données de ville pour représenter un comté).
Selon l’heure et le lieu de votre étude, il peut être difficile d’obtenir un ensemble de données fiables sur lesquelles fonder votre modèle. Plus on remonte dans le passé, plus cela peut être difficile. De même, il peut être plus facile de mener ce type d’analyses dans des sociétés fortement bureaucratiques qui ont laissé une bonne trace papier, comme en Europe ou en Amérique du Nord.
Pour assurer la qualité des données dans cette étude de cas, chaque variable a été calculée de manière fiable ou dérivée de données historiques publiées examinées par des pairs (voir le tableau 1). La façon exacte dont ces données ont été compilées peut être lue dans l’article original où elle a été expliquée en profondeur.11
- Nos Cinq variables de modèle
- L’ensemble de données de variables complété
- Étape 2: Détermination des pondérations
- Le Code pour calculer les pondérations
- Étape 3: Pour calculer les estimations pour chaque comté
- Étape 4 – Interprétation historique
- Faire avancer vos connaissances
- Remerciements
- Notes de fin
Nos Cinq variables de modèle
Avec les principes ci-dessus à l’esprit, nous aurions pu choisir n’importe quel nombre de variables, compte tenu de ce que nous savions des facteurs de poussée et d’attraction de migration. Nous avons opté pour cinq (5), choisis en fonction de ce que nous pensions être le plus important, et que nous savions pouvoir être sauvegardés avec des données fiables.
| Variable | Source |
|---|---|
| population at origin | 1771 values, Wrigley, « English county populations », pp. 54-5.12 |
| distance de Londres | calculée avec un logiciel |
| prix du blé | Cannon and Brunt, « Weekly British Grain Prices »13 |
| salaire moyen à l’origine | Hunt, « Industrialisation et inégalités régionales », pp. 965-6.14 |
| trajectoire des salaires | Hunt, « Industrialisation et inégalités régionales », pp. 965-6.15 |
Tableau 1: Les cinq variables utilisées dans le modèle, et la source de chacune dans la littérature évaluée par les pairs
Ayant décidé de ces variables, le co-auteur de l’étude originale, Adam Dennett, a décidé de réécrire la formule pour la rendre auto-documentée afin qu’il soit facile de dire quels bits se rapportaient à chacune de ces cinq variables. C’est pourquoi la formule ci-dessus semble différente de celle du document de recherche original. Les nouveaux symboles sont visibles dans le tableau 2 :
Deux variables supplémentairesii$ etjj$ signifient respectivement « au point d’origine » et » à Londres ». WaWa_{i} means signifie « niveaux de salaire au point d’origine » alors queWaWa_{j} mean signifierait « niveaux de salaire à Londres ». Ces sept nouveaux symboles peuvent remplacer les plus génériques de la formule:
\
Ceci est maintenant plus verbeux et une version légèrement auto-documentée de l’équation précédente. Les deux résolvent mathématiquement exactement de la même manière, car les changements sont purement superficiels et au profit d’un utilisateur humain.
L’ensemble de données de variables complété
Pour rendre le tutoriel plus rapide et plus facile à compléter, les données de chacune des 5 variables et de chacun des 32 comtés ont déjà été compilées et nettoyées, et peuvent être consultées dans le tableau 3 ou téléchargées sous forme de fichier csv. Ce tableau comprend également le nombre connu de vagabonds de ce comté, tel qu’observé dans l’enregistrement de la source primaire:
| Comté | Vagabonds | $d$ km à Londres | $P$ de la Population (personnes) | $Wa$ Salaire Moyen (shillings) | $WaT$ Salaire Trajectoire 1767-95 (variation en%) | $Wh$ du Prix du Blé (shillings) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Saint-Jean-de-Luz | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornouailles | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Saint-Jean-de-Luz | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Comté de Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Saint-Jean-de-Luz | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Lagrange | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Saint-Jean-de-Luz | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Saint-Jean-de-Luz | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Saint-Jean-de-Luz | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
La dernière différence entre cette formule et celle utilisée dans l’article original est que deux des variables ont une relation plus forte avec le vagabondage lorsqu’elles sont tracées naturellement logarithmiquement. Il s’agit de la population à l’origine ($P$) et de la distance entre l’origine et Londres (dd$). Cela signifie que pour les données de cette étude, la ligne de régression (parfois appelée ligne de meilleur ajustement) est un meilleur ajustement lorsque les données ont été enregistrées que lorsqu’elles ne l’ont pas été. Vous pouvez le voir dans la figure 7, avec les chiffres de population non enregistrés à gauche et la version enregistrée à droite. Plus de points sont plus proches de la ligne de meilleur ajustement sur le graphique enregistré que sur le graphique non enregistré.
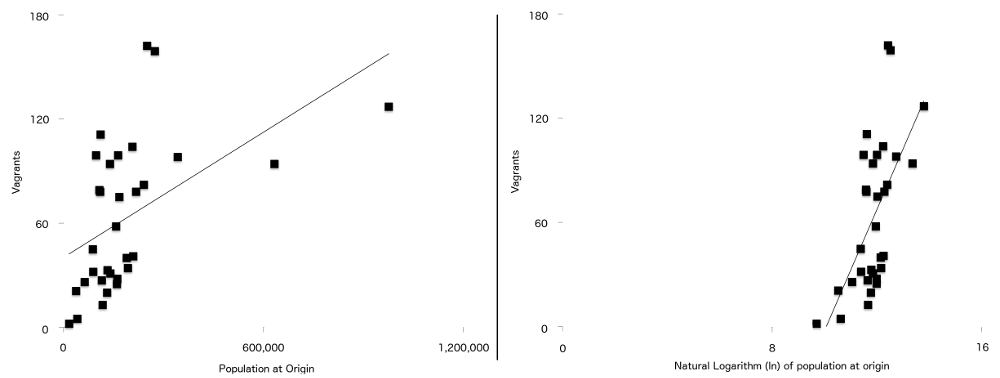
Figure 7: Nombre de Vagabonds par rapport à la population d’origine (à gauche) et journal naturel de la population d’origine (à droite) avec une ligne de régression simple superposée sur les deux. Notez la relation plus forte entre les deux variables visibles sur le deuxième graphique.
Comme c’est le cas avec ces données particulières (vos propres données dans un type d’étude similaire peuvent ne pas suivre ce modèle), la formule a été ajustée pour utiliser les versions enregistrées naturellement de ces deux variables, ce qui a donné la formule finale utilisée dans le modèle de gravité (figure 8). Nous n’aurions pu connaître la nécessité de cet ajustement qu’après avoir collecté nos données variables:
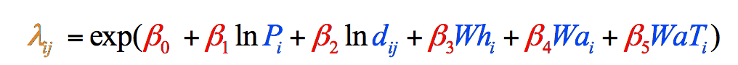
Figure 8 : La formule finale du modèle de gravité ventilée par étapes et codée par couleur. Les éléments en noir sont des opérations mathématiques. Les éléments en bleu représentent nos variables, que nous venons de rassembler (étape 1). Les éléments en rouge représentent les pondérations de chaque variable, que nous devons calculer (Étape 2), et l’élément en orange est l’estimation finale des vagabonds de ce comté, que nous pouvons calculer une fois que nous avons les autres informations (Étape 3).
Les valeurs du tableau 3 nous donnent tout ce dont nous avons besoin pour remplir les parties bleues de chaque équation de la figure 8. Nous pouvons maintenant porter notre attention sur les parties rouges, qui nous indiquent l’importance de chaque variable dans l’ensemble du modèle et nous donnent les chiffres dont nous avons besoin pour compléter l’équation.
Étape 2: Détermination des pondérations
Les pondérations de chaque variable nous indiquent l’importance de ce facteur de poussée / traction par rapport aux autres variables lorsque vous essayez d’estimer le nombre de vagabonds qui auraient dû provenir d’un comté donné. Les paramètresββ$ doivent être déterminés sur l’ensemble de l’ensemble des données à partir des données connues. Avec ceux-ci à portée de main, nous serons en mesure de comparer les observations individuelles spécifiques à l’origine avec le modèle général. Nous pouvons ensuite les examiner et identifier des flux sur et sous-prévus entre les différentes origines et la destination.
À ce stade, nous ne savons pas à quel point chacun est important. Peut-être que le prix du blé est un meilleur prédicteur de la migration que la distance? Nous ne le saurons pas tant que nous n’aurons pas calculé les valeurs deββ1 through àββ5$ (les pondérations) en résolvant l’équation ci-dessus. L’ordonnée à l’origine ($β0$) ne peut être calculée qu’une fois que vous connaissez toutes les autres (ββ1-β5$). Ce sont les valeurs ROUGES de la figure 8 ci-dessus. Les pondérations sont visibles dans le tableau 4 et dans le tableau A1 du papier original.16 Nous allons maintenant montrer comment nous en sommes arrivés à ces valeurs.
Calculer ces valeurs à long terme nécessite une quantité incroyable de travail. Nous utiliserons une solution rapide dans le langage de programmation R qui tire parti du package de MASSE de William Venables et Brian Ripley qui peut résoudre des équations de régression binomiale négatives comme notre modèle de gravité avec une seule ligne de code. Cependant, il est important de comprendre les principes qui sous-tendent ce que l’on fait afin d’apprécier ce que fait le code (notez que les sections suivantes ne font pas le calcul, mais expliquent ses étapes pour vous; nous ferons le calcul avec le code plus bas sur la page).
Calculer les poids Individuels (en Principe)
$β_{1}$, $β_{2}$, etc, sont les mêmes que $ß$ dans le Simple modèle de Régression Linéaire ci-dessus, qui est la pente de la droite de régression (la hausse au cours de l’exécution, ou combien de $y$ augmente lorsque $x$ augmente de 1). La seule différence ici entre une Simple Régression linéaire et notre modèle de gravité est que nous devons calculer 5 pentes au lieu de 1.
Une régression Linéaire simple \(y = α + ßx\)
Nous devrons résoudre pour chacune de ces cinq pentes avant de pouvoir calculer l’ordonnée à l’origine à l’étape suivante. En effet, les pentes des différentes valeursββ$ font partie de l’équation de calcul de l’ordonnée à l’origine.
La formule de calcul deββ$ dans une analyse de régression est:
\
Coefficient de corrélation de Pearson
Le coefficient de corrélation de Pearson peut être calculé à longue main mais c’est un calcul assez long dans ce cas, nécessitant 64 nombres. Il existe d’excellents didacticiels vidéo en anglais disponibles en ligne si vous souhaitez voir comment faire les calculs à long terme.17 Il existe également un certain nombre de calculatrices en ligne qui calculerontrr for pour vous si vous fournissez les données. Compte tenu du grand nombre de chiffres à calculer, je recommanderais un site Web avec un outil intégré conçu pour effectuer ce calcul. Assurez-vous de choisir un site réputé, comme celui offert par une université.
Calculer $s_{y}
L’écart-type est un moyen d’exprimer la variation de la moyenne (moyenne) dans les données. En d’autres termes, les données sont-elles assez regroupées autour de la moyenne ou la propagation est-elle beaucoup plus large?
Encore une fois, il existe des calculatrices en ligne et des logiciels statistiques qui peuvent effectuer ce calcul pour vous si vous fournissez les données.
Calcul deββ_{0}$ (l’ordonnée à l’origine)
Ensuite, nous devons calculer l’ordonnée à l’origine. La formule pour calculer l’ordonnée à l’origine dans une régression linéaire simple est la suivante:
\
Cependant, le calcul devient beaucoup plus compliqué dans une analyse de régression multiple, car chaque variable influence le calcul. Cela rend le travail manuel très difficile, et c’est l’une des raisons pour lesquelles nous optons pour une solution programmatique.
Le Code pour calculer les pondérations
Le paquet statistique de MASSE, écrit pour le langage de programmation R, a une fonction qui peut résoudre des équations de régression binomiale négatives, ce qui rend très facile le calcul de ce qui serait autrement une formule longue main très difficile.
Cette section suppose que vous avez installé R et que vous avez installé le paquet de MASSE. Si vous ne l’avez pas fait, vous devrez le faire avant de continuer. Le tutoriel de Taryn Dewar sur les bases de R avec des données tabulaires comprend des instructions d’installation de R.
Pour utiliser ce code, vous devrez télécharger une copie de l’ensemble de données des cinq variables plus le nombre de vagabonds observés dans chacun des 32 comtés. Ceci est disponible ci-dessus en tant que tableau 3, ou peut être téléchargé en tant que a.fichier CSV. Quel que soit le mode que vous choisissez, enregistrez le fichier sous VagrantsExampleData.csv. Si vous utilisez un Mac, assurez-vous de l’enregistrer au format Windows.fichier CSV. Ouvrez les échantillons de vagabonds.csv et familiarisez-vous avec son contenu. Vous devriez remarquer chacun des 32 comtés, ainsi que chacune des variables dont nous avons discuté tout au long de ce tutoriel. Nous utiliserons les en-têtes de colonne pour accéder à ces données avec notre programme informatique. J’aurais pu les appeler n’importe quoi, mais dans ce fichier, ils sont:
vagrantspopulationdistancewheatwageswageTrajectory
Dans le même répertoire que vous avez enregistré le fichier csv, créez et enregistrez un nouveau fichier de script R (vous pouvez le faire avec n’importe quel éditeur de texte ou avec RStudio, mais n’utilisez pas de traitement de texte comme MS Word). Enregistrez-le sous forme de calculs de pondération.r.
Nous allons maintenant écrire un programme court qui:
- Installe le paquet de MASSE
- Appelle le paquet de MASSE afin que nous puissions l’utiliser dans notre code
- Stocke le contenu du.un fichier csv vers une variable que nous pouvons utiliser par programme
- Résout l’équation du modèle de gravité à l’aide de l’ensemble de données
- Produit les résultats du calcul.
Chacune de ces tâches sera réalisée à tour de rôle avec une seule ligne de code
Copiez le code ci-dessus dans vos calculs de pondération.r fichier et enregistrer. Vous pouvez maintenant exécuter le code en utilisant votre environnement R préféré (j’utilise RStudio) et les résultats du calcul devraient apparaître dans la fenêtre de la console (ce à quoi cela ressemble dépendra de votre environnement). Vous devrez peut-être définir le répertoire de travail de votre environnement R sur le répertoire contenant votre.csv et.fichiers r. Si vous utilisez RStudio, vous pouvez le faire via les menus (Session -> Définir le répertoire de travail – > Choisir le répertoire). Vous pouvez également réaliser la même chose avec la commande:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundNotez que la ligne 4 est la ligne qui résout l’équation pour nous, en utilisant le glm.fonction nb, qui est l’abréviation de « modèle linéaire généralisé – binôme négatif ». Cette ligne nécessite un certain nombre d’entrées:
- nos variables utilisant les en-têtes de colonne comme écrit dans le.fichier csv, ainsi que toute journalisation qui doit leur être faite (
vagrants, log(population), log(distance),wheat,wages,wageTrajectory). Si vous exécutiez un modèle avec vos propres données, vous les ajusteriez pour refléter vos en-têtes de colonne dans votre ensemble de données. - où le code peut trouver les données – dans ce cas une variable que nous avons définie à la ligne 3 appelée
gravityModelData.
Les sorties du calcul peuvent être vues sur la figure 9:
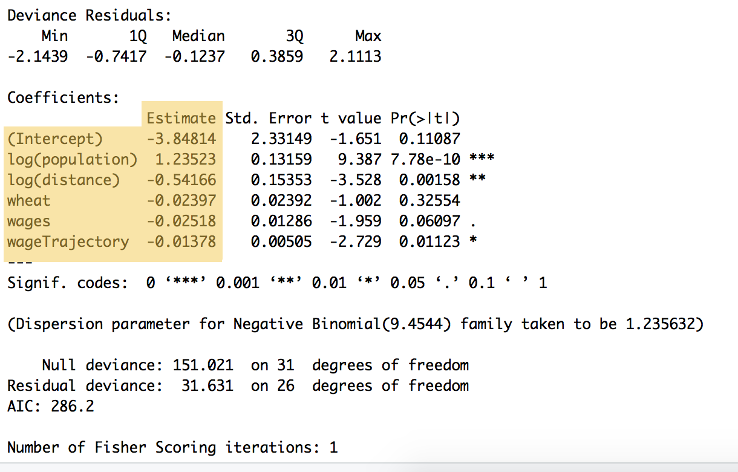
Figure 9: Le résumé du code ci-dessus, montrant les pondérations pour chaque variable et l’ordonnée à l’origine, répertoriées sous la rubrique ‘Estimation’ ($\beta_{0} to à to\beta_{5}$. Ce résumé montre également un certain nombre d’autres calculs, y compris la signification statistique.
Étape 3: Pour calculer les estimations pour chaque comté
, nous devons le faire une fois pour chacun des 32 comtés.
Vous pouvez le faire avec une calculatrice scientifique, en créant une formule de feuille de calcul ou en écrivant un programme informatique. Pour ce faire automatiquement dans R, vous pouvez ajouter ce qui suit à votre code et relancer le programme. Cette boucle for calcule le nombre attendu de vagabonds de chacun des 32 comtés de l’exemple et imprime les résultats pour que vous puissiez les voir:
Pour mieux comprendre, je suggère de faire un comté à la main. Ce tutoriel utilisera le Hertfordshire comme exemple à long terme (mais le processus est exactement le même pour les 31 autres comtés).
En utilisant les données pour le Hertfordshire dans le tableau 3, et les pondérations pour chaque variable dans le tableau 4, nous pouvons maintenant compléter notre formule, qui donnera le résultat de 95:
Tout d’abord, échangeons les symboles contre les nombres, tirés des tableaux mentionnés ci-dessus.
Ensuite, commencez à calculer les valeurs pour arriver à l’estimation. Se souvenir de l’ordre mathématique des opérations, multipliez les valeurs avant d’ajouter. Commencez donc par calculer chaque variable (vous pouvez utiliser une calculatrice scientifique pour cela):
L’étape suivante consiste à additionner les nombres ensemble:
estimated vagrants = exp(4.56232408897)Et enfin, pour calculer la fonction exponentielle (utilisez une calculatrice scientifique):
estimated vagrants = 95.8059926832Nous avons laissé tomber le reste et déclaré que le nombre estimé de vagabonds du Hertfordshire dans ce modèle est de 95. Vous devez effectuer les mêmes calculs pour chacun des autres comtés, que vous pouvez accélérer en utilisant un tableur. Juste pour vous assurer que vous pouvez le refaire, j’ai également inclus les chiffres pour le Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
Je recommande de choisir un autre comté et de le calculer à long terme avant de continuer, pour m’assurer que vous pouvez faire les calculs par vous-même. La bonne réponse est disponible dans le tableau 5, qui compare les valeurs observées (telles que vues dans l’enregistrement de la source primaire) aux valeurs estimées (telles que calculées par notre modèle de gravité). Le « résiduel » est la différence entre les deux, avec une grande différence suggérant un nombre inattendu de vagabonds qui pourraient valoir la peine d’être examinés de plus près avec son chapeau d’historien.
| Comté | Valeur observée | Valeur estimée | Résiduelle |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Saint-Jean-de-Luz | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornouailles | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Comté de Leicestershire | 20 | 28 | -8 |
| Saint-Jean-de-Luz | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Lagrange | 2 | 4 | -2 |
| Saint-Jean-de-Luz | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Warwickshire | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Saint-Jean-de-Luz | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Étape 4 – Interprétation historique
À ce stade, le processus de modélisation est terminé et la dernière étape est l’interprétation historique.
L’article original publié sur lequel cette étude de cas a été fondée est principalement consacré à l’interprétation de ce que les résultats de la modélisation signifient pour notre compréhension de la migration des classes inférieures au XVIIIe siècle. Comme le montre la carte de la figure 5, il y avait des régions du pays où le modèle suggérait fortement d’envoyer des migrants de classe inférieure à Londres ou de les envoyer en sous-quantité.
Les coauteurs ont offert leurs interprétations quant à la raison pour laquelle ces modèles ont pu apparaître. Ces interprétations variaient selon les lieux. Dans les régions du nord de l’Angleterre qui s’industrialisaient rapidement, comme le Yorkshire ou Manchester, les opportunités locales semblaient donner aux gens moins de raisons de partir, entraînant une migration plus faible que prévu vers Londres. Dans les régions en déclin à l’ouest, comme Bristol, l’attrait de Londres était plus fort alors que de plus en plus de gens partaient chercher du travail dans la capitale.
Tous les modèles n’étaient pas attendus. Le Northumberland, dans l’extrême nord-est, s’est avéré être une anomalie régionale, envoyant beaucoup plus de migrants (féminins) à Londres que ce à quoi nous nous attendions. Sans les résultats du modèle, il est peu probable que nous ayons pensé à considérer Northumberland du tout, en particulier parce qu’il était si loin de la métropole et que nous présumions avoir des liens faibles avec Londres. Le modèle a donc fourni de nouvelles preuves à considérer en tant qu’historiens et a changé notre compréhension de la relation Londres-Northumberland. Une discussion complète de nos résultats peut être lue dans l’article original.18
Faire avancer vos connaissances
Après avoir essayé cet exemple de problème, vous devez bien comprendre comment utiliser cet exemple de formule, ainsi que si un modèle de gravité peut être une solution appropriée à votre problème de recherche. Vous avez l’expérience et le vocabulaire nécessaires pour aborder et discuter des modèles de gravité avec un collaborateur compétent en mathématiques si nécessaire, qui peut vous aider à l’adapter à votre propre étude de cas.
Si vous avez la chance d’avoir également des données sur les migrants qui déménagent à Londres à la fin du XVIIIe siècle et que vous souhaitez les modéliser en utilisant les cinq mêmes variables énumérées ci-dessus, cette formule fonctionnerait telle quelle – il y a une étude facile ici pour quelqu’un avec les bonnes données. Cependant, ce modèle ne fonctionne pas seulement pour les études sur les migrants qui s’installent à Londres. Les variables peuvent changer et la destination n’a pas besoin d’être Londres. Il serait possible d’utiliser un modèle de gravité pour étudier la migration vers la Rome antique, ou Bangkok du XXIe siècle, si vous avez les données et la question de recherche. Il n’a même pas besoin d’être un modèle de migration. Pour utiliser l’étude de cas sur le café colombien de l’introduction, qui se concentre sur le commerce plutôt que sur la migration, le tableau 6 montre une utilisation viable de la même formule, inchangée.
| Critères | Exemple d’exportation de café |
|---|---|
| UN point d’origine | exportations de café du port de Barranquilla, Colombie |
| Destinations multiples finies | les 21 pays de l’hémisphère occidental en 1950 |
| CINQ variables explicatives | (1) nombre de ports de l’océan Atlantique dans le pays d’accueil (2) miles de la Colombie, (3) Produit intérieur brut du pays d’accueil, (4) Café national cultivé en tonnes, (5) cafés pour 10 000 habitants |
Il existe une longue histoire de modèles de gravité dans les études universitaires. Pour en utiliser un efficacement pour la recherche, vous devez comprendre la théorie de base et les mathématiques qui les sous-tendent et les raisons pour lesquelles ils se sont développés. Il est également important de comprendre leurs limites et conditions pour les utiliser correctement, dont certaines ont été discutées ci-dessus. Cela pourrait aussi aider à savoir:
-
Un modèle de gravité comme celui utilisé dans cet exemple ne peut fonctionner que dans un système fermé. Le modèle ci-dessus n’avait que 32 points d’origine possibles, ce qui permettait d’exécuter le modèle 32 fois. Un nombre inconnu ou infiniment grand de points d’origine (ou de destinations selon votre modèle), nécessiterait une équation différente.
-
Le concept de modèle de gravité repose également sur le principe que les mouvements (migration, commerce, etc.) sont basés sur un ensemble de décisions individuelles volontaires qui peuvent être influencées par des facteurs extérieurs, mais ne sont pas entièrement contrôlées par eux. Par exemple, les migrations volontaires ou les achats effectués de libre arbitre pourraient être modélisés à l’aide de cette technique, mais les migrations forcées, les achats obligatoires ou les processus naturels tels que la migration des oiseaux ou le débit des rivières peuvent ne pas suivre les mêmes principes et, par conséquent, un type de modèle différent peut être nécessaire.
-
Les modèles de gravité peuvent être utilisés pour prédire le comportement des populations, mais pas des individus, et les tentatives de modélisation des données devraient donc inclure un grand nombre de mouvements pour assurer une signification statistique.
Il y a beaucoup d’autres pièges, mais aussi d’énormes possibilités. J’espère que cette présentation d’un modèle de gravité et les recherches publiées qui l’accompagnent rendront cet outil puissant plus accessible aux historiens. Si vous envisagez d’utiliser un modèle de gravité dans vos recherches scientifiques, l’auteur recommande fortement les articles suivants:
Remerciements
Avec des remerciements à Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas et Leanne Calvert pour avoir lu et commenté les versions antérieures de cet article. Merci également à la British Academy d’avoir financé l’atelier d’écriture à Bogotá, en Colombie, au cours duquel cet article a été rédigé. Et enfin à Adam Dennett de m’avoir présenté ces merveilleuses formules et de libérer leur potentiel pour les historiens.